 2015-08-21
2015-08-21 5549
5549Мы уже обсуждали с Вами, что компьютерное моделирование рассматривает вычислительный эксперимент как новую методологию научного исследования. В лекции 2 мы определяли метод имитационного моделирования как экспериментальный метод, предполагающий экспериментирование с помощью модели с целью получения информации о реально действующей системе. Вычислительный эксперимент здесь рассматривается как целенаправленное исследование, организованное на имитационной модели, которое позволяет получить информацию, необходимую для принятия решений.
Имитационные модели, отмечали мы там же, не расчетные, а прогонного типа. Одна реализация исследования на имитационной модели, эксперимент состоит из серии прогонов, в ходе которого осуществляется оценка функционирования системы при заданном (фиксированном) наборе условий, при определенном наборе исходных данных и управляемых параметров (здесь мы временно отвлечемся от стохастичной природы имитации и будем подразумевать детерминированный случай). Характерной чертой имитационной модели является то, что каждый машинный прогон имитационной модели дает результаты, которые действительны только при определенных значениях параметров, переменных и структурных взаимосвязей, заложенных в имитационную программу, т.е. для различных исследуемых вариантов могут изменяться параметры, переменные, операционные правила, структурные отношения, которые характеризуют определенный вариант. Цель имитационных исследований -снабжать данными при изменении входных условий.
Имитационный эксперимент, содержание которого определяется: предварительно-проведенным аналитическим исследованием (являющимся составной частью вычислительного эксперимента),
результаты которого достоверны и математически обоснованы, назовем направленным вычислительным экспериментом.
Приведенное выше определение отражает две части и основные задачи исследователя при организации и проведении вычислительного эксперимента на имитационной модели. Эти задачи включают:
Стратегическое планирование вычислительного эксперимента;
Выбор (математического) метода анализа (обработки) результатов вычислительного эксперимента.
Рассмотрим первую задачу. Проблемы стратегического планирования в имитационном исследовании мы обсуждали ранее. Стратегическое планирование вычислительного эксперимента — это организация вычислительного эксперимента, выбор метода сбора информации, который дает требуемый (для данной цели моделирования, для принятия решения) ее объем при наименьших затратах. Т.е. основная цель стратегического планирования -получить желаемую информацию для изучения моделируемой системы при минимальных затратах на экспериментирование, при наименьшем числе прогонов.
Перед началом исследования необходимо спланировать эксперимент — разработать план проведения эксперимента на модели. Цель этого планирования двоякая:
1) Планирование эксперимента позволяет выбрать конкретный метод сбора необходимой для получения обоснованных выводов информации, т.е. план задает схему исследования. Таким образом, план эксперимента служит структурной основой процесса исследования.
2) Достигнуть цели исследования эффективным образом, т.е. уменьшить число экспериментальных проверок (прогонов).
Действительно, если в процессе имитационного исследования рассматривается большое число вариантов (для каждого варианта могут меняться параметры, переменные, структурные отношения), то число прогонов растет, растут и затраты машинного времени.
Допустим, число уровней, принимаемых значений переменной всего 2. В случае 3-х двухуровневых факторов необходимо проводить прогонов N = 23 = 8, при 7 факторов требуемое число прогонов возрастает до 27 = 128.
Проблема выбора ограниченного числа прогонов может быть решена с помощью статистических методов планирования эксперимента, которые мы будем рассматривать ниже.
Вторая задача при организации и проведении направленного вычислительного эксперимента на имитационной модели: выбор метода анализа результатов. В зависимости от целей и задач вычислительного эксперимента могут применяться различные математические методы для обработки результатов эксперимента. На данном технологическом этапе имитационного моделирования, имитационная модель представляется исследователю в виде черного ящика, как показано на рисунке 7.1.
Взаимосвязь F между входом Х и выходом Y имитационной модели, должна быть промоделирована с помощью некоторой вторичной модели, отвечающей стратегическим требованиям. В простейшем случае — это может быть некоторая линейная регрессионная модель. В задачах интерполяции ищется функция F, в задачах оптимизации - экстремум функции F.
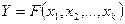
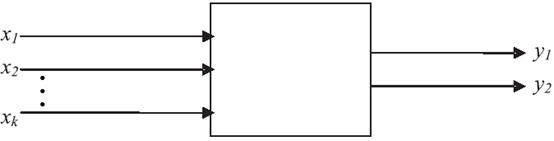
Рис. 7.1 — Представление имитационной модели в виде "черного ящика"
Выбор метода анализа результатов исследования зависит в основном от цели и характера исследования. На практике, выбор аналитического метода анализа результатов исследования (вторичной математической модели) определяется целью исследования и методом статистического анализа его результатов, необходимым для достижения этой цели.
Итак, решение основных задач рассмотренного этапа имитационного моделирования предполагает составление такого плана компьютерного эксперимента, позволяющего достигать поставленные цели эксперимента эффективным образом, с учетом ограничений на ресурсы, а также выбрать математический метод анализа (истолкования) результатов моделирования. Технологическая цепочка такого экспериментального исследования на имитационной модели представляет последовательность следующих действий: в соответствии с целью исследования осуществляется постановка математической задачи (определяется содержание направленного вычислительного эксперимента); в соответствии с поставленной задачей исследования разрабатывается план эксперимента; по плану проводится серия экспериментов, в ходе которого собирается информация (результаты экспериментов); далее в зависимости от цели эксперимента выбирается метод анализа результатов, позволяющий в конечном итоге принимать исследователю решение по результатам моделирования.
Далее мы будем изучать анонсируемые выше методы, полезные в вычислительном эксперименте на имитационной модели.
7.2 Основные цели и типы вычислительных
экспериментов в имитационном моделировании
В соответствии с наиболее употребимыми целями моделирования, рассмотренными в лекции 3, целями вычислительного эксперимента могут быть:
оценка выходных переменных функционирования сложной системы при заданных параметрах системы;
выбор на множестве альтернатив;
получение знаний о влиянии управляемых параметров на результаты эксперимента;
определение тех значений входных параметров и переменных, при которых достигается оптимальный выход (отклик).
Наиболее широко на практике распространены следующие типы вычислительных экспериментов, представленные в таблице 7.2.:
Таблица 7.2
Основные типы направленных вычислительных экспериментов
| Цели вычислительного эксперимента | Тип направленного вычислительного эксперимента | Применяемые математические модели и методы |
| 1. Оценка выходных переменных при заданных параметрах системы. 2. Сравнение альтернатив (или выбор на множестве альтернатив) | 1 тип: Оценка и сравнение средних и дисперсий различных альтернатив | Статистические методы оценивания, проверки гипотез; однофакторный дисперсионный анализ; методы множественного ранжирования и сравнения; процедуры ранжирования, отбора, эвристические приемы и др. |
| 3. Получение знаний о влиянии управляемых параметров на результаты эксперимента | 2 тип: Анализ чувствительности (задача интерполяции) | Методы планирования эксперимента, дисперсионный, регрессионный анализ; и др. |
| 4. Определение тех значений входных параметров и переменных, при которых достигается оптимальный выход | 3 тип: Поиск оптимума на множестве возможных значений переменных (задача оптимизации) | Последовательные методы планирования эксперимента (методология анализа поверхности отклика). |
| 5. Вариантный синтез | Многокритериальная оптимизация, выбор | Итерационные имитационно-оптимизационные процедуры, методы принятия решений |
1 тип: Оценка и сравнение средних и дисперсий различных альтернатив.
2 тип: Анализ чувствительности (параметрический анализ) системы к изменению параметров. Основным содержанием такого эксперимента является определение влияния управляемых параметров, переменных (факторов) на результаты экспериментов (отклик). В эксперименте 2 типа ставится математическая задача интерполяции и осуществляется построение интерполяционных формул. Например, модель F на рис.7.1.1. может быть аппроксимирована полиномиальной функцией, например некоторой линейной регрессионной моделью. В задачах интерполяции необходимо найти функцию F.
3 тип: Решается задача оптимизации: поиск оптимальных значений на некотором множестве возможных значений переменных. В задачах оптимизации необходимо найти экстремум функции F.
4 тип: Вариантный синтез, это более сложный класс вычислительных экспериментов, как правило, связанный с многокритериальной оптимизацией, реализацией итерационных имитационно-оптимизационных процедур [13], выбором и принятием решения в широком смысле слова. Рассмотрение этих методов в этой лекции мы не будем проводить.
Рассмотрим основные математические модели и методы, применяемые в первых трех типах вычислительных экспериментов и общие схемы по их организации и проведению.
Эксперименты первого типа довольно просты и обычно являются так называемыми однофакторными экспериментами, подробнее рассматриваются в разделе 7.4. Основные вопросы, встающие перед экспериментатором при их проведении, — это вопросы о размере выборки, начальных условиях, наличие или отсутствии автокорреляции и другие задачи тактического планирования машинного эксперимента, которые рассматриваются подробнее в соответствующем разделе учебника.
Основные математические методы, применяемые и рекомендуемые в этом эксперименте:
статистические методы оценивания путем использования таких величин, как среднее значение, стандартное отклонение, коэффициент корреляции др.;
процедуры проверки гипотез с использованием стандартной тестовой статистики (t, F, 2 и др.), однофакторный дисперсионный анализ; при сравнении и выборе альтернатив Клейнен [20] рекомендует статистические процедуры ранжирования (веса) и отбора: методы множественного ранжирования и методы множественного сравнения; в более сложных случаях могут быть полезны различные эвристические приемы.
Эксперименты второго типа предполагают обычно широкое использование методов планирования эксперимента, которые мы подробно будем изучать в следующем разделе учебника. Основными методами истолкования результатов этих экспериментов являются дисперсионный и регрессионный анализы. Для исследования динамических рядов (в моделях системной динамики) рекомендуется спектральный анализ.
В терминах теории планирования экспериментов вход модели называется фактором, конкретные значения фактора -уровнями, выход модели -откликом. План эксперимента определяет комбинацию уровней и для каждой комбинации задает число повторных прогонов модели. Выбирают и осуществляют план, далее, используя данные эксперимента, определяют параметры регрессионной модели.
Общая схема исследования здесь следующая:
Выбор ограниченного числа прогонов вариантов системы решается с помощью статистических методов планирования экспериментов. Используют полные и дробные факторные планы;
В ходе обработки результатов эксперимента получают параметры регрессионной модели;
Исследователь выполняет анализ модели (регрессионной зависимости).
3 тип вычислительного эксперимента, ориентированный на решение задачи оптимизации (определяются такие значения управляемых параметров и переменных, которые максимизируют или минимизируют заданную целевую функцию), предполагает использование последовательных или поисковых методы построения экспериментов. Полезно применение методологии анализа поверхности отклика, рассматриваемой в последующих разделах этой лекции, комбинирующей эти методы планирования и итерационные имитационно-оптимизационные вычислительные процедуры. Принципы оптимизации здесь те же, что и для аналитических моделей, однако выход имитационной модели содержит случайную составляющую, поэтому необходимо в вероятностной форме задавать ограничения на отклики и осуществлять статистическую интерпретацию значений целевой функции.
7.3 Основы теории планирования экспериментов.
Основные понятия: структурная, функциональная и экспериментальная модели
Проблема выбора ограниченного числа экспериментов для анализа вариантов моделируемой системы может быть решена с помощью статистических методов планирования экспериментов.
Теория планирования эксперимента традиционно используется в химии, физике, сельском хозяйстве. В экономике натурный эксперимент исключен, так как труден и дорогостоящ, однако машинный эксперимент, когда все факторы находятся под управлением исследователя возможен.
Теория и практика использования методов планирования разработана в настоящее время достаточно хорошо, —существует большое число работ, специальные справочники, в которых некоторые типы планов стандартизованы, поэтому можно использовать готовые проекты, как выкройки для готовой одежды. Подобно тому, как иногда необходимо подогнать портному выкройку, так и начинающему симуляционисту необходимо изучить основы теории планирования эксперимента, чтобы сделать правильный выбор для своего проекта. Можно рекомендовать следующую специальную литературу, в которой обсуждаются методы планирования машинных экспериментов [16,20, 54].
Машинный эксперимент имеет целый ряд преимуществ по-сравнению с физическим:
Машинный эксперимент управляемый, активный. Существует возможность управления условиями проведения эксперимента. Можно выбирать уровни факторов заведомо постоянные, а не случайные, т.е. строить модели постоянных эффектов. Это упрощает методы планирования экспериментов, снимает проблемы рандомизации и разбиения на блоки, анализа результатов;
В условиях машинного эксперимента выполняется требование воспроизводимости эксперимента. Присутствует легкость воспроизведения условий проведения экспериментов, легкость прерывания и возобновления эксперимента. Это позволяет, например, на ЭВМ реализовать одну и ту же последовательность событий, что полезно в экспериментах при сравнении альтернатив. Кроме того, можно создавать такие условия в компьютерных экспериментах, которые позволяют выполнять допущения и предположения дисперсионного и регрессионного анализов, например, т.к. независимость отклика, однородность дисперсии и некоторые другие;
Еще одно преимущество -при машинных экспериментах можно использовать последовательные или эвристические методы планирования, которые могут оказаться нереализуемыми при экспериментах с реальными системами. В компьютерном эксперименте можно прервать эксперимент, выполнить анализ результатов, а дальше принять решение об изменении параметров модели или продолжить эксперимент с теми же параметрами.
В машинном эксперименте возникают и некоторые трудности: существует "чистая ошибка опыта", вносимая программными датчиками случайных чисел, правда ее можно оценить на стадии определения пригодности модели;
большая роль отводится случайным внешним (экзогенным) факторам, трудность определения понятия выборочной точки (брать среднее значение отклика в прогоне, или моделируемый интервал времени разбивать и усреднять) и некоторые другие.
Основные понятия теории планирования экспериментов
Чтобы оказать помощь в самостоятельном освоении теории планирования экспериментов введем некоторые термины и понятия.
При планировании и построении модельных экспериментов мы имеем дело с двумя типами переменных, которые будем называть в этой лекции факторами и откликами. Для выяснения различий между ними рассмотрим простой эксперимент, в котором рассматриваются лишь две переменные х и у и цель которого состоит в ответе на вопрос: как при изменении х изменяется у? В этом случае х — фактор, а у — отклик. В литературе факторы называют независимыми переменными, а отклики-выходами или зависимыми переменными. Ранее, при разработке имитационной модели мы использовали термины экзогенный (вход) и эндогенный (выход или состояние) соответственно для фактора и отклика.
Итак, термины фактор, режим, независимая переменная, входная переменная и экзогенная переменная эквивалентны, так же как и термины отклик, выход, зависимая переменная, выходная переменная, переменная состояния, эндогенная переменная.
Уровни — это значения квантования каждого фактора.
Планирование эксперимента по имитационному моделированию, как и другие проблемы планирования, требует систематического подхода.
Для выбора плана эксперимента следует:
определить критерии планирования эксперимента. В качестве основных критериев планирования рассматриваются: отклик, число варьируемых факторов, число уровней, необходимое число измерений переменной отклика;
синтезировать экспериментальную модель;
сравнить полученную модель с существующими моделями, со стандартными планами и выбрать оптимальный план.
Процесс построения плана эксперимента разбивается обычно на три этапа: построение структурной модели; построение функциональной модели; построение экспериментальной модели.
Структурная модель характеризуется числом факторов; числом уровней для каждого фактора.
Структурная модель выбирается исходя из того, что должно быть сделано, а функциональная -из того, что может быть сделано.
Выбор этих параметров определяется целями эксперимента, точностью измерений факторов, интересом к нелинейным эффектам и т. п. На этот выбор не должна влиять ограниченность числа возможных измерений, возникающая вследствие ограниченности ресурсов. Подобные ограничения существенны для выбора функциональной модели.
Структурная модель эксперимента, следовательно, имеет вид:
NS = (q 1), (q2), (q 3) - (qk), где NS - число элементов эксперимента; k - число факторов эксперимента; qi - число уровней i -го фактора, i =1, 2,..., k.
Мы называем элементом основной структурный блок эксперимента, определяемый как простейший эксперимент в случае одного фактора и одного уровня, т. е. k = 1, q = 1, NS = 1.
Функциональная модель определяет количество элементов структурной модели, которые должны служить действительными измерителями отклика, т. е. определять, сколько необходимо иметь различных информационных точек. Подобные функциональные модели могут быть либо совершенными, либо несовершенными. Функциональная модель называется совершенной, если в измерении отклика участвуют все ее элементы, т. е. Nf = NS. Функциональная модель называется несовершенной, если число имеющих место откликов меньше числа элементов, т.е. Nf < NS.
В идеале -когда структурная модель совпадает с функциональной, однако в имитационном эксперименте существует ограничение на ресурс. Функциональная модель должна позволить установить компромисс между имеющимися ресурсами и желаниями:
N = pqk, где
р — число повторений экспериментов;
q —число уровней факторов;
k —число факторов (входных параметров и переменных).
С учетом ограничений на ресурсы нужно определить q, k, p.
Вид экспериментальной модели определяется должным образом подобранными критериями планирования. Разработка плана эксперимента включает ряд шагов, в ходе которых экспериментатор должен ответить на ряд важных вопросов.
Шаг первый состоит в выборе переменной отклика (целевой функции, параметра оптимизации), который зависит от цели исследования. Это означает, что мы должны решить, какие отклики интересуют нас в первую очередь, т. е. какие величины необходимо измерить, чтобы получить искомые ответы. Например, при моделировании информационно-поисковой системы нас может интересовать время ответа системы на запрос. В то же время нас может интересовать и максимальное число обслуженных запросов за данный промежуток времени или какие-либо другие характеристики моделируемой системы. При рассмотрении методов планирования в этой лекции мы пока будем иметь дело с однокритериальными задачами.
Основные требования к параметру оптимизации:
он должен быть эффективным с точки зрения достижения цели;
универсальным;
количественным;
статистически эффективным (наиболее точным);
имеющим физический смысл, простым и легко вычисляемым;
существующим (при различных состояниях, ситуациях).
Шаг второй: выделение существенных факторов.
После выбора интересующих нас переменных откликов мы должны определить факторы, которые могут влиять на эти переменные. Обычно число таких факторов довольно велико, и потому необходимо выделять среди них несколько наиболее существенных. К сожалению, чем меньше мы знакомы с системой, тем больше таких факторов, которые, как нам представляется, способны, влиять на отклики. Известно, что, как правило, степень понимания явления обратно пропорциональна числу переменных, фигурирующих в его описании. Большинство систем работает в соответствии с принципом Парето, который гласит, что с точки зрения характеристик системы существенны лишь некоторые из множества факторов. Действительно, в большинстве систем 20% факторов определяют 80% свойств системы, а остальные 80% факторов определяют лишь 20% ее свойств. Наша задача — выделить существенные факторы.
Предварительная процедура в имитационном моделировании, которая упрощает эту задачу -анализ чувствительности имитационной модели.
После определения переменных отклика и выделения существенных факторов необходимо классифицировать эти факторы в соответствии с тем, как они войдут в будущий эксперимент. Каждый фактор может входить в эксперимент тремя способами:
1) фактор может быть постоянным и тем самым играть роль граничных условий эксперимента (в имитационной модели это входные переменные);
2) фактор может быть переменным, но неуправляемым и вносить тем самым вклад в ошибки эксперимента (в имитационной модели это, как правило, внешние, экзогенные переменные);
3) фактор может быть измеряемым и управляемым. Для построения плана эксперимента важны факторы третьего вида. В имитационной модели это параметры.
Основные требования к факторам: управляемость (это позволяет реализовать активный эксперимент) и однозначность.
Требования к совокупности факторов:
выбранное множество должно быть достаточно полным;
точность фиксации факторов должна быть достаточно высокой;
совместимость и отсутствие линейной корреляции, независимость
факторов, т.е. возможность установления факторов на любом уровне,
вне зависимости от уровней других факторов.
Необходимо понимать важность проводимых на этой стадии процесса моделирования рассмотрений. Исследователю необходимо знать, какие переменные ему понадобится измерять и контролировать в процессе проектирования и проведения эксперимента.
Следующий шаг разработки плана эксперимента состоит в определении уровней, на которых следует измерять и устанавливать данный фактор. На это влияет точность измерения, интерес к нелинейным эффектам.
Минимальное число уровней фактора, не являющегося постоянным, равно двум. Очевидно, что число уровней следует выбирать минимально возможным и в то же время достаточным для достижения целей эксперимента. Каждый дополнительный уровень увеличивает стоимость эксперимента, и следует тщательно оценивать необходимость его введения. Выбор для каждого фактора одинакового числа уровней (в особенности если уровней всего два-три) дает определенные аналитические преимущества. Такие структурные модели симметричны и имеют вид
N=qk.
Уровни могут быть:
· качественные или количественные;
· фиксированные или случайные.
Количественной называется переменная, величина которой может быть измерена с помощью некоторой интервальной или относительной шкалы. Примерами могут служить доход, загрузка, цена, время и т. п. Качественной же называется переменная, величина которой не может быть измерена количественно, а упорядочивается методами ранжирования. Примерами качественных переменных могут служить машины, политика, географические зоны, организации, решающие правила, тип очереди в системах массового обслуживания, стратегии в системах принятия решений и т.п. Качественный фактор по своей сути принимает ряд возможных уровней, например стратегий в системах принятия решений. Хотя мы для удобства обозначаем уровни качественного фактора цифрами 1, 2, 3 или буквами А, В, С, мы должны помнить, что подобное упорядочение произвольно, так как качественные уровни нельзя измерять с помощью количественной шкалы.
Для количественного фактора необходимо выделить интересующую нас область его изменения и определить степень нашей заинтересованности нелинейными эффектами. Если нас интересуют только линейные эффекты, достаточно выбрать два уровня количественной переменной на концах интервала области ее изменения. Если же исследователь предполагает изучать квадратичные эффекты, он должен использовать три уровня. Соответственно для кубического случая необходимы четыре уровня и т. д. Число уровней равно минимальному числу точек, необходимых для восстановления полиномиальной функции.
Анализ данных существенно упрощается, если сделать уровни равноотстоящими друг от друга. Такое расположение позволяет рассматривать ортогональное разбиение и тем самым упрощает определение коэффициентов полиномиальной функции. Поэтому обычно две крайние точки интересующей нас области изменения количественной переменной выбирают как два ее уровня, а остальные уровни располагают так, чтобы они делили полученный отрезок на равные части.
Термин фиксированные уровни означает, что мы управляем уровнями квантования или устанавливаем их. Если уровни квантования выбираются случайно (например, с помощью метода Монте-Карло), то уровни называются случайными. Если используемая для построения эксперимента математическая модель имеет фиксированные параметры, она называется жесткой моделью. Если факторы модели могут изменяться случайным образом, она называется вероятностной моделью. Если модель содержит как фиксированные, так и случайные факторы, она называется смешанной моделью.
Чтобы определить необходимое число измерений переменной отклика экспериментатор должен ответить также на ряд вопросов:
а) Следует ли выявить взаимное влияние различных факторов?
Эффектом взаимодействия можно назвать комбинированное влияние на отклик двух или более факторов, проявляющееся помимо индивидуального влияния всех этих факторов по отдельности. На практике это приводит к нелинейным эффектам при построении регрессионных моделей;
б) Каков характер имеющихся ограничений: ограничено время на
исследования, ограничены средства или машинное время на проведение
машинных прогонов?
в) Какова требуемая точность?
План однофакторного эксперимента и процедуры обработки результатов эксперимента
Наиболее прост в планировании так называемый однофакторный эксперимент, в котором изменяется лишь единственный фактор. (Уровни исследуемого фактора могут быть качественными или количественными, фиксированными или случайными). Уровнями фактора могут быть различные стратегии работы, различные конфигурации системы и различные уровни входной переменной. Число наблюдений или прогонов для каждого уровня режима или фактора определяется допустимыми затратами, желаемой мощностью проверки или статистической значимостью результатов.
Рассматриваемую ситуацию можно представить в виде следующей математической модели:
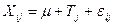 , где
, где
Xij обозначает i -е наблюдение (i = l, 2,..., п) на j -м уровне (j =1, 2,..., k уровней). Например, Х 42обозначает четвертое наблюдение или прогон на втором уровне фактора;
m - общее влияние всего эксперимента;
Tj - влияние j -го уровня,
e ij - случайная ошибка i -го наблюдения на j -м уровне. В большинстве рассматриваемых в литературе экспериментальных моделей предполагается нормально распределенной случайной величиной с нулевым средним и дисперсией s2, одинаковой для всех j.
В более сложных случаях в правую часть приведенного выше уравнения модели включают дополнительные переменные, позволяющие учесть влияние других факторов и условий задачи.
В таблице показан типичный план (макет) однофакторного эксперимента с k уровнями фактора.
Таблица 7.4
План однофакторного ДАНа.
| Уровень фактора | 2... | j … | k | |
| x 11 | x 12... | x 1 j ... | x 1 k | |
| x 21 | x 22 | x 2 j | x 2 k | |
| ××× | ||||
| Среднее |  | 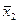 … … | 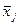 … … | 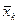 |
Основные методы анализа результатов:
1. Простейший (процедура АNOVA). Если режим или фактор имеют лишь два уровня, то можно использовать процедуры прямой проверки гипотез с использованием стандартных критериев (t, F, h 2 или отношений).
2. Если фактор или режим имеет более двух уровней, то обычно используется однофакторный дисперсионный анализ (ДАН) с нулевой гипотезой Tj = 0 для всех j. Количество наблюдений или прогонов не обязательно одинаково для различных уровней фактора. Если нулевая гипотеза верна, то наблюдение Xij не зависит от уровня фактора и имеет среднее µи случайную ошибку.
Большинство описанных в литературе классических экспериментальных планов основано на использовании дисперсионного или регрессионного анализа после сбора данных. Обычно при наличии качественных факторов используется дисперсионный анализ, а в случае, когда все факторы количественные, — регрессионный анализ. Рассмотрение соотношения между регрессионным и дисперсионным анализом (рис.7.4.).
Дисперсионный анализ приспособлен как к качественным, так и к количественным факторам. Если факторы количественны, то можно использовать ANOVA (ДАН) для проверки, есть ли эффект некоторого фактора, без уточнения (в виде регрессионной кривой) того, как меняется отклик при варьировании фактора во всей области экспериментирования. Если надо оценить отклик в некоторой точке экспериментальной области -следует строить регрессионную кривую.
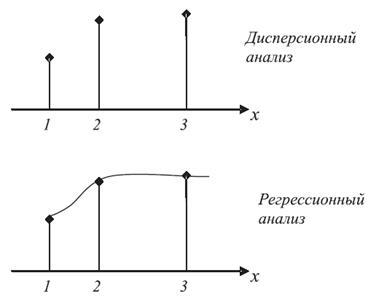
Рис 7.4 — Соотношение между дисперсионным и регрессионным анализом.
3. Методы множественного ранжирования. Методы множественных сравнений.
Это методы применяются при сравнении нескольких вариантов систем, когда изучаем k — систем, каждой системе соответствует одна частная комбинация уровней факторов, варьируемых в эксперименте.
Методы множественного ранжирования — статистические методы полного (для всей совокупности) и неполного ранжирования, в литературе [20] называются методами принятия решений. Эти методы позволяют определить число наблюдений, которые надо взять из каждой k > 2 совокупностей, чтобы выбрать наилучшую совокупность. Наилучшая, обычно, -та совокупность, которая имеет наибольшее (или наименьшее -в зависимости от задачи) - среднее. (Критерием отбора может быть и дисперсия). Большинство процедур ранжирования последовательны. Обзор, эффективность, робастность (устойчивость) методов множественного ранжирования подробно рассматривается в [20].
Методы множественных сравнений. Если число экспериментов задано, тогда можно произвести различные типы сравнений между средними совокупностей:
сравнение со стандартным M 0 средним, соответствующим имеющейся эталонной системе (Mi -M 0), i = l,..., k -l;
все попарные сравнения 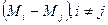 ;
;
построить линейные контрасты 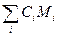 (и сравнить со стандартной системой и т.п.);
(и сравнить со стандартной системой и т.п.);
выделить подгруппу, содержащую наилучшую совокупность, а потом ее дополнительно исследовать экспериментально. Если все факторы количественны -более эффективен регрессионный анализ, чем методы множественных сравнений.

