 2015-08-21
2015-08-21 525
525Наиболее просто градиент функционала вычисляется для однослойных нейронных
сетей. В этом случае M = 1 и выражение для функционала принимает вид:
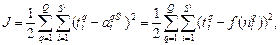
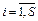 , (3.2)
, (3.2)
где 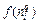 – функция активации;
– функция активации; 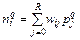 – сигнал на входе функции активации
– сигнал на входе функции активации
для i -го нейрона; 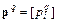 – вектор входного сигнала; R – число элементов вектора входа;
– вектор входного сигнала; R – число элементов вектора входа;
S – число нейронов в слое; 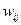 – весовые коэффициенты сети.
– весовые коэффициенты сети.
Включим вектор смещения в состав матрицы весов 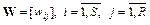 , а вектор входа дополним элементом, равным 1.
, а вектор входа дополним элементом, равным 1.
Применяя правило дифференцирования сложной функции, вычислим градиент функционала ошибки, предполагая при этом, что функция активации дифференцируема:
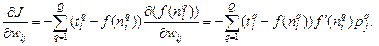 (3.3)
(3.3)
Введем обозначение
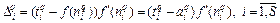 , (3.4)
, (3.4)
и преобразуем выражение (3.3) следующим образом:
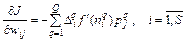 . (3.5)
. (3.5)
Полученные выражения упрощаются, если сеть линейна. Поскольку для такой сети выполняется соотношение 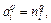 то справедливо условие
то справедливо условие 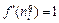 . В этом случае выражение (3.3) принимает вид:
. В этом случае выражение (3.3) принимает вид:
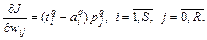 (3.6)
(3.6)
Выражение (3.6) положено в основу алгоритма WH, применяемого для обучения линейных нейронных сетей [45].
Линейные сети могут быть обучены и без использования итерационных методов,
а путем решения следующей системы линейных уравнений:
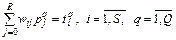 , (3.7)
, (3.7)
или в векторной форме записи:
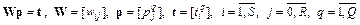 . (3.8)
. (3.8)
Если число неизвестных системы (3.7) равно числу уравнений, то такая система может быть решена, например, методом исключения Гаусса с выбором главного элемента. Если же число уравнений превышает число неизвестных, то решение ищется с использованием метода наименьших квадратов.








