 2015-10-16
2015-10-16 5914
5914Одним из наиболее распространенных в статистике методов несплошного наблюдения является выборочный метод, при котором отбор подлежащих обследованию единиц совокупности осуществляется в случайном порядке. Совокупность, из которой производится отбор, называется генеральной, а ее показатели - генеральными показателями. Совокупность отобранных единиц называется выборочной совокупностью, или просто выборкой, а обобщающие показатели выборки называются выборочными показателями.
Основная задача выборочного метода состоит в том, чтобы на основе характеристик выборочной совокупности получить достоверные характеристики генеральной совокупности. Правомерность распространения характеристик, рассчитанных по выборке, на всю генеральную совокупность и обеспечение в каждом конкретном наблюдении приемлемой ошибки репрезентативности научно обоснована в теории вероятностей и математической статистике.
Выборочное наблюдение является важнейшим источником первичных статистических данных в тех случаях, когда учет всех единиц изучаемой совокупности невозможен по организационным или техническим причинам или требует больших финансовых затрат. Кроме того, выборочный метод приводит к экономии времени и средств в результате уменьшения объема работы и сокращения ошибок, происходящих при регистрации. Ведь при обследовании, скажем, 10-15% единиц совокупности будет затрачено гораздо меньше средств и времени, а результаты могут быть представлены быстрее и будут более актуальными. Фактор времени важен для статистического исследования в области криминальных явлений, особенно в условиях постоянно изменяющейся социально-экономической ситуации. Еще один фактор превращения выборочного наблюдения в важнейший источник социально-правовой информации - возможность его использования в целях уточнения и для разработки данных сплошного обследования. Выборочная разработка данных сплошного наблюдения связана с потребностью представления оперативных предварительных итогов обследования. Кроме того, при обобщении данных сплошного учета (например, карточек единого учета преступлений) невозможно вести сплошную разработку по всем сочетаниям рассматриваемых признаков. В этих условиях выборочный метод позволяет получить необходимые сведения приемлемой точности. В судебной статистике выборочный метод в основном используется при обобщении судебной практики.
Преимущества выборочного наблюдения можно реализовать, если он организован в соответствии с принципами теории выборочного метода:
1) выбор единиц наблюдения должен быть случайным, т.е. каждая единица изучаемой совокупности должна иметь равную вероятность попасть в выборку;
2) выбор должен быть произведен из всех частей изучаемой совокупности (например, из всех категорий гражданских дел);
3) число единиц, взятых для выборочного обследования, должно быть достаточным.
Соблюдение этих принципов позволяет получить гарантию репрезентативности (представительности) выборочной совокупности. Репрезентативность означает, что объекты выборки достаточно хорошо представляют генеральную совокупность.
Выборочное наблюдение достигается в результате применения научно обоснованных способов формирования выборочной совокупности, в зависимости от которых выборка может быть:
- собственно случайной;
- механической;
- типической;
- серийной;
- комбинированной.
Собственно случайная выборка состоит в том, что выборочная совокупность образуется в результате случайного (непреднамеренного) отбора отдельных единиц из генеральной совокупности. Важным условием репрезентативности собственно случайной выборки является то, что каждой единице генеральной совокупности предоставляется равная возможность попасть в выборочную совокупность. Собственно случайная выборка может быть осуществлена по схемам повторного и бесповторного отбора. При повторном отборе единица, попавшая в выборку, после регистрации снова возвращается в генеральную совокупность и при отборе очередной единицы она снова может попасть в выборку. Общая численность единиц генеральной совокупности в процессе выборки остается неизменной. При бесповторном отборе единица совокупности, попавшая в выборку, в генеральную совокупность не возвращается и, таким образом, не имеет шансов быть повторно отобранной в данную выборку. Численность единиц генеральной совокупности в процессе исследования в этом случае сокращается.
На практике для организации собственно случайной выборки часто используют таблицу случайных чисел или генератор случайных чисел. В Microsoft Excel выборка формируется на основе генератора случайных чисел.
Механическая выборка заключается в том, что генеральная совокупность делится на равные по численности группы, количество которых должно быть равно желаемому объему выборки, а затем из каждой группы отбирается одна единица с каким-либо одним и тем же порядковым номером внутри группы. Обычно порядковый номер внутри группы принимается равным обратной величине доли выборки. Например, генеральная совокупность состоит из N = 1000 статистических карточек на осужденных, а выборка определяется равной n = 100 единицам. Тогда доля выборки будет равна 100: 1000 = 1/10 и, следовательно, из каждой группы будет отбираться каждая 10-я статистическая карточка. Механическая выборка применяется в случаях, когда генеральная совокупность каким-либо образом упорядочена, т.е. имеется определенная последовательность в расположении единиц совокупности (номера учреждений уголовно-исполнительной системы - по регионам; номера уголовных дел - в зависимости от подследственности и т.п.).
Типическая выборка применяется в случае изучения совокупности, неоднородной по одному или нескольким существенным признакам, и основана на отборе единиц не из всей генеральной совокупности в целом, а из ее типических групп. Например, при обследовании учреждений уголовно-исполнительной системы такими типическими группами могут быть виды исправительных колоний в зависимости от режима, возраста заключенных и т.д. Для получения типической выборки генеральную совокупность предварительно делят на внутренне однородные группы (страты), соответствующие тем типам единиц, которые представлены в этой совокупности. Непосредственный отбор единиц из типических групп производится в виде собственно случайного или механического отбора в количестве, пропорциональном численности данной группы в генеральной совокупности.
Серийная выборка используется, когда единицы совокупности объединены в небольшие группы или серии, и формируется с помощью собственно случайного либо механического отбора серий, внутри которых производится сплошное обследование единиц. Серии (гнезда) состоят из единиц, связанных между собой территориально, организационно или, наконец, по времени (сотрудники отдела, судьи одного суда, исковые заявления, поступившие в конкретном месяце и т.п.).
Комбинированная выборка предполагает применение на практике комбинации перечисленных выше способов отбора элементов генеральной совокупности. В частности, можно комбинировать типическую и серийную выборки, когда серии отбираются в установленном порядке из нескольких типических групп. Например, при выборочном исследовании гражданских дел такими типическими группами являются суды разного уровня - судебные участки мировых судей, районные суды, суды областного уровня. При этом судебный орган будет являться серией, в которой ведется сплошное статистическое наблюдение.
Основными выборочными показателями являются выборочная доля, выборочное среднее и выборочная дисперсия.
Выборочная доля 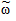 определяется отношением числа единиц выборки m, обладающих изучаемым признаком, к общему числу единиц выборочной совокупности n, т.е.
определяется отношением числа единиц выборки m, обладающих изучаемым признаком, к общему числу единиц выборочной совокупности n, т.е.
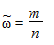
Выборочное среднее 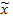 количественного признака определяется по данным выборки по формуле:
количественного признака определяется по данным выборки по формуле:
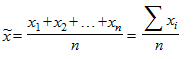 ,
,
где 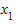 ,
, 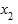 ,...,
,..., 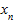 - выборочные значения; n - число выбранных единиц совокупности.
- выборочные значения; n - число выбранных единиц совокупности.
Выборочной дисперсией называют среднее арифметическое квадратов отклонения наблюдаемых значений признака от их выборочного среднего. Она является характеристикой рассеяния значений количественного признака вокруг его среднего значения. Выборочная дисперсия 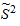 определяется по формуле:
определяется по формуле:
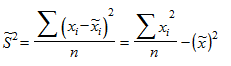 .
.
Наряду с выборочной дисперсией в статистике используется так называемая исправленная выборочная дисперсия 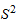 , которая связана с обычной дисперсией следующим соотношением:
, которая связана с обычной дисперсией следующим соотношением:
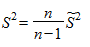 .
.
Введение исправленной выборочной дисперсии связано с тем, что для малых выборок ее использование приводит к лучшим оценкам характеристик генеральной совокупности.
В целом же следует отметить, что все приведенные выше выборочные характеристики являются оценками для соответствующих генеральных характеристик.
Выборочный метод, обладая несомненным достоинством, состоящим в возможности значительно сократить время на получение основных статистических характеристик, приводит к появлению ошибки репрезентативности и уменьшению гарантии получения истинных характеристик генеральной совокупности. Расхождения между характеристиками выборочной и генеральной совокупностей измеряются средней квадратической ошибкой выборки 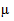 . В математической статистике доказывается, что величина средней квадратической ошибки собственно случайной выборки определяется формулами:
. В математической статистике доказывается, что величина средней квадратической ошибки собственно случайной выборки определяется формулами:
а) в случае повторной выборки:
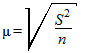 ;
;
б) в случае бесповторной выборки:
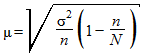 ,
,
где 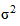 - дисперсия генеральной совокупности, n - объем выборки; N - объем генеральной совокупности.
- дисперсия генеральной совокупности, n - объем выборки; N - объем генеральной совокупности.
Поскольку на практике дисперсия генеральной совокупности неизвестна, то для определения средней квадратической ошибки выборки используются следующие приближенные формулы:
а) в случае повторной выборки:
;
б) в случае бесповторной выборки
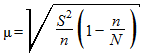 ,
,
где - оценка генеральной дисперсии .
В теории статистики разработаны формулы расчета средней квадратической ошибки выборки применительно к каждому из перечисленных выше способов ее отбора. Если величина этой ошибки рассчитывается с учетом уровня доверительной вероятности, с которой гарантируется достоверность результата, то она называется предельной ошибкой выборки и определяется по формуле:
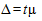 ,
,
где t - коэффициент доверия, зависящий от уровня доверительной вероятности.
Из центральной предельной теоремы теории вероятностей следует, что при достаточно большом объеме выборки доверительная вероятность того, что расхождение между выборочным средним и генеральным средним значением а количественного признака не превзойдет по абсолютной величине 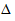 равна:
равна:
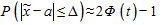 ,
,
где Р(.) - доверительная вероятность неравенства, стоящего в скобках; Ф(t) - функция стандартного нормального распределения, значения которой табулированы (приложение 2, табл. 2).
Таким образом, величина коэффициента доверия t определяется по таблице в зависимости от того, с какой доверительной вероятностью надо гарантировать результаты выборочного обследования. Например, если мы хотим гарантировать результаты выборочного обследования с доверительной вероятностью 0,9545, т.е. 2Ф(t) - 1 = 0,9545, то Ф(t) = 0,97725 и из табл. 2 приложения 2 получим t = 2.
Приведем наиболее часто употребляемые уровни доверительной вероятности и соответствующие значения t (табл. 1).
Таблица 1
| Коэффициент доверия t | 1,0 | 1,96 | 2,0 | 2,58 | 3,0 |
| Уровень доверительной вероятности р | 0,6827 | 0,9500 | 0,9545 | 0,9901 | 0,9973 |
Расчет средней и предельной ошибок выборки позволяет определить возможные пределы, в которых будут находиться характеристики генеральной совокупности с заданной доверительной вероятностью. Например, с учетом предельной ошибки выборки для генеральной средней 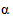 количественного признака такие пределы определяются по следующей формуле:
количественного признака такие пределы определяются по следующей формуле:
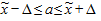 ,
,
где зависит от вероятности того, что средняя величина генеральной совокупности окажется в заданных пределах.
Замечание. Наряду с определением ошибок выборки и пределов для генеральной средней количественного признака, эти же величины могут быть определены для показателя качественного признака - доли признака. При вычислении указанных выше характеристик для доли признака особенности расчета связаны с определением дисперсии доли, оценка которой вычисляется по формуле:
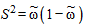 ,
,
где , причем m - число единиц выборки, обладающих данным признаком, а n - объем выборки.
В процессе любого выборочного наблюдения возникает вопрос о том, каков должен быть объем выборки, чтобы ошибка репрезентативности с заданной доверительной вероятностью не вышла за приемлемые для данного наблюдения границы, и в то же время чтобы этот объем не был избыточным для исключения неоправданных затрат на проведение наблюдения. Минимальный необходимый объем выборки рассчитывается для повторного и бесповторного отбора по формулам, которые алгебраически выводятся из рассмотренных ранее формул для расчета ошибок выборки. Так, необходимая численность собственно случайной повторной выборки выражается формулой:
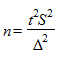 ,
,
а объем собственно случайной бесповторной выборки рассчитывается по формуле:
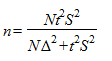 ,
,
где N - объем генеральной совокупности, а - оценка генеральной дисперсии .
Затруднительным моментом применения приведенных формул на практике является нахождение оценки генеральной дисперсии , так как при ее расчете уже необходимо знать объем выборки n. Поэтому для нахождения оценки пользуются или материалами предыдущих исследований или проводят пробное (пилотное) обследование, по результатам которого получают данную оценку генеральной дисперсии.
Пример. Для определения среднего срока нахождения гражданского дела в суде проведено 5%-ное выборочное обследование из 1200 дел. При собственно-случайной бесповторной выборке получены следующие данные о сроках нахождения в производстве суда гражданских дел (в днях): 15, 44, 22, 21, 16, 31, 42, 32, 23, 27, 5, 6, 40, 36, 10, 5, 41, 11, 22, 33, 31, 42, 10, 6, 5, 3, 14, 3, 5, 12, 43, 35, 27, 4, 6, 54, 74, 3, 1, 5, 44, 63, 12, 67, 57, 63, 94, 5, 5, 30, 3, 34, 34, 5, 6, 121, 44, 30, 100, 20.
1. С доверительной вероятностью 0,9545 определить пределы среднего срока нахождения в производстве суда гражданских дел.
2. Считая полученную выборку пробной для нахождения оценки генеральной дисперсии, найти такой необходимый объем выборки, чтобы предельная ошибка выборки не превышала 3 дней с доверительной вероятностью 0,9545.
Решение. Вначале на основе имеющихся данных определим выборочную среднюю и дисперсию. Так как n = 60, то
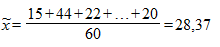 ;
;
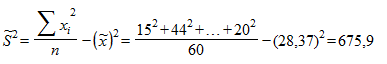 .
.
Откуда
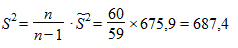 .
.
Вычисляем теперь среднюю ошибку выборки:
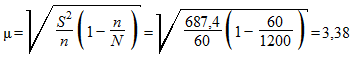 .
.
Тогда предельная ошибка выборки при доверительной вероятности р = 0,9545 равна
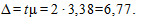
Следовательно, пределы генеральной средней:
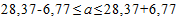
или 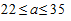 .
.
Таким образом, с доверительной вероятностью 0,9545 можно утверждать, что средний срок нахождения в производстве суда гражданских дел колеблется от 22 до 35 дней.
Для расчета необходимого объема выборки воспользуемся формулой для собственно случайной бесповторной выборки и, подставляя N = 1200, t = 2, 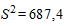 ,
, 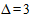 , получим
, получим
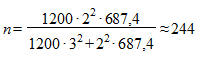 .
.
Таким образом, если из 1200 имеющихся дел мы выберем для наблюдения 244 дела и рассчитаем по данной выборке среднее значение изучаемого признака (срок нахождения дела в производстве), то с вероятностью 0,9545 можно будет утверждать, что это значение отклонится от генеральной средней не более, чем на 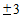 дня. Если же такая точность не обязательна и при таком же уровне доверительной вероятности нас устроит предельная ошибка, например,
дня. Если же такая точность не обязательна и при таком же уровне доверительной вероятности нас устроит предельная ошибка, например, 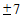 дней (
дней (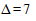 ), то необходимый объем выборки будет значительно меньше:
), то необходимый объем выборки будет значительно меньше:
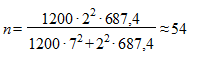 .
.

