 2015-10-22
2015-10-22 683
683В психологии на протяжении всей ее истории преобладало представление, что знакомство с информацией (путем повторной экспозиции) влияет на научение, память и восприятие. Такое знакомство важно также для опознания слов и букв. Как мы уже отмечали, ранние эксперименты по чтению показывают, что знакомство испытуемых с письменным материалом значительно расширяет их способность видеть слово, фразу или сочетание букв. Можно относительно легко измерить, насколько часто мы видели то или иное слово: просто сосчитать слова в образце печатного текста и предположить, что все люди в данной группе (например, все жители США) более или менее одинаково хорошо знакомы с ними. Такой подсчет — определение, насколько распространено какое-либо слово в "английском" (т.е. американском) языке — было предпринято Э.Л.Торндайком в 20-х — начале 30-х г. г. и после модификации стало широко известно как Подсчет Частоты Слов Торндайка-Лорджа (1944). Частотность была определена на материале примерно 20 млн. слов, собранных из журналов, книг и т.д., и табулирована в свод. Более современные подсчеты слов провели Кусера и Фрэнсис (Kucera and Francis, 1967) на основе немногим более одного миллиона слов в 15 различных категориях текста (например, газеты, популярные издания, учебные и научные тексты, художественные тексты). Со времени этих простых подсчетов частоты слов в английском языке проводились и другие измерения, в которых важную роль играли более сложные признаки слов. Характерным примером этих новых подсчетов стало исследование, которое провели Рубин и Фрэндли (Rubin and Friendly, 1986), в котором 925 слов (существительных) оценивались в терминах их "воспроизводимости"6. В нем такие факторы как доступность, добротность, эмоциональность, произносимость и вероятность воспроизведения оценивались в задачах на свободное воспроизведение со многими попытками; было обнаружено, что доступность, образность и эмоциональность лучше всего помогают предсказать, какие слова будут лучше воспроизводиться. Эти нормы обещают расширить наше понимание процесса памяти, а также стандартизировать вербальный учебный материал.
5В некоторых электронных механизмах, например, криптоаналитических компьютерах, предусмотрена возможность "обучения"; при этом хранение информации и декодирование сообщений ведется на основе как хранимой, так и новой полученной информации.
63десь — в смысле припоминаемости.— Прим, ред
Язык, раздел 1: слова u чтение
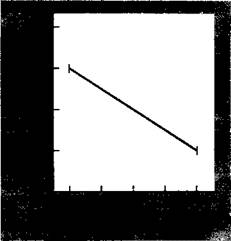
Рис. 10.6. Зависимость величины порога от частоты встречаемости слов в английском языке. Адаптировано из: Howes and Solomon (1951).
Экспериментальные данные по знакомости и опознанию слов в общем поддерживают идею, что знакомость способствует опознанию. Это не вызывает удивления: субъективный опыт говорит нам, что более знакомые слова легче идентифицировать, чем менее известные. Однако и для когнитивного психолога, и для учителя весьма интересно объяснение этого эффекта. Может быть, знакомость буквенных последовательностей выполняет роль фактора избыточности,— так что читатель может точно аппроксимировать слово или букву по минимальному количеству хорошо знакомых признаков. Так знакомость ing, the, est и других часто встречающихся в английском сочетаний букв может повышать предсказуемость их появления в словарном и синтаксическом контекстах. К этому вопросу обращено раннее исследование Хауэса и Соломона (Howes and Solomon, 1951). Они просили испытуемых идентифицировать слова (из Подсчета Торндайка-Лорджа) предъявлявшиеся в течение переменного интервала времени. Некоторые из этих слов были обычными (страна, обещание, пример), некоторые — просто знакомыми (свидетельствовать, обманывать, предполагать), а некоторые — редкими (номинальный, пигмент, мачете). Из результатов, показанных на Рис. 10.6, мы можем заключить, что при увеличении частоты встречаемости слова уменьшается время, необходимое для того, чтобы "увидеть" (или опознать) его (величина порога), и наоборот, чтобы "увидеть" незнакомое слово, требуется больше времени.
Влияние контекста
Опознание Материал, обсуждаемый в этой главе, не оставляет сомнений, что избы- слов точность — весьма существенный фактор для обработки вербального ма-
териала. Приведенные факты не оставляют также сомнений в том, что информационный процессор человека привносит во всякую данную перцептивную ситуацию огромное количество информации. Следовательно, восприятие и обработка информации зависят от взаимодействия двух переменных: содержания стимулов и ожиданий, вырабатываемых у человека его процессором. Чем сильнее ожидание при обработке информации чело-Язык и развитие познания 324
веком, тем меньше информации нужно для его подтверждения, и наоборот — тем больше информации нужно для его опровержения. Эта гипотеза проверялась в исследованиях по опознанию слов, где манипулировали ожиданием испытуемого. Один из первых и лучший из экспериментов в этой области провели Тульвинг и Голд (Tulving and Gold, 1963), которые предлагали испытуемым прочитать часть предложения, затем на очень короткое время предъявляли последнее слово этого предложения и просили испытуемых опознать его. Конечное слово было существенно в первом из двух условий эксперимента и несущественно во втором. Количество контекста составляло одно, два, четыре или восемь слов; вот пример контекстов (последним словом в них было "исполнение"):
Эту
Эту актрису
Эту актрису похвалили
Эту актрису похвалили за выдающееся
Предложения с несущественным контекстом были аналогичными, за исключением того, что последнее слово не соответствовало контексту. Зрительный порог измерялся путем предъявления последнего слова в течение Юме. Если испытуемый ошибался, время экспозиции увеличивалось ступенями по Юме, пока испытуемый не опознавал слово правильно. Результаты показаны на Рис.10.7. Ясно видно, что при увеличении количества существенной информации в контексте скорость опознания возрастает, а с увеличением несущественной информации — снижается. Из того, что нам сегодня известно о долговременной памяти, следует, что вербальный материал организуется в памяти по линиям связной информации. Результаты эксперимента Тульвинга и Голда согласуются с этим представлением. Конкретнее: контекстуальная информация помогает нам "попасть в яблочко", где находится похожая информация, так что когда появляется существенный стимул, он воспринимается с большей готовностью.
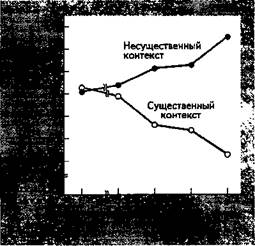
Рис. 10.7. Зависимость пороговой длительности зрительного предъявления от длины существенно,™ и несущественного контекста. Адаптировано из: Tulving and Gold (1963).
Язык, раздел 1: слова u чтение
Логоген Это явление — связь контекстуальной информации и словесного поро-
Мортона га — нельзя объяснить ни вышеприведенными данными, ни сходными дан-
ными других исследователей. Однако, как раз для этого случая Мортон (Morton, 1969, 1970, 1980, 1981; Jackson and Morton, 1984) разработал теоретическую модель опознания слов.
В основу модели опознания слов Мортон заложил логоген7 — гипотетическую конструкцию, которая действует подобно машине сложения: она суммирует информацию до тех пор, пока не будет накоплено некоторое критическое число, после чего появится ответ, соответствующий определенному классу стимулов. Каждый логоген формируется из сенсорной информации — слуховой, зрительной или контекстуальной. Например, опыт восприятий, связанных со словом, "стол" — чтения слова "стол", прослушивания его звучания или появления его в свободных ассоциациях к слову "стул"—- все это будет суммироваться в логогене, относящемся к слову "стол". При возбуждении логогена у испытуемого появляется состояние готовности к конкретному типу ответа. В только что приведенном случае ответ "стол" приобретает высокую степень готовности после возбуждения его логогена. Сила логогена проявляется в потенциале словесной реакции (Рис. 10.8). Как показано на этом рисунке, ответы передаются на "выходной логоген". Согласно модели логогена, испытуемым в эксперименте Тульвинга и Голда для распознавания существенного слова в контексте требовалось меньшее время экспозиции потому, что этот контекст питал энергией логогенную систему, так что когда появлялось соответствующее слово, требовалось меньше энергии стимула (в терминах длительности экспозиции), чтобы возбудить соответствующее слово8. Осо-
7От латинских слов LOGOS (слово) и GENUS (рождение, появление).
83десь неточность: имеется в виду возбуждение ответа, т.е. называния соответствующего слова.— Прим. ред.
Рис. 10.8. Схема потоков информации в модифицированной модели логогена. Адаптировано из: Jackson and Morto-п (1984),
Слуховой анализ
Входные логогены для
слуховой информации
Входные
логогены для
зрительной
информации
Когнитивная система
Система выходных логогенов

Язык и развитие познания 326

Рис. 10.9. Воздействие некоторых ситуаций но состояние ло-гогена. По горизонтальной оси отложен уровень возбуждения. Вертикальные линии показывают порог ло-гогена. В.Ч., С.Ч., и Н. Ч. — соответственно высокая, низкая и средняя частотность слова. Когда уровень возбуждения превышает порог, дается ответ, соответствующий слову. Адаптировано из: Morton (1969).
бенный интерес для современного информационного подхода и теории опознания слов представляет совместимость модели логогена с теорией обнаружения сигналов. Теория обнаружения сигналов (см. Глава 2 и Green and Swets, 1966) предполагает, что чувствительность к стимулам есть непрерывная, а не дискретная функция и что пороги зависят от критерия ответа. Мортон предположил, что логоген работает как устройство обнаружения, чьи критерии ответа изменяются в зависимости от контекста и свойств стимула. Уровень возбуждения логогена (горизонтальная ось на Рис. 10.9) предположительно имеет нормальное распределение. Влияние контекста на логоген заключается в повышении его среднего уровня возбуждения. (На Рис. 10.9 это повышение обозначено "К".) Стимул, например слово, также сдвигает средний уровень возбуждения вверх (Рис.10.9в), а множество признаков (стимул и контекст) повышают возбудимость еще больше (Рис.10.9г). Наконец, частотность слова оказывает длительные влияния, которые снижают сенсорный порог (Рис.10.9д). Исходя из рисунка Мортона, можно предсказать, что, если предъявлялись стимул плюс контекст и если слово-цель (последнее слово) имело высокую частотность, испытуемый "увидит" правильное слово. Интересно то, что по этой модели можно делать количественные предсказания об успешности человека в ряде ситуаций. До сих пор предсказания этой модели об успешности действий человека совпадают с собранными данными.
Новый подход к проблеме влияния контекста на опознание слов предпринял Мейер и его коллеги (Meyer and Schvaneveldt, 1971; Meyer, Schv-aneveldt, and Ruddy 1972; Meyer, Schvaneveldt, and Ruddy, 1974a, 1974b). Они использовали лексические задачи, измеряя время реакции испытуемых при ответе на вопрос, являются ли предъявленные им парные последовательности букв словами или несловами. Вот пример типичных стимулов:
Лексические задачи
Язык, раздел 1: слова u чтение
Связанные слова Несвязанные слова Слово-неслово Неслово-слово Неслово-неслово
ХЛЕБ-МАСЛО
МЕДСЕСТРА-ВРАЧ
МЕДСЕСТРА-МАСЛО
ХЛЕБ-ВРАЧ
ВИНО-СЛИГО
ПЕРЧАТКА-АФОМ
СЛИГО-ВИНО
АФОМ-ПЕРЧАТКА
НАРБ-ТИРЕН
ОРИЛА-РАЕК
В этой процедуре испытуемый смотрит на две точки фиксации (Рис.10.10). Некоторый ряд букв (например, хлеб) появляется на месте верхней точки. Испытуемый нажимает на ключ, показывая этим, является ли данный ряд букв словом. Как только он принял решение, первый ряд букв исчезает, и вскоре после этого появляется второй. Испытуемый решает, является ли словом второй ряд букв, и процесс продолжается. Эта процедура позволяет измерять опознание букв второго слова в зависимости от контекста, создаваемого первым словом. Как можно было предвидеть, Мейер обнаружил, что решения о втором слове принималось гораздо быстрее, когда оно было в паре со связанным словом, чем когда оно было в паре с несвязанным словом (Рис. 10.11).
Здесь мы снова встречаемся с влиянием контекста на опознание слов. Эти данные можно интерпретировать в терминах модели логогена, в которой первое слово возбуждает логоген второго слова. Мейер и др. интерпретировали их в терминах общей схемы информационного подхода, изображенной на Рис. 10.12. Здесь первый этап — это операция кодирования, во время которой создается внутренняя репрезентация. После кодирования последовательность букв проверяется лексической памятью испытуемого — нет ли такого элемента среди запомненных ранее, и в зависимости от результатов сопоставления выполняется решение. Эта модель позволяет сделать два важных предположения относительно хранения лексических событий в памяти: во-первых, что слова хранятся в памяти в различных местах, причем некоторые слова тесно связаны (например, хлеб-масло), а некоторые связаны отдаленно (хлеб-врач); во-вторых, что воспроизведение информации из конкретного места в памяти вызывает нервную активность, распространяющуюся на соседние участки, и таким
Рис. 10.10. Ос
новная процедура каждой пробы в лексической задаче. Адаптировано из: Meyer, Schva-neveldt and Ruddy (1974a).

Язык и развитие познания 328

Рис. 10.11. Влияние семантического контекста на время опознания второго элемента словесной пары в лексической задаче. Адаптировано из: Meyer, Schv-aneveldt, and Ruddy (197 4a).
образом облегчает опознание воспоминаний, связанных с воспроизводимой информацией. Последнюю гипотезу подтверждают эксперименты с контекстом; особый интерес представляет модель опознания букв и слов, которую разработали Мейер и Шваневельдт (Рис. 10.13). (Хотя мы обсуждаем эту модель в связи с опознанием букв и слов, она подходит также для обсуждения семантической памяти.) В этой модели процесс опознания начинается, когда ряд букв поступает на "анализатор деталей". Получающийся при этом код, содержащий информацию о форме букв (прямые линии, кривые, углы), передается на детекторы слов. При обнаружении ими достаточных признаков генерируется сигнал, подтверждающий, что обнаружено некоторое слово; при обнаружении определенного слова возбуждаются и другие расположенные рядом слова. Например, при обнаружении слова "хлеб" активируются также слова, расположенные в сети памяти человека близко от него,— такие как "еда", "масло" и т.д. Их сенсибилизация показана на Рис. 10.13 пунктирными линиями. Возбужде-
Воспроизведение из лексической памяти

Рис. 10.12. Предполагаемые этапы опознания слова. Горизонтальными стрелками показано направление последовательности операций; вертикальными стрелками — качество стимула и воздействие семантического контекста. Meyer, Scbvaneve/df, and Ruddy (1974a).
Язык, раздел I: слова u чтение
Рис. 10.13. Ги-
потетически и механизм объединения сенсорной и семантической информации при опознании слова. Адаптировано из: Meyer and Schvane-veldt(1976a).
Зрительный анализатор деталей
Детектор слова N-2 Детектор слова N-1 Детектор слова N

ние семантически связанных слов облегчает последующее их обнаружение. Эта модель согласуется с данными, что испытуемые опознают связанные слова быстрее, чем несвязанные. Она привлекательна также тем, что открывает путь к пониманию структуры семантической памяти.
Теоретические позиции Мейера и Мортона не противоречат друг другу — на самом деле они взаимодополняющие. Обе они обращены к проблеме влияния контекста на опознание слов, и обе предполагают наличие некоторого внутреннего механизма, способного улучшать опознание в зависимости от контекста. По Мортону,— это механизм повышения уровня возбуждения логогена; по Мейеру,— это распространение нервной активности, облегчающее доступ к сходным лексическим элементам.








