 2015-10-22
2015-10-22 4407
4407В последние годы широкое распространение получили методы статистического анализа, оценивания и оптимального управления стохастическими системами, основанные на использовании результатов теории марковских процессов. В данном разделе рассматривается применение методов теории марковских процессов для статистического анализа линейных и нелинейных стохастических систем.
Уравнение Фоккера — Планка — Колмогорова. В теории марковских процессов получены дифференциальные уравнения в частных производных параболического типа для условной (переходной)  и безусловной
и безусловной  плотностей распределения вероятностей непрерывного марковского процесса x(t). Применительно к скалярному марковскому процессу x(t) уравнение для плотности , называемое уравнением Фоккера — Планка — Колмогорова (ФПК), имеет вид
плотностей распределения вероятностей непрерывного марковского процесса x(t). Применительно к скалярному марковскому процессу x(t) уравнение для плотности , называемое уравнением Фоккера — Планка — Колмогорова (ФПК), имеет вид

Функции а(х, t) и b(x, t) называют соответственно коэффициентами сноса и диффузии марковского процесса x(t).
В многомерном случае уравнение ФПК для векторного марковского процесса x(t), состоящего из п компонент  , записывается следующим образом:
, записывается следующим образом:

где  — вектор коэффициентов сноса;
— вектор коэффициентов сноса;  —матрица коэффициентов диффузии векторного процесса x(t).
—матрица коэффициентов диффузии векторного процесса x(t).
Интегрируя уравнение ФПК при заданном начальном условии  , можно определить плотность распределения вероятностей рассматриваемого марковского процесса в последующие моменты времени.
, можно определить плотность распределения вероятностей рассматриваемого марковского процесса в последующие моменты времени.
Стохастические дифференциальные уравнения. Среди различных непрерывных марковских процессов в практических задачах особенно большое значение имеют так называемые диффузионные марковские процессы, изменение которых во времени описывается дифференциальными уравнениями вида

где 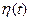 —стандартный белый шум.
—стандартный белый шум.
Такие уравнения называют стохастическими дифференциальными уравнениями.
Уравнение вида (2.53) можно записать непосредственно для изучаемой динамической системы, если случайное входное воздействие этой системы действительно может быть аппроксимировано стандартным белым шумом. Например, одномерной системе, состоящей из интегрирующего звена 1/p, охваченного нелинейной обратной связью f(x), подверженной воздействию белого шума на входе, соответствует стохастическое дифференциальное уравнение первого порядка

Используя метод формирующих фильтров, к виду (2.53) можно привести уравнения, описывающие поведение систем, подверженных воздействию окрашенных шумов.
Пример. Пусть исследуемая динамическая система описывается передаточной функцией апериодического звена

Внешнее воздействие  —случайный процесс со спектральной плотностью
—случайный процесс со спектральной плотностью

Коэффициент усиления К является гауссовской случайной величиной, характеризуемой параметрами mk и Dk.
Чтобы описать эту систему стохастическим дифференциальным уравнением, перепишем соотношение (2.54) в виде дифференциального уравнения в нормальной форме:

Последнее уравнение объединим с уравнением формирующего фильтра для , полученные ранее [см. формулу (2.30')].

где

и уравнением формирующего фильтра для случайного параметра
 (2.58)
(2.58)
В результате получим стохастическое дифференциальное уравнение вида (2.53), описывающее рассматриваемую динамическую систему, в котором векторный случайный процесс x(t), объединяющий в качестве составляющих переменные у, x1 и К, есть диффузионный марковский процесс. Компоненты вектор-функции fT(x, t) — [fi(x, t)]n в данном случае равны

Белый шум является скалярным случайным процессом, поскольку в; правые части уравнений (2.56) и (2.57) входит одно и то же внешнее случайное воздействие, а

Возникает вопрос, как выражаются коэффициенты сноса а(х, t) и диффузии b(x, t), входящие в уравнение ФПК (2.51) или (2.52),. описывающие изменение плотности р(х, t) распределения вероятностей диффузионного марковского процесса x(t), через f(x, t) и  ? В зависимости от ответа на этот вопрос различают стохастические дифференциальные уравнения Ито и Стратоновича_ В уравнении Ито в скалярном случае коэффициенты сноса и диффузии соответственно равны f(x, t) и
? В зависимости от ответа на этот вопрос различают стохастические дифференциальные уравнения Ито и Стратоновича_ В уравнении Ито в скалярном случае коэффициенты сноса и диффузии соответственно равны f(x, t) и  . Для стохастического дифференциального уравнения Стратоновича эти коэффициенты определяются соотношениями *(* Диментберг М. Ф. Нелинейные стохастические задачи механических колебаний. М.: Наука, 1980. 368 с.)
. Для стохастического дифференциального уравнения Стратоновича эти коэффициенты определяются соотношениями *(* Диментберг М. Ф. Нелинейные стохастические задачи механических колебаний. М.: Наука, 1980. 368 с.)
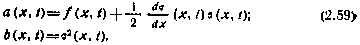
Конкретный вариант используемой интерпретации стохастического дифференциального уравнения зависит от особенностей анализируемой физической системы.
В рассматриваемом далее в данной главе наиболее широко распространенном случае, когда не зависит от х, флуктуационная поправка к коэффициенту сноса, возникающая при рассмотрении стохастического дифференциального уравнения Стратоновича, обращается в нуль и обе интерпретации приводят к одним и тем же результатам.
Интегрировать аналитически и даже численно уравнение в частных производных параболического типа, каким является уравнение ФПК трудно, особенно в тех случаях, когда размерность вектора х велика. Только в одномерном и в отдельных двумерных случаях удается найти аналитическое решение этого уравнения, соответствующего стохастическому дифференциальному уравнению нелинейной системы. Однако каждое такое решение представляет большой интерес, поскольку оно является наиболее полной характеристикой точности системы, позволяющей оценить точность решений, полученных с помощью приближенных методов — расчета, например, с помощью метода статистической линеаризации.

Рис. 2.1. Нелинейная система первого порядка.
Так, стационарным решением уравнения ФПК, соответствующего нелинейной системе первого порядка, показанной на рис. 2.4, для р(х, ∞)=рст(х) является выражение [34]
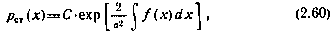
в котором постоянная интегрирования С выбирается из условия нормировки  . В случае стационарной линейной системы при f(x). = - х из (2.60) получаем гауссовскую плотность
. В случае стационарной линейной системы при f(x). = - х из (2.60) получаем гауссовскую плотность  . Если в обратной связи стоит реле с уровнем насыщения А, то
. Если в обратной связи стоит реле с уровнем насыщения А, то

Плотности (2.61) соответствуют  и
и  .
.
Уравнения для моментов диффузионного процесса. Основным применением уравнения ФПК при априорном анализе точности систем является получение с его помощью обыкновенных дифференциальных уравнений для вектора математических ожиданий mx(t) и корреляционной матрицы Kx(t) фазового вектора диффузионной марковской системы. Эти уравнения оказываются точными, если стохастическое дифференциальное уравнение (2.53) — линейное, и приближенными в случае нелинейного уравнения (2.53).
Чтобы получить из уравнения ФПК уравнения для  и
и  в случае, когда x(t) —скалярный процесс, умножим (2.51) на х и проинтегрируем обе части по этой переменной в бесконечных пределах. Тогда получим
в случае, когда x(t) —скалярный процесс, умножим (2.51) на х и проинтегрируем обе части по этой переменной в бесконечных пределах. Тогда получим

Слева в уравнении (2.62) имеем

а интеграл справа вычисляем, применяя метод интегрирования по частям и учитывая граничные условия  . Окончательный результат оказывается следующим:
. Окончательный результат оказывается следующим:

Уравнение для дисперсии Dx получают, умножив левую и правую части (2.51) на  и проинтегрировав их по переменной х в бесконечных пределах. В итоге имеем
и проинтегрировав их по переменной х в бесконечных пределах. В итоге имеем

Соотношениями (2.64) — (2.65) устанавливается связь между производными по времени от mx и Dx диффузионного процесса x(t) и его плотностью распределения р(х, t). Из них нельзя найти mx(t) и Dx(t), если плотность р(х, t) неизвестна.
Уравнения для моментов в линейной системе. Если коэффициент сноса f(x, t) в правой части стохастического дифференциального уравнения (2.57) — линейный относительно х, т. е. f(x,t)=a(t)x + b(t), то соотношения (2.64) и (2.65) превращаются в уравнения относительно mx и Dx, т. е. становятся замкнутыми. Действительно, в этом случае

поэтому для линейной марковской системы первого порядка

Интегрирование уравнений (2.66) и (2.67) при заданных начальных условиях mx(t0) и Dx(t0) позволяет определить mx(t) и Dx(t).
Если рассматриваемая система — стационарная и устойчивая, а искомыми являются mx и Dx в установившемся режиме, то эти величины можно найти из алгебраических уравнений

поскольку в установившемся режиме для такой системы  и
и 
В многомерном случае уравнения для тх и Кх оказываются следующими:

Векторное уравнение (2.69) размерности п совместно с матричным уравнением (2.70) размерности п×п называют корреляционной системой уравнений. Системы (2.69) и (2.70) не зависят друг от друга, поэтому их можно интегрировать раздельно. Учитывая симметричность матрицы Кх, Для ее определения достаточно про-янтегрировать п(п+1)/2 уравнений относительно различных ковариационных моментов Кх. Начальными условиями для (2.69) и (2.70) являются вектор математических ожиданий mx(t0) и корреляционная матрица Кх (t0) фазового вектора x(t0) в начальный момент времени.
Если исследуемая линейная марковская система — стационарная и устойчивая, а искомыми являются тх и Кх в установившемся режиме, то их можно найти из систем алгебраических уравнений

Одним из способов решения может служить интегрирование соответствующих им систем дифференциальных уравнений (2.69) и (2.70) при произвольно заданных начальных условиях. Сходимость решения обеспечивается устойчивостью исследуемой динамической системы.
Приближенные уравнения для определения моментов диффузионного процесса в нелинейной системе. Для получения приближенной замкнутой системы уравнений из (2.64) и (2.65) в общем случае нелинейного коэффициента сноса f(x, t) предположим, что плотность р(х, t) распределения вероятностей фазового вектора гауссовская. При р(х, t) =pГ(x, t) интегралы в правых частях соотношений (2.64) и (2.65) можно вычислить. Результирующие функции зависят от mx(t) и Dx(t), описывающих pГ(x, t):
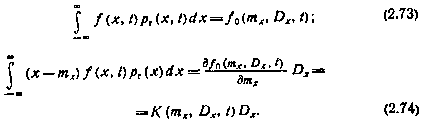
Подставив (2.73) и (2.74) в (2.64) и (2.65), получим систему из двух нелинейных обыкновенных дифференциальных уравнений:

Интегрирование этой системы при заданных mx(t0) и Dx(t0) позволяет найти mx(t) и Dx(t), т. е. решить приближенно задачу статистического анализа рассматриваемой нелинейной системы. Для «типовых» нелинейностей f(x) формулы для f0(mx, Dx) и K(mx, Dx) могут быть взяты из таблиц выражений коэффициентов статистической линеаризации.
Пример. Пусть f(x) в (2.53)—релейная характеристика f(x)= — A sign (x).
Для этой нелинейности f  (см. пример в разд. 1.1) и
(см. пример в разд. 1.1) и

Уравнеиия для mx и Dx в такой системе имеют вид
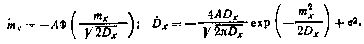
Установившиеся значения  и
и  получаем, положив
получаем, положив  и .
и .
Имеем 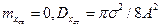 . Сравнивая приближенное значение с точным, полученным ранее путем решения уравнения ФПК значением, видим, что предположение о гауссовском распределении р(х) в рассматриваемой нелинейной системе с реле в обратной связи приводит к ошибке в дисперсии, равной 22%.
. Сравнивая приближенное значение с точным, полученным ранее путем решения уравнения ФПК значением, видим, что предположение о гауссовском распределении р(х) в рассматриваемой нелинейной системе с реле в обратной связи приводит к ошибке в дисперсии, равной 22%.
В многомерном случае вектор mx(t) и корреляционную матрицу Kx(t) можно найти в результате совместного интегрирования двух систем обыкновенных дифференциальных уравнений

 — матричная функция, элементами которой являются частные производные от составляющих вектор-функции
— матричная функция, элементами которой являются частные производные от составляющих вектор-функции  по компонентам вектора тх.
по компонентам вектора тх.
Если в состав исследуемой системы входят только линейные звенья и типовые одномерные существенные нелинейности, то корреляционную систему вида (2.76) удобно составить, применяя совместно статистическую линеаризацию нелинейных звеньев и корреляционную систему уравнений (2.69) — (2.70) для статистически линеаризованной системы.
Когда управляемое движение летательного аппарата описывается нелинейными стохастическими дифференциальными уравнениями, правые части которых содержат гладкие многомерные нелинейности, приближенный анализ точности такого движения значительно упрощается по сравнению с непосредственным использованием уравнений (2.76), если пользоваться так называемой квазилинейной корреляционной системой уравнений. При составлении такой системы полное движение исследуемой системы разбивается на два движения: среднее и возмущенное. Для описания среднего движения, характеризующего изменение математических ожиданий составляющих фазового вектора, используются нелинейные уравнения системы при математических ожиданиях (средних значениях) начальных условий и внешних воздействий. Для описания возмущенного движения, характеризующего случайные отклонения составляющих фазового вектора от их средних значений, применяются линеаризованные уравнения, причем в качестве опорных значений при линеаризации берутся математические ожидания фазовых координат в соответствующие моменты времени.
Пример. Рассмотрим задачу баллистического спуска летательного аппарата, т. е. спуска с нулевой подъемной силой, в атмосфере Земли. Продольное движение аппарата описывается нелинейными дифференциальными уравнениями

Требуется оценить рассеивание траекторий аппарата, предполагая случайными переменные V, θ, Н и L в момент t0 начала спуска; постоянными величины R, Сх, S, т и g, а зависимость  —показательной вида
—показательной вида  , где
, где  .
.
Перепишем уравнения движения аппарата в виде векторного уравнения

Представим фазовый вектор х в виде х=тх+Δх, а нелинейную вектор-функцию f(x, t) линеаризуем в окрестности х=тх:

где  —матрица 4×4 частных производных вектор-функции f(x, t) по составляющим вектора х, вычисленная при х=тх. Получаем уравнение
—матрица 4×4 частных производных вектор-функции f(x, t) по составляющим вектора х, вычисленная при х=тх. Получаем уравнение

из которого в результате усреднения непосредственно находим уравнение для вектора математических ожиданий

по виду совпадающие с (2.77). Вычтя (2.79) из (2.78), получаем линеаризованное уравнение возмущенного движения

на основе которого составляем уравнение для корреляционной матрицы фазового вектора
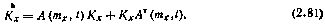
Совместное интегрирование уравнений (2.80) и (2.81), в совокупности образующих квазилинейную корреляционную систему уравнений, при заданных начальных условиях тх(t0) и Kx(t0) позволяет определить тх(t) и Kx(t) в последующие моменты времени. Точность решения определяется точностью аппроксимации вектор-функции линеаризованной зависимостью при тех значениях случайных отклонений Δx (t) фазового вектора x(t), которые имеют место в рассматриваемой задаче при заданных статистических характеристиках случайных, начальных условий.
2.6. МЕТОД СТАТИСТИЧЕСКОГО МОДЕЛИРОВАНИЯ (МОНТЕ-КАРЛО)
Метод статистического моделирования — универсальный метод статистического анализа стохастических систем (линейных и нелинейных, стационарных и нестационарных), подверженных воздействию случайных факторов различных типов с произвольными их статистическими свойствами. В литературе данный метод также называют методом статистических испытаний или методом Монте-Карло.
Основу метода статистического моделирования составляет закон больших чисел, заключающийся в том, что результат усреднения, относящийся к случайному фактору (событию, величине, процессу или полю), вычисленный по п его реализациям, при  перестает быть случайным и может рассматриваться в качестве оценки соответствующей характеристики рассматриваемого фактора. В частности, в соответствии с теоремой. Бернулли при большом числе опытов (реализаций) частота случайного события приближается к вероятности этого события. Аналогичные теоремы существуют и для статистических характеристик случайных величин, процессов, полей.
перестает быть случайным и может рассматриваться в качестве оценки соответствующей характеристики рассматриваемого фактора. В частности, в соответствии с теоремой. Бернулли при большом числе опытов (реализаций) частота случайного события приближается к вероятности этого события. Аналогичные теоремы существуют и для статистических характеристик случайных величин, процессов, полей.
Применительно к априорному анализу точности стохастических систем метод статистического моделирования заключается в проведении на ЭВМ статистических экспериментов, имитирующих функционирование исследуемой системы при действии случайных факторов, и в последующей обработке полученных в этих экспериментах результатов с помощью методов математической статистики для определения соответствующих статистических характеристик.
Методика статистического моделирования. Первым этапом подготовки к статистическому моделированию стохастической системы является выбор типа ЭВМ (ЦВМ, АВМ или аналого-цифрового комплекса), на которой целесообразно проводить моделирование. При этом учитываются сложность исследуемой системы, характер и число нелинейностей в ней, скорость протекания процессов в различных частях (звеньях) системы, тип и характеристики действующих на систему случайных возмущений и другие факторы.
Выясняется возможность использования канонических разложений случайных процессов, действующих на исследуемую систему. Если такие разложения известны для всех случайных функций, рассматриваемых в системе, моделирование системы можно заметно упростить, поскольку в этом случае при моделировании требуется получать реализации только случайных величин (начальных условий, параметров системы и коэффициентов канонических разложений).
Более общей и сложной является ситуация, когда в число возмущений системы входят случайные процессы, для которых канонические разложения не известны. В этом случае описывающие исследуемую динамическую систему уравнения сводятся к системе стохастических дифференциальных уравнений в нормальной форме вида

где λ — вектор случайных параметров системы; — векторный белый шум. Вектор начальных условий x(t0) также может быть случайным.
Некоторые из действующих на систему случайных возмущений могут оказаться не белым шумом. Для таких процессов требуется составить дифференциальные уравнения формирующих фильтров. Эти уравнения при моделировании следует интегрировать совместно с уравнениями системы (2.82).
Далее составляется программа интегрирования на ЦВМ системы (2.82) совместно с уравнениями формирующих фильтров или схема моделирования для АВМ. Характерными элементами программы являются блоки, обеспечивающие получение реализаций случайных факторов, рассматриваемых в системе.
Получение на ЭВМ реализаций случайных величин. При моделировании задачи на АВМ, а иногда и на ЦВМ реализации случайных величин задают с помощью таблиц случайных чисел. Наибольшее распространение получили таблицы случайных чисел, подчиняющихся нормальному (гауссовскому) и равномерному распределениям. Таблица нормально распределенных случайных чисел содержит реализации гауссовской случайной величины  соответствующие
соответствующие  и
и  .Беря числа из этой таблицы, реализации
.Беря числа из этой таблицы, реализации  гауссовской случайной величины с характеристиками и
гауссовской случайной величины с характеристиками и  вычисляют по формуле
вычисляют по формуле
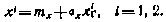
Таблица равномерно распределенных чисел содержит реализации 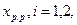 подчиняющиеся равномерному на интервале [0,1] распределению вероятностей. Для получения реализаций величины х, распределенной равномерно на интервале [Xmin, Xmax] числа
подчиняющиеся равномерному на интервале [0,1] распределению вероятностей. Для получения реализаций величины х, распределенной равномерно на интервале [Xmin, Xmax] числа 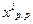 , взятые из таблицы, преобразуют с помощью соотношения
, взятые из таблицы, преобразуют с помощью соотношения

Основным способом получения реализаций случайных величин на ЦВМ является использование специальных стандартных подпрограмм, называемых датчиками псевдослучайных чисел. При каждом обращении к датчику в нем вычисляется новое случайное число. Расчет проводится с помощью рекуррентной формулы, аргументами которой являются несколько случайных чисел, вычисленных при предыдущих обращениях к данной подпрограмме. При фиксированной начальной (стартовой) совокупности случайных чисел все рекуррентно вычисляемые датчиком последующие числа будут определенными, зависящими от стартовой совокупности, поэтому числа, получаемые с помощью датчика, называют псевдослучайными. Рекуррентная формула, реализованная в датчике, подбирается так, чтобы псевдослучайные числа, получаемые с помощью датчика, обладали требуемыми статистическими свойствами — соответствовали определенной плотности распределения вероятностей р(х), а коэффициент корреляции был равен нулю.
Как правило, в библиотеке стандартных подпрограмм ЦВМ присутствуют два датчика псевдослучайных чисел: равномерно распределенных на интервале [0,1] и гауссовских с и .
Получение реализаций векторной гауссовской случайной величины затруднений не вызывает, если этот вектор некоррелирован. Реализации отдельных компонент такого вектора можно рассчитывать с помощью датчика гауссовских чисел независимо друг от друга. Если же гауссовский вектор х коррелирован, его реализации получают путем линейного преобразования реализаций некоррелированного гауссовского вектора U той же размерности, формируемого с помощью датчика гауссовских псевдослучайных чисел. У вектора U математическое ожидание — нулевой вектор, а корреляционная матрица — единичная. Матрица линейного преобразования А подбирается так, чтобы результирующая ковариационная матрица Кх была равна заданной. При ее определении используется соотношение (1.26).
При  из (1.26) получаем следующее уравнение относительно А:
из (1.26) получаем следующее уравнение относительно А:

Это уравнение имеет бесчисленное множество решений. Если искать А в виде треугольной матрицы вида

то из (2.83)получим n(n+1)/2 уравнений для элементов этой матрицы, которые можно решить рекуррентно. Результатом являются следующие выражения для элементов матрицы А:


где  — элементы заданной корреляционной матрицы
— элементы заданной корреляционной матрицы  .
.
Пример. Пусть х — двумерный вектор с корреляционной матрицей

Найдем матрицу А, такую, что

где  —некоррелированный вектор с
—некоррелированный вектор с  .
.
С помощью соотношений (2.84) находим ац 
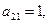
 т. е.
т. е. 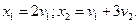
В ряде случаев требуется получать реализации случайной величины, распределение которой не является ни равномерным, ни га-уссовским. Наиболее распространенным способом моделирования в данном случае является нелинейное преобразование реализаций, получаемых с помощью датчика равномерно распределенных чисел.
Задача определения нелинейного преобразования y=f(x), связывающего случайные величины х и у с заданными плотностями распределения р(х) и р(у) (плотность р(х) —равномерная), является обратной по отношению к задаче определения распределения нелинейной функции случайной величины, рассмотренной в разд. 1.1. Если распределение р(х) — равномерное, то из соотношения (1.32) имеем  , откуда при монотонно возрастающей функции
, откуда при монотонно возрастающей функции  получаем
получаем

где F (у) — интегральная функция распределения вероятностей величины у.
Функция является обратной по отношению к искомой функции f(x). Таким образом, определение искомого нелинейного преобразования y = f(x) сводится к нахождению по заданной плотности р(у) интегральной функции F(y) и последующему решению уравнения F (у) =х относительно у.
Пример. Пусть

Тогда в интервале (0, 1) имеем xF(y)=y2, откуда 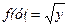 ,т. е.
,т. е.  .
.
Иной подход может быть применен в тех случаях, когда требуется получать реализации случайной величины у по имеющейся ее гистограмме или когда распределение р(у) имеет сложную форму, которую целесообразно аппроксимировать ступенчатой зависимостью.
Пусть интервал [у0, уп] практически возможных значений случайной величины у, имеющей распределение р(у), разбит на п участков 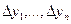 , в пределах каждого из которых плотность р(у) можно полагать равномерной. Вероятность попадания в каждый интервал
, в пределах каждого из которых плотность р(у) можно полагать равномерной. Вероятность попадания в каждый интервал

причем  . При использовании такой аппроксимации р(у)
. При использовании такой аппроксимации р(у)
реализацию  можно определить в результате двукратного обращения к датчику равномерно распределенных псевдослучайных чисел. При первом обращении разыгрывается исход попадания реализации yi в один из интервалов
можно определить в результате двукратного обращения к датчику равномерно распределенных псевдослучайных чисел. При первом обращении разыгрывается исход попадания реализации yi в один из интервалов 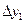 . Для этого вероятностям Pl попадания yi в интервалы
. Для этого вероятностям Pl попадания yi в интервалы  ставятся в соответствие интервалы
ставятся в соответствие интервалы  значений равномерно распределенных псевдослучайных чисел из общего диапазона [0, 1]. Попаданию случайного числа хiр.р, получаемого в результате обращения к датчику, в интервал
значений равномерно распределенных псевдослучайных чисел из общего диапазона [0, 1]. Попаданию случайного числа хiр.р, получаемого в результате обращения к датчику, в интервал  ставится в соответствие попадание реализации yi в интервал . При втором обращении к датчику разыгрывается значение реализации yi как случайной величины, распределенной равномерно в интервале .
ставится в соответствие попадание реализации yi в интервал . При втором обращении к датчику разыгрывается значение реализации yi как случайной величины, распределенной равномерно в интервале .
Моделирование на ЭВМ реализаций случайных процессов. На АВМ реализации случайных процессов получают с помощью генераторов шума. Так называют электронный прибор, электрическое напряжение на выходе которого является случайным процессом с заданными статистическими характеристиками. Генераторы, используемые при статистическом моделировании управляемого движения летательных аппаратов, генерируют шум с равномерной спектральной плотностью в диапазоне инфранизких частот (от 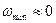 до
до 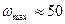 Гц) и с гауссовским одномерным распределением вероятностей. При статистическом моделировании систем, полоса пропускания которых уже, чем
Гц) и с гауссовским одномерным распределением вероятностей. При статистическом моделировании систем, полоса пропускания которых уже, чем  , а именно такими, как правило, являются системы управления летательными аппаратами, шум генераторов можно считать белым. Окрашенные шумы, действующие на изучаемую систему, моделируют на АВМ путем пропускания белого шума через соответствующим образом подобранный формирующий фильтр.
, а именно такими, как правило, являются системы управления летательными аппаратами, шум генераторов можно считать белым. Окрашенные шумы, действующие на изучаемую систему, моделируют на АВМ путем пропускания белого шума через соответствующим образом подобранный формирующий фильтр.
На ЦВМ белый шум моделируют, аппроксимируя его приближенно ступенчатым абсолютно случайным процессом x(t). Реализации последнего вычисляются по следующему правилу. Аргумент процесса — время t —изменяется дискретно с шагом Δt. В пределах каждого шага  значение реализации
значение реализации  задается заново с помощью датчика гауссовских псевдослучайных чисел
задается заново с помощью датчика гауссовских псевдослучайных чисел

где В — постоянный множитель.
На всем интервале значение  остается постоянным. Псевдослучайные числа, получаемые при помощи датчика, попарно некоррелированы друг с другом. Следовательно, корреляция между значениями ступенчатого процесса x(t) в различных интервалах и
остается постоянным. Псевдослучайные числа, получаемые при помощи датчика, попарно некоррелированы друг с другом. Следовательно, корреляция между значениями ступенчатого процесса x(t) в различных интервалах и  , отсутствует. Поэтому корреляционная функция данного процесса равна
, отсутствует. Поэтому корреляционная функция данного процесса равна

При  отношение
отношение 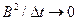 . Следовательно, при достаточна малой величине интервала
. Следовательно, при достаточна малой величине интервала 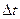 процесс x(t) с корреляционной функцией Rx(t), определяемой соотношением (2.85), можно рассматривать в качестве приближенной аппроксимации белого шума с интенсивностью
процесс x(t) с корреляционной функцией Rx(t), определяемой соотношением (2.85), можно рассматривать в качестве приближенной аппроксимации белого шума с интенсивностью  . Точность аппроксимации оказывается тем выше, чем меньше интервал .
. Точность аппроксимации оказывается тем выше, чем меньше интервал .
При численном интегрировании стохастических дифференциальных уравнений (2.82) на ЦВМ величина интервала , используемого при моделировании белого шума , действующего на систему, не может быть задана меньше шага интегрирования 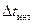 . Следовательно, шаг численного интегрирования должен определяться из условия
. Следовательно, шаг численного интегрирования должен определяться из условия

где  — интервал, при котором ступенчатый абсолютно случайный процесс достаточно точно аппроксимирует белый шум;
— интервал, при котором ступенчатый абсолютно случайный процесс достаточно точно аппроксимирует белый шум;  — шаг численного интегрирования, обеспечивающий приемлемую точность вычислений при избранном методе численного интегрирования системы (2.82).
— шаг численного интегрирования, обеспечивающий приемлемую точность вычислений при избранном методе численного интегрирования системы (2.82).
Эксперименты на ЦВМ показывают, что при всех методах численного интегрирования  , поэтому для обеспечения аппроксимации белого шума ступенчатым процессом интегрирование системы (2.82) должно вестись с шагом
, поэтому для обеспечения аппроксимации белого шума ступенчатым процессом интегрирование системы (2.82) должно вестись с шагом 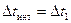
Среди всех методов численного интегрирования затраты машинного времени на один шаг интегрирования являются наименьшими при интегрировании по методу Эйлера:

Вследствие этого данный метод и следует использовать при статистическом моделировании систем, беря , а коэффициент В рассчитывать по формуле

где  — интенсивность белого шума, действующего на систему.
— интенсивность белого шума, действующего на систему.
Проведение статистического моделирования и обработка его результатов. Составив программу моделирования исследуемой динамической системы на ЦВМ или набрав схему моделирования на АВМ, с их помощью получают необходимое число реализаций выходных координат исследуемой системы. Обработка результатов^ моделирования может проводиться или при моделировании, или после его завершения с использованием методов математической: статистики [14, 27]. В зависимости от конкретной цели статистического моделирования результатами обработки могут быть оценки математических ожиданий, дисперсий, взаимных корреляционных моментов, корреляционных функций и других статистических характеристик выходных координат системы. Точность оценок будет тем выше, чем большее число реализаций будет статистически обработано. Соотношения для расчета доверительных интервалов и доверительных вероятностей оценок различных параметров в зависимости от числа реализаций, используемых для их получения, приводятся в книгах [8, 27].
Если исследуемая система и действующие на нее возмущения таковы, что рассматриваемая выходная переменная является эргодическим стационарным процессом, то при моделировании достаточно ограничиться получением одной длинной реализации это» переменной. В иных случаях требуется получать и обрабатывать множество реализаций выходных координат.
ГЛАВA 3.
МЕТОДЫ ОПРЕДЕЛЕНИЯ ОЦЕНОК СОСТОЯНИЯ ЛЕТАТЕЛЬНЫХ АППАРАТОВ
3.1. ЗАДАЧА ОЦЕНИВАНИЯ КАК ЧАСТНЫЙ СЛУЧАЙ СТАТИСТИЧЕСКОГО РЕШЕНИЯ. ОСНОВНЫЕ ПОНЯТИЯ И ОПРЕДЕЛЕНИЯ
Сформулируем задачу построения оценок. Рассмотрим случайный вектор X, плотность распределения которого имеет известную математическую форму, но содержит некоторое число неизвестных параметров. Задана выборка измеренных значений компонент этого вектора, в дальнейшем называемая вектором измерений У.
Если, например, измерены N раз т компонент n-мерного вектора X, то вектор Y будет включать N×m компонент. Вектор Y также является случайным, так как содержит так называемые ошибки измерения  , плотность распределения которых считается известной. Требуется, используя вектор измерения У, получить оценки неизвестных параметров плотности распределения X и определить точность этих оценок.
, плотность распределения которых считается известной. Требуется, используя вектор измерения У, получить оценки неизвестных параметров плотности распределения X и определить точность этих оценок.
Важно уметь сравнивать свойства различных оценок одного и того же параметра и, в частности, находить оценки максимальной точности. Точность оценок определяем на основе статистических характеристик отклонений оценок от неизвестных «истинных значений» оцениваемых параметров. Плотность распределения X, характеризуемую истинными значениями оцениваемых параметров, называем «истинной».
Данная постановка задачи определения оценок называется статистической и является в настоящее время наиболее широко распространенной в технических задачах. В то же время существуют и другие постановки задач оценивания, когда нельзя сделать никаких предположений о распределении оцениваемой величины. Подобная ситуация рассматривается отдельно.
Вернемся к статистической задаче оценивания. Введем некоторые определения.
Функцию значений оцениваемой величины, т. е. функцию измерений, в дальнейшем будем называть статистикой. Простейшей •статистикой является, таким образом, сам вектор измерений У. Оценка  случайного вектора X, полученная на основе измерений У, т. е. (Y), также является статистикой. Если статистика содержит.всю необходимую эмпирическую информацию для построения распределения X, то она называется достаточной.
случайного вектора X, полученная на основе измерений У, т. е. (Y), также является статистикой. Если статистика содержит.всю необходимую эмпирическую информацию для построения распределения X, то она называется достаточной.
Если оценка сходится по вероятности к оцениваемой величине X при неограниченном возрастании объема выборки, т. е. размерности вектора У, то она называется состоятельной.
Оценка вектора X является несмещенной, если математические ожидания X и совпадают.
Рассмотрим теперь понятие оптимальной оценки. Введем функцию потерь (или функцию штрафов) С.
Как правило, это скалярная функция аргументов х я  . Наиболее употребительной функцией потерь является квадратичная:
. Наиболее употребительной функцией потерь является квадратичная:

где D — симметричная положительно определенная матрица.
Кроме квадратичной могут быть построены функции потерь следующего вида [6]:

где  — дельта-функция;
— дельта-функция;

Как уже указывалось, X — случайный вектор. Оценка также случайна хотя бы уже вследствие того, что она строится на основе случайного вектора У. Следовательно,  —функция случайных аргументов. Поэтому для сравнения оценок между собой и выбора наилучшей необходимо рассматривать статистические характеристики функции потерь, так называемые функции риска.
—функция случайных аргументов. Поэтому для сравнения оценок между собой и выбора наилучшей необходимо рассматривать статистические характеристики функции потерь, так называемые функции риска.
Таких функций можно построить несколько. Наиболее употребительные функции риска следующие.
1. Средний или априорный риск:

где р(х, у) —плотность совместного распределения вероятностей векторов X и У.
Интегрирование в (3.3) ведется по области всех возможных значений X и У. В дальнейшем в подобных случаях не будем указывать пределов интегрирования; х я у — значения случайных векторов X и У. Записью (у) в (3.3) подчеркивает то обстоятельство, что оценка рассматривается как функция у. Если оценка (у) минимизирует функцию риска (3.3), то она называется оптимальной в смысле среднего риска. Средний риск (3.3) R( ) может быть представлен в виде
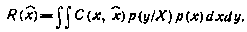
Если в качестве  выбрать функцию
выбрать функцию  , то с учетом свойств
, то с учетом свойств  -функции получим
-функции получим

откуда следует, что условие минимума среднего риска по х тождественно условию максимума  . Функция
. Функция  с точностью до коэффициента, не зависящего от х, совпадает с p(x/Y) — условной плотностью вероятностей вектора X при фиксированном векторе Y. Эту плотность вероятностей принято также называть апостериорной, т. е. полученной после опыта, в результате которого реализовался какой-то вектор у. В дальнейшем будем пользоваться, как правило, этим термином. Оценка , максимизирующая
с точностью до коэффициента, не зависящего от х, совпадает с p(x/Y) — условной плотностью вероятностей вектора X при фиксированном векторе Y. Эту плотность вероятностей принято также называть апостериорной, т. е. полученной после опыта, в результате которого реализовался какой-то вектор у. В дальнейшем будем пользоваться, как правило, этим термином. Оценка , максимизирующая  или, что то же самое,
или, что то же самое,  , называется оценкой максимума апостериорной вероятности, а сам метод оценивания'— методом максимума апостеориорной вероятности.
, называется оценкой максимума апостериорной вероятности, а сам метод оценивания'— методом максимума апостеориорной вероятности.
2. Байесовский риск:

где p(x/Y) —апостериорная плотность вероятностей значений X. при заданном (фиксированном) Y, р(х) —априорная плотность вероятностей вектора X, т. е. существующая до опыта, в котором реализовался какой-то вектор у. Таким образом, байесовский риск в силу структуры формулы Байеса (1.9) зависит не только от оценки, но и от априорной плотности вероятностей р(х), что и отражено в записи 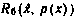 . Оценка
. Оценка  , минимизирующая функцию риска (3.4), называется оптимальной в байесовском смысле или просто ^байесовской. Доказано [11], что для функции потерь вида (3.1) байесовская оценка минимизирует одновременно функции риска (3.3) и (3.4). Алгоритмы оценивания, обеспечивающие получение •байесовских оценок, принято называть байесовскими.
, минимизирующая функцию риска (3.4), называется оптимальной в байесовском смысле или просто ^байесовской. Доказано [11], что для функции потерь вида (3.1) байесовская оценка минимизирует одновременно функции риска (3.3) и (3.4). Алгоритмы оценивания, обеспечивающие получение •байесовских оценок, принято называть байесовскими.
3. Условный риск:

Эта функция риска характеризует ошибки оценки при заданном (фиксированном) значении оцениваемого вектора X. Между условным и средним риском существует связь:

В (3.5) и (3.6) р(у/Х) и р(х) — соответственно условная плотность вероятностей вектора Y и априорная плотность вероятностей вектора X. На основе плотности вероятностей p(y/X) может быть построена оценка максимума правдоподобия. Это оценка, которая максимизирует так называемую функцию правдоподобия. В качестве функции правдоподобия в простейшем случае может быть выбрана функция р(у/Х), в которую подставлены фактические значения измерений у. Для построения р(у/Х) не обязательно знать вид плотности распределения р(х), т. е. вид априорной плотности вероятностей вектора X. Действительно, если известна функциональная связь между X и Y и вектором ошибок измерений , т. е.

а также плотность распределения р( ) вектора , то, зная вид функции  , можно определить р(у/Х). В таком случае в качестве оптимальной принимается такая оценка , которая обеспечивает наиболее вероятные значения у при данном х, т. е.
, можно определить р(у/Х). В таком случае в качестве оптимальной принимается такая оценка , которая обеспечивает наиболее вероятные значения у при данном х, т. е.

Эта оценка и называется оценкой максимума правдоподобия. Соответствующий алгоритм оценивания также называется алгоритмом максимального правдоподобия.
Особый класс оценок представляют так называемые минимаксные оценки. При построении минимаксных оценок предполагается, что вектор X, подлежащий оцениванию, не является случайным, а лишь принадлежит некоторому допустимому множеству  :
:

Оценка же по-прежнему случайна в силу случайности ошибок измерений , так что существует соответствующий условный риск  вида (3.5). В этом случае принцип минимакса применительно к задаче оценивания состоит в том, чтобы выбрать х из условия
вида (3.5). В этом случае принцип минимакса применительно к задаче оценивания состоит в том, чтобы выбрать х из условия

где  — минимаксная оценка. Соответствующий алгоритм оценивания называется минимаксным.
— минимаксная оценка. Соответствующий алгоритм оценивания называется минимаксным.
Таким образом, минимаксный подход заключается в выборе такой оценки, которая предохраняет от больших ошибок при произвольном изменении X на множестве .
Можно также сказать, что минимаксная оценка является байесовской при априорном распределении X, являющемся наименее благоприятным для задачи оценивания. Поясним последнюю мысль-подробнее.
Байесовский риск  может быть определен в том случае, если известен вид априорной плотности вероятностей р(х) вектора X, так как в силу (1.9) условная плотность вероятностей
может быть определен в том случае, если известен вид априорной плотности вероятностей р(х) вектора X, так как в силу (1.9) условная плотность вероятностей

где р(у) —плотность вероятностей вектора Y.
В том случае, когда плотность вероятностей р(х) не существует, можно условно поставить в соответствие каждому X из некоторое априорное распределение  , принадлежащее некоторому классу распределений
, принадлежащее некоторому классу распределений  .
.
Оказывается, для функции потерь вида (3.1) справедливо равенство [11]:

т. е. минимаксная оценка  тождественна байесовской оценке
тождественна байесовской оценке  вычисленной для априорного распределения, максимизирующего байесовский риск на
вычисленной для априорного распределения, максимизирующего байесовский риск на  . Таким образом устанавливается связь между байесовской и минимаксной оценками.
. Таким образом устанавливается связь между байесовской и минимаксной оценками.
3.2. БАЙЕСОВСКИЕ АЛГОРИТМЫ ОЦЕНИВАНИЯ
Как показывает практика, сложность реализации алгоритмов оценивания зависит, во-первых, от вида математической модели движения оцениваемой динамической системы и измерений и, во-вторых, от способа проведения измерений, т. е. от того, как поступают измерения, непрерывно или дискретно. Рассмотрим линейные (для линейных моделей), квазилинейные (для линеаризованных моделей) и нелинейные (для нелинейных моделей) байесовские алгоритмы. Как правило, будем полагать, что измерительная информация поступает дискретно и соответствующие алгоритмы имеют рекуррентную форму. Эта форма алгоритма наиболее удобна для реализации на ЭВМ, когда поступающие векторы измерений обрабатываются поочередно. В некоторых случаях удобно обобщить полученные результаты на случай непрерывных измерений.

