 2017-12-16
2017-12-16 1550
1550Декодирование циклического кода в режиме исправления ошибок можно осуществлять различными способами.
Ниже излагается способ, являющейся наиболее простым.
В основу этого способа положено использование таблицы синдромов, в которой каждому многочлену ошибок ei(x), соответствует определенный синдром Si(x), представляющий остаток от деления принятого кодового слова u’(x) и соответствующего ему ei(x) на g(x).
Процесс декодирования: принятое кодовое слово u’(x) делится на g(x), определяется Si(x) и соответствующий ему многочлен ei(x), а затем u’(x) суммируется с ei(x):

В результате получаем исправленное кодовое слово.
Структурная схема декодера, выполняющего рассмотренный алгоритм исправления ошибок, представлена на рисунке 2.6.
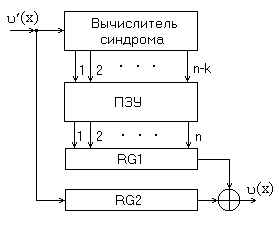
Рисунок 2.6 - Схема декодера
В состав декодера входят: вычислитель синдрома (ВС), два регистра сдвига RG1 и RG2, постоянное запоминающее устройство (ПЗУ), которое содержит  слова длины n, соответствующие многочленам ошибок ei(x).
слова длины n, соответствующие многочленам ошибок ei(x).
Принятое кодовое слово u’(x) поступает на вход вычислителя синдрома, где осуществляется деление его на g(x) и формирование Si(x), и одновременно на вход RG2, где накапливается u’(x). Синдром Si(x) используется в качестве адреса, по которому из ПЗУ в регистр RG1 записывается ei(x), соответствующий синдрому Si(x). Перечисленные операции завершаются за n тактов. В течение последующих n тактов происходит поэлементное суммирование содержимого RG1 и RG2, т.е реализуется операция - исправление ошибок.
Недостаток этого метода: большой объем фиксируемых в ПЗУ таблиц соответствия синдромов и многочленов ошибок.
Существуют методы основанные на специфических свойствах циклических кодов, которые позволяют уменьшить этот объем.
При декодировании мощных кодов способных исправлять многократные ошибки, применяются алгебраические методы, в основе которых лежит решение систем уравнений задающих расположение и значение ошибок.
Коды Рида-Соломона
Коды РС являются недвоичными циклическими кодами, символы кодовых слов которых берутся из конечного поля GF(q) где q степень некоторого простого числа, например q=2m.
РС - код построен над полем GF(8), которое является расширением поля GF(2) по модулю примитивного многочлена 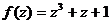 .
.
В этом случае символы кодовых слов кода могут быть представлены в виде обозначений, представленных в таблице.
Таблица - Таблица элементов поля
| Степени примитивного элемента | Многочленные представления | Двоичные представления | Десятичные представления |
| 0 | 0 | 000 | 0 |
| α7=α0=1 | 1 | 001 | 1 |
| α1 | z | 010 | 2 |
| α2 | z2 | 100 | 4 |
| α3 | z+1 | 011 | 3 |
| α4 | z2+z | 110 | 6 |
| α5 | z2+z+1 | 111 | 7 |
| α6 | z2+1 | 101 | 5 |
Кодовые слова РС - кода отображаются в виде многочленов:

где N – длина кода, Vi – q -ичные коэффициенты (символы кодовых слов), которые могут принимать любое значение из GF(q).
Эти коэффициенты как это следует из таблицы, также отображаются многочленами с двоичными коэффициентами:
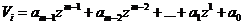
РС - коды являются максимальными, т.к. при длине кода N и информационной последовательности k они обладают наибольшим кодовым расстоянием:

Порождающим многочленом g(x) РС - кода является делитель двучлена (xN+1) степени меньшей N с коэффициентами из GF(q), корнями которого являются элементы этого поля  . a – примитивный элемент.
. a – примитивный элемент.
Выражение для порождающего многочлена РС - кода будет иметь вид:

Степень g(x) равна d-1=N-k=R.
В РС - кодах принадлежность кодовых слов множеству разрешенных комбинаций определяется выполнением (d-1) уравнений в соответствии с выражением:
 (*)
(*)
где m0=1, Vi – символы-коэффициенты поля GF(q), z0, z1…zN-1 – ненулевые элементы поля GF(q).
Элементы z0, z1…zN-1 называются локаторами, т.к. они указывают на номер позиции символа кодового слова.
Например, указателем i -той позиции является локатор zi, который может быть представлен в виде i -той степени ai примитивного элемента a поля GF(q):

Так как все локаторы должны быть различны и ненулевыми, то их число в поле GF(q) равно q-1. Следовательно, такое количество символов должно быть в кодовых словах кода. Поэтому обычно длина РС - кода определяется из выражения:

Пример:
Длина РС - кода равна N, кодовое расстояние d=3. В соответствии с (*) проверочными уравнениями будут:

Свойства РС - кодов:
1. Циклический сдвиг кодовых слов, символы которых принимают значение из поля GF(q), порождает новые кодовые слова этого же кода.
2. Сумма по mod2 двух и более кодовых слов дает кодовое слово, принадлежащее этому же коду.
3. Кодовое расстояние РС - кода определяется не по двоичным элементам, а по q -ичным символам.
4. В РС - коде, исправляющем tu ошибок, порождающий многочлен определяется из выражения:

Обычно m0=1. Однако, при других значениях m0, иногда можно упростить схему кодера.
5. Корректирующие способности РС - кода определяются его кодовым расстоянием:

где T0 и Tu – длина пакетов, в которых обнаруживаются T0 и исправляются Tu ошибок.
Обнаружение ошибок в кодовых словах состоит в проверке условия (*), т.е. определении синдрома S:
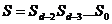
Элементы которого определяются из выражения:
 (**)
(**)
Процедура исправления ошибок в РС – коде является более сложной, чем в двоичном коде, поскольку, наряду с определение номера разряда, в котором допущена ошибка, необходимо определить значение ошибочно принятого символа.
Пример:
Сформировать кодовое слово РС – кода, исправляющего одиночные ошибки, над полем GF(23), соответствующее двоичной информационной последовательности a(1,0)=000000011100101.
Так как m=3, то каждый q -ичный символ кода состоит из трех двоичных элементов. Поэтому с учетом таблицы элементов поля:

Параметры кода.


Кодовое слово формируется в соответствии с выражением:

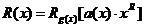

Так как  , то
, то  .
.


Нахождение синдромов.

В соответствие с уравнением (**):

Каскадные коды

