 2014-01-27
2014-01-27 1045
1045План лекции
1. Ранние подходы к организации БД
2. Системы, основанные на инвертированных списках
3. Иерархические СУБД
4. Сетевые СУБД
5. Сильные места и недостатки ранних систем
6. Реляционные СУБДПрежде, чем перейти к детальному и последовательному изучению реляционных систем БД, остановимся коротко на ранних (дореляционных) СУБД. В этом есть смысл по трем причинам: во-первых, эти системы исторически предшествовали реляционным, и для правильного понимания причин повсеместного перехода к реляционным системам нужно знать хотя бы что-нибудь про их предшественников; во-вторых, внутренняя организация реляционных систем во многом основана на использовании методов ранних систем; в-третьих, некоторое знание в области ранних систем будет полезно для понимания путей развития постреляционных СУБД.
Ограничиваемся рассмотрением только общих подходов к организации трех типов ранних систем, а именно, систем, основанных на инвертированных списках, иерархических и сетевых систем управления базами данных. Начнем с некоторых наиболее общих характеристик ранних систем:
a. Эти системы активно использовались в течение многих лет, дольше, чем используется какая-либо из реляционных СУБД. На самом деле некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование этих систем совместно с современными системами.
b. Все ранние системы не основывались на каких-либо абстрактных моделях. Как мы упоминали, понятие модели данных фактически вошло в обиход специалистов в области БД только вместе с реляционным подходом. Абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков у различных конкретных систем.
c. В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путем создания соответствующих прикладных программ с собственным интерфейсом.
d. Можно считать, что уровень средств ранних СУБД соотносится с уровнем файловых систем примерно так же, как уровень языка Кобол соотносится с уровнем языка Ассемблера. Заметим, что при таком взгляде уровень реляционных систем соответствует уровню языков Ада.
e. Навигационная природа ранних систем и доступ к данным на уровне записей заставляли пользователя самого производить всю оптимизацию доступа к БД, без какой-либо поддержки системы.
f. После появления реляционных систем большинство ранних систем было оснащено "реляционными" интерфейсами. Однако в большинстве случаев это не сделало их по-настоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме.
Основные особенности систем, основанных на инвертированных списках
К числу наиболее известных и типичных представителей таких систем относятся Datacom/DB компании Applied Data Research, Inc. (ADR), ориентированная на использование на машинах основного класса фирмы IBM; и Adabas компании Software AG.
Организация доступа к данным на основе инвертированных списков используется практически во всех современных реляционных СУБД, но в этих системах пользователи не имеют непосредственного доступа к инвертированным спискам (индексам). Кстати, когда мы будем рассматривать внутренние интерфейсы реляционных СУБД, вы увидите, что они очень близки к пользовательским интерфейсам систем, основанных на инвертированных списках.
Структуры данных
База данных, организованная с помощью инвертированных списков, похожа на реляционную БД, но с тем отличием, что хранимые таблицы и пути доступа к ним видны пользователям. При этом:
a. Строки таблиц упорядочены системой в некоторой физической последовательности.
b. Физическая упорядоченность строк всех таблиц может определяться и для всей БД (так делается, например, в Datacom/DB).
c. Для каждой таблицы можно определить произвольное число ключей поиска, для которых строятся индексы. Эти индексы автоматически поддерживаются системой, но явно видны пользователям.
Манипулирование данными
Поддерживаются два класса операторов:
- Операторы, устанавливающие адрес записи, среди которых:
* прямые поисковые операторы (например, найти первую запись таблицы по некоторому пути доступа);
* операторы, находящие запись в терминах относительной позиции от предыдущей записи по некоторому пути доступа.
b. операторы над адресуемыми записями
Типичный набор операторов:
* LOCATE FIRST - найти первую запись таблицы T в физическом порядке; возвращает адрес записи;
* LOCATE FIRST WITH SEARCH KEY EQUAL - найти первую запись таблицы T с заданным значением ключа поиска K; возвращает адрес записи;
* LOCATE NEXT - найти первую запись, следующую за записью с заданным адресом в заданном пути доступа; возвращает адрес записи;
* LOCATE NEXT WITH SEARCH KEY EQUAL - найти cледующую запись таблицы T в порядке пути поиска с заданным значением K; должно быть соответствие между используемым способом сканирования и ключом K; возвращает адрес записи;
* LOCATE FIRST WITH SEARCH KEY GREATER - найти первую запись таблицы T в порядке ключа поиска K cо значением ключевого поля, большим заданного значения K; возвращает адрес записи;
* RETRIVE - выбрать запись с указанным адресом;
* UPDATE - обновить запись с указанным адресом;
* DELETE - удалить запись с указанным адресом;
* STORE - включить запись в указанную таблицу; операция генерирует адрес записи.
Ограничения целостности
Общие правила определения целостности БД отсутствуют. В некоторых системах поддерживаются ограничения уникальности значений некоторых полей, но в основном все возлагается на прикладную программу.
Иерархические системы
Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г.
Иерархические структуры данных
Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева.
Тип дерева состоит из одного "корневого" типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи.
Пример типа дерева (схемы иерархической БД):
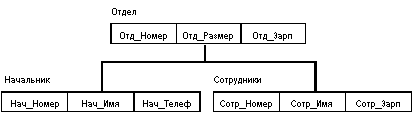
Здесь Отдел является предком для Начальник и Сотрудники, а Начальник и Сотрудники - потомки Отдел. Между типами записи поддерживаются связи.
База данных с такой схемой могла бы выглядеть следующим образом:
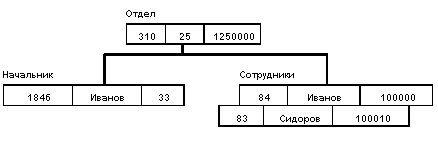
Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для БД определен полный порядок обхода - сверху-вниз, слева-направо.
В IMS использовалась оригинальная и нестандартная терминология: "сегмент" вместо "запись", а под "записью БД" понималось все дерево сегментов.
Манипулирование данными
Примерами типичных операторов манипулирования иерархически организованными данными могут быть следующие:
* Найти указанное дерево БД (например, отдел 310);
* Перейти от одного дерева к другому;
* Перейти от одной записи к другой внутри дерева (например, от отдела - к первому сотруднику);
* Перейти от одной записи к другой в порядке обхода иерархии;
* Вставить новую запись в указанную позицию;
* Удалить текущую запись.
Ограничения целостности
Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается.
В иерархических системах поддерживалась некоторая форма представлений БД на основе ограничения иерархии. Примером представления приведенной выше БД может быть иерархия
Сетевые системы
Типичным представителем является Integrated Database Management System (IDMS) компании Cullinet Software, Inc., предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем.
Сетевые структуры данных
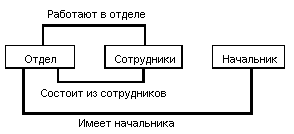
Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков.
Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи.
Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
* Каждый экземпляр типа P является предком только в одном экземпляре L;
* Каждый экземпляр C является потомком не более, чем в одном экземпляре L.
На формирование типов связи не накладываются особые ограничения; возможны, например, следующие ситуации:
a. Тип записи потомка в одном типе связи L1 может быть типом записи предка в другом типе связи L2 (как в иерархии).
b. Данный тип записи P может быть типом записи предка в любом числе типов связи.
c. Данный тип записи P может быть типом записи потомка в любом числе типов связи.
d. Может существовать любое число типов связи с одним и тем же типом записи предка и одним и тем же типом записи потомка; и если L1 и L2 - два типа связи с одним и тем же типом записи предка P и одним и тем же типом записи потомка C, то правила, по которым образуется родство, в разных связях могут различаться.
e. Типы записи X и Y могут быть предком и потомком в одной связи и потомком и предком - в другой.
f. Предок и потомок могут быть одного типа записи.
Простой пример сетевой схемы БД:
Достоинства и недостатки
Сильные места ранних СУБД:
* Развитые средства управления данными во внешней памяти на низком уровне;
* Возможность построения вручную эффективных прикладных систем;
* Возможность экономии памяти за счет разделения подобъектов (в сетевых системах).
Недостатки:
* Слишком сложно пользоваться;
* Фактически необходимы знания о физической организации;
* Прикладные системы зависят от этой организации;
* Их логика перегружена деталями организации доступа к БД.
Реляционные базы данных
Этот подход является наиболее распространенным в настоящее время, хотя наряду с общепризнанными достоинствами обладает и рядом недостатков. К числу достоинств реляционного подхода можно отнести:
* наличие небольшого набора абстракций, которые позволяют сравнительно просто моделировать большую часть распространенных предметных областей и допускают точные формальные определения, оставаясь интуитивно понятными;
* наличие простого и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных;
* возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти.
Реляционные системы далеко не сразу получили широкое распространение. В то время, как основные теоретические результаты в этой области были получены еще в 70-х, и тогда же появились первые прототипы реляционных СУБД, долгое время считалось невозможным добиться эффективной реализации таких систем. Однако отмеченные выше преимущества и постепенное накопление методов и алгоритмов организации реляционных баз данных и управления ими привели к тому, что уже в середине 80-х годов реляционные системы практически вытеснили с мирового рынка ранние СУБД. Все основные теоретические положения реляционной модели данных предложены Е.Ф. Коддом.
В настоящее время основным предметом критики реляционных СУБД является не их недостаточная эффективность, а присущая этим системам некоторая ограниченность (прямое следствие простоты) при использование в так называемых нетрадиционных областях (наиболее распространенными примерами являются системы автоматизации проектирования), в которых требуются предельно сложные структуры данных. Еще одним часто отмечаемым недостатком реляционных баз данных является невозможность адекватного отражения семантики предметной области. Другими словами, возможности представления знаний о семантической специфике предметной области в реляционных системах очень ограничены. Современные исследования в области постреляционных систем главным образом посвящены именно устранению этих недостатков.
Манипулирование данными
Примерный набор операций может быть следующим:
* Найти конкретную запись в наборе однотипных записей (инженера Сидорова);
* Перейти от предка к первому потомку по некоторой связи (к первому сотруднику отдела 310);
* Перейти к следующему потомку в некоторой связи (от Сидорова к Иванову);
* Перейти от потомка к предку по некоторой связи (найти отдел Сидорова);
* Создать новую запись;
* Уничтожить запись;
* Модифицировать запись;
* Включить в связь;
* Исключить из связи;
* Переставить в другую связь и т.д.
Ограничения целостности
В принципе их поддержание не требуется, но иногда требуют целостности по ссылкам (как в иерархической модели).
Базовые понятия реляционных баз данных
Основными понятиями реляционных баз данных являются тип данных, домен, атрибут, кортеж, первичный ключ и отношение.
Для начала покажем смысл этих понятий на примере отношения СОТРУДНИКИ, содержащего информацию о сотрудниках некоторой организации:
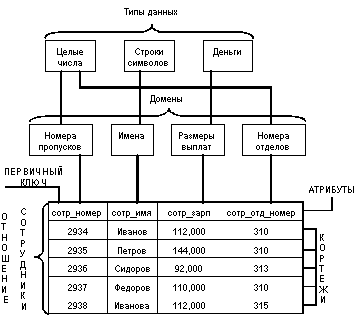
Тип данных
Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как "деньги"), а также специальных "темпоральных" данных (дата, время, временной интервал). Достаточно активно развивается подход к расширению возможностей реляционных систем абстрактными типами данных (соответствующими возможностями обладают, например, системы семейства Ingres/Postgres). В нашем примере мы имеем дело с данными трех типов: строки символов, целые числа и "деньги".
Домен
Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с подтипами в некоторых языках программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат "истина", то элемент данных является элементом домена.
Наиболее правильной интуитивной трактовкой понятия домена является понимание его как допустимого потенциального множества значений данного типа. Например, домен "Имена" в нашем примере определен на базовом типе строк символов, но в число его значений могут входить только те строки, которые могут изображать имя (в частности, такие строки не могут начинаться с мягкого знака).
Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. В нашем примере значения доменов "Номера пропусков" и "Номера групп" относятся к типу целых чисел, но не являются сравнимыми. Заметим, что в большинстве современных реляционных СУБД понятие домена не используется, хотя в Oracle v.7 оно уже поддерживается.
Схема отношения, схема базы данных
Схема отношения - это именованное множество пар {имя атрибута, имя домена (или типа, если понятие домена не поддерживается)}. Степень или "арность" схемы отношения есть мощность этого множества. Степень отношения СОТРУДНИКИ равна четырем, то есть оно является 4-арным. Если все атрибуты одного отношения определены на разных доменах, осмысленно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута).
Схема БД (в структурном смысле) - это набор именованных схем отношений.
Кортеж, отношение
Кортеж, соответствующий данной схеме отношения, - это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. "Значение" является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым, степень или "арность" кортежа, т.е. число элементов в нем, совпадает с "арностью" соответствующей схемы отношения. Попросту говоря, кортеж - это набор именованных значений заданного типа.
Отношение - это множество кортежей, соответствующих одной схеме отношения. Иногда, чтобы не путаться, говорят "отношение-схема" и "отношение-экземпляр", иногда схему отношения называют заголовком отношения, а отношение как набор кортежей - телом отношения. На самом деле, понятие схемы отношения ближе всего к понятию структурного типа данных в языках программирования. Было бы вполне логично разрешать отдельно определять схему отношения, а затем одно или несколько отношений с данной схемой.
Однако в реляционных базах данных это не принято. Имя схемы отношения в таких базах данных всегда совпадает с именем соответствующего отношения-экземпляра. В классических реляционных базах данных после определения схемы базы данных изменяются только отношения-экземпляры. В них могут появляться новые и удаляться или модифицироваться существующие кортежи. Однако во многих реализациях допускается и изменение схемы базы данных: определение новых и изменение существующих схем отношения. Это принято называть эволюцией схемы базы данных.
Обычным житейским представлением отношения является таблица, заголовком которой является схема отношения, а строками - кортежи отношения-экземпляра; в этом случае имена атрибутов именуют столбцы этой таблицы. Поэтому иногда говорят "столбец таблицы", имея в виду "атрибут отношения". Этой терминологии придерживаются в большинстве коммерческих реляционных СУБД.
Реляционная база данных - это набор отношений, имена которых совпадают с именами схем отношений в схеме БД.
Как видно, основные структурные понятия реляционной модели данных (если не считать понятия домена) имеют очень простую интуитивную интерпретацию, хотя в теории реляционных БД все они определяются абсолютно формально и точно.
Остановимся теперь на некоторых важных свойствах отношений, которые следуют из приведенных ранее определений:
Отсутствие кортежей-дубликатов
То свойство, что отношения не содержат кортежей-дубликатов, следует из определения отношения как множества кортежей. В классической теории множеств по определению каждое множество состоит из различных элементов.
Из этого свойства вытекает наличие у каждого отношения так называемого первичного ключа - набора атрибутов, значения которых однозначно определяют кортеж отношения. Для каждого отношения по крайней мере полный набор его атрибутов обладает этим свойством. Однако при формальном определении первичного ключа требуется обеспечение его "минимальности", т.е. в набор атрибутов первичного ключа не должны входить такие атрибуты, которые можно отбросить без ущерба для основного свойства - однозначно определять кортеж. Понятие первичного ключа является исключительно важным в связи с понятием целостности баз данных.
Можно заметить, что во многих практических реализациях РСУБД допускается нарушение свойства уникальности кортежей для промежуточных отношений, порождаемых неявно при выполнении запросов. Такие отношения являются не множествами, а мультимножествами, что в ряде случаев позволяет добиться определенных преимуществ, но иногда приводит к серьезным проблемам.
Отсутствие упорядоченности кортежей
Свойство отсутствия упорядоченности кортежей отношения также является следствием определения отношения-экземпляра как множества кортежей. Отсутствие требования к поддержанию порядка на множестве кортежей отношения дает дополнительную гибкость СУБД при хранении баз данных во внешней памяти и при выполнении запросов к базе данных. Это не противоречит тому, что при формулировании запроса к БД, например, на языке SQL можно потребовать сортировки результирующей таблицы в соответствии со значениями некоторых столбцов. Такой результат, вообще говоря, не отношение, а некоторый упорядоченный список кортежей.
Отсутствие упорядоченности атрибутов
Атрибуты отношений не упорядочены, поскольку по определению схема отношения есть множество пар {имя атрибута, имя домена}. Для ссылки на значение атрибута в кортеже отношения всегда используется имя атрибута. Это свойство теоретически позволяет, например, модифицировать схемы существующих отношений не только путем добавления новых атрибутов, но и путем удаления существующих атрибутов. Однако в большинстве существующих систем такая возможность не допускается, и хотя упорядоченность набора атрибутов отношения явно не требуется, часто в качестве неявного порядка атрибутов используется их порядок в линейной форме определения схемы отношения.
Атомарность значений атрибутов
Значения всех атрибутов являются атомарными. Это следует из определения домена как потенциального множества значений простого типа данных, т.е. среди значений домена не могут содержаться множества значений (отношения). Принято говорить, что в реляционных базах данных допускаются только нормализованные отношения или отношения, представленные в первой нормальной форме. Потенциальным примером ненормализованного отношения является следующее:
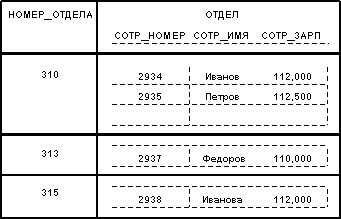
Можно сказать, что здесь мы имеем бинарное отношение, значениями атрибута ОТДЕЛЫ которого являются отношения. Заметим, что исходное отношение СОТРУДНИКИ является нормализованным вариантом отношения ОТДЕЛЫ:
СОТР_НОМЕР
СОТР_ИМЯ
СОТР_ЗАРП
СОТР_ОТД_НОМЕР
Иванов
112,000
Петров
144,000
Сидоров
92,000
Федоров
110,000
Иванова
112,000
Нормализованные отношения составляют основу классического реляционного подхода к организации баз данных. Они обладают некоторыми ограничениями (не любую информацию удобно представлять в виде плоских таблиц), но существенно упрощают манипулирование данными. Рассмотрим, например, два идентичных оператора занесения кортежа:
Зачислить сотрудника Кузнецова (пропуск номер 3000, зарплата 115,000) в отдел номер 320 и
Зачислить сотрудника Кузнецова (пропуск номер 3000, зарплата 115,000) в отдел номер 310.
Если информация о сотрудниках представлена в виде отношения СОТРУДНИКИ, оба оператора будут выполняться одинаково (вставить кортеж в отношение СОТРУДНИКИ). Если же работать с ненормализованным отношением ОТДЕЛЫ, то первый оператор выразится в занесение кортежа, а второй - в добавление информации о Кузнецове в множественное значение атрибута ОТДЕЛ кортежа с первичным ключом 310.
Реляционная модель данных
Рассуждения, приведенные выше, в равной степени относились к любой системе, при построении которой использовался реляционный подход. Используются понятия так называемой реляционной модели данных. Модель данных описывает некоторый набор родовых понятий и признаков, которыми должны обладать все конкретные СУБД и управляемые ими базы данных, если они основываются на этой модели. Наличие модели данных позволяет сравнивать конкретные реализации, используя один общий язык.
Хотя понятие модели данных является общим, и можно говорить о иерархической, сетевой, некоторой семантической и т.д. моделях данных, нужно отметить, что это понятие было введено в обиход применительно к реляционным системам и наиболее эффективно используется именно в этом контексте. Попытки прямолинейного применения аналогичных моделей к дореляционным организациям показывают, что реляционная модель слишком "велика" для них, а для постреляционных организаций она оказывается "мала".
Общая характеристика
Наиболее распространенная трактовка реляционной модели данных, по-видимому, принадлежит Дейту, который воспроизводит ее (с различными уточнениями) практически во всех своих книгах. Согласно Дейту реляционная модель состоит из трех частей, описывающих разные аспекты реляционного подхода: структурной части, манипуляционной части и целостной части.
В структурной части модели фиксируется, что единственной структурой данных, используемой в реляционных БД, является нормализованное n-арное отношение. По сути дела, в предыдущих двух разделах этой лекции мы рассматривали именно понятия и свойства структурной составляющей реляционной модели.
В манипуляционной части модели утверждаются два фундаментальных механизма манипулирования реляционными БД - реляционная алгебра и реляционное исчисление. Первый механизм базируется в основном на классической теории множеств (с некоторыми уточнениями), а второй - на классическом логическом аппарате исчисления предикатов первого порядка. Мы рассмотрим эти механизмы более подробно на следующей лекции, а пока лишь заметим, что основной функцией манипуляционной части реляционной модели является обеспечение меры реляционности любого конкретного языка реляционных БД: язык называется реляционным, если он обладает не меньшей выразительностью и мощностью, чем реляционная алгебра или реляционное исчисление.
Целостность сущности и ссылок
Наконец, в целостной части реляционной модели данных фиксируются два базовых требования целостности, которые должны поддерживаться в любой реляционной СУБД. Первое требование называется требованием целостности сущностей. Объекту или сущности реального мира в реляционных БД соответствуют кортежи отношений. Конкретно требование состоит в том, что любой кортеж любого отношения отличим от любого другого кортежа этого отношения, т.е. другими словами, любое отношение должно обладать первичным ключом. Как мы видели в предыдущем разделе, это требование автоматически удовлетворяется, если в системе не нарушаются базовые свойства отношений.
Второе требование называется требованием целостности по ссылкам и является несколько более сложным. Очевидно, что при соблюдении нормализованности отношений сложные сущности реального мира представляются в реляционной БД в виде нескольких кортежей нескольких отношений. Например, представим, что нам требуется представить в реляционной базе данных сущность ОТДЕЛ с атрибутами ОТД_НОМЕР (номер отдела), ОТД_КОЛ (количество сотрудников) и ОТД_СОТР (набор сотрудников отдела). Для каждого сотрудника нужно хранить СОТР_НОМЕР (номер сотрудника), СОТР_ИМЯ (имя сотрудника) и СОТР_ЗАРП (заработная плата сотрудника). Как мы вскоре увидим, при правильном проектировании соответствующей БД в ней появятся два отношения: ОТДЕЛЫ (ОТД_НОМЕР, ОТД_КОЛ) (первичный ключ - ОТД_НОМЕР) и СОТРУДНИКИ (СОТР_НОМЕР, СОТР_ИМЯ, СОТР_ЗАРП, СОТР_ОТД_НОМ) (первичный ключ - СОТР_НОМЕР).
Как видно, атрибут СОТР_ОТД_НОМ появляется в отношении СОТРУДНИКИ не потому, что номер отдела является собственным свойством сотрудника, а лишь для того, чтобы иметь возможность восстановить при необходимости полную сущность ОТДЕЛ. Значение атрибута СОТР_ОТД_НОМ в любом кортеже отношения СОТРУДНИКИ должно соответствовать значению атрибута ОТД_НОМ в некотором кортеже отношения ОТДЕЛЫ. Атрибут такого рода называется внешним ключом, поскольку его значения однозначно характеризуют сущности, представленные кортежами некоторого другого отношения (т.е. задают значения их первичного ключа). Говорят, что отношение, в котором определен внешний ключ, ссылается на соответствующее отношение, в котором такой же атрибут является первичным ключом.
Требование целостности по ссылкам, или требование внешнего ключа состоит в том, что для каждого значения внешнего ключа, появляющегося в ссылающемся отношении, в отношении, на которое ведет ссылка, должен найтись кортеж с таким же значением первичного ключа, либо значение внешнего ключа должно быть неопределенным (т.е. ни на что не указывать). Для нашего примера это означает, что если для сотрудника указан номер отдела, то этот отдел должен существовать.
Ограничения целостности сущности и по ссылкам должны поддерживаться СУБД. Для соблюдения целостности сущности достаточно гарантировать отсутствие в любом отношении кортежей с одним и тем же значением первичного ключа. С целостностью по ссылкам дела обстоят несколько более сложно.
Понятно, что при обновлении ссылающегося отношения (вставке новых кортежей или модификации значения внешнего ключа в существующих кортежах) достаточно следить за тем, чтобы не появлялись некорректные значения внешнего ключа. Но как быть при удалении кортежа из отношения, на которое ведет ссылка?
Здесь существуют три подхода, каждый из которых поддерживает целостность по ссылкам. Первый подход заключается в том, что запрещается производить удаление кортежа, на который существуют ссылки (т.е. сначала нужно либо удалить ссылающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа). При втором подходе при удалении кортежа, на который имеются ссылки, во всех ссылающихся кортежах значение внешнего ключа автоматически становится неопределенным. Наконец, третий подход (каскадное удаление) состоит в том, что при удалении кортежа из отношения, на которое ведет ссылка, из ссылающегося отношения автоматически удаляются все ссылающиеся кортежи.
В развитых реляционных СУБД обычно можно выбрать способ поддержания целостности по ссылкам для каждой отдельной ситуации определения внешнего ключа. Конечно, для принятия такого решения необходимо анализировать требования конкретной прикладной области.
Лекция 9 ЛОГИЧЕСКОЕ ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ (продолжение)
План лекции
1. РЕЛЯЦИОННАЯ MОДЕЛЬ ДАННЫХ
1. РЕЛЯЦИОННАЯ MОДЕЛЬ ДАННЫХ
Концепция реляционной модели данных (РМД) была предложена Е.Ф.Коддом в 1970 г. В основе РМД лежит понятие "отношение" Отношение удобно представляется в виде двумерной таблицы. Столбцы отношения называются атрибутами и им присваиваются имена. Список имен атрибутов называется схемой отношения. Реляционная база данных (РБД) - это набор взаимосвязанных отношений (таблиц). Каждое отношение в ЭВМ представляется в виде файла. Имеем следующее соответствие ранее введенных понятий:
Файл
Таблица
Отношение
Объект (сущность)
Запись
Строка
Кортеж
Экземпляр
Поле
Столбец
Атрибут
Атрибут
Таблицы обозримы, понятны, привычны для человека, но не учитывает необходимости согласования трех способов манипулирования данными: упорядочение, группировку по значению индексов доступ по дереву параметров. В таблице упорядоченные по одному параметру данные не упорядочены по другому, что усложняет поиск. Кодд предложил применять к отношениям стройную систему операций, позволяющую получать (выводить, вычислять) одни отношения из других. Это дает возможность делить информацию на хранимую и не хранимую (вычисляемую) части, экономить память, при необходимости вычисляя нехранимую часть информации из хранимой. Основными операциями над отношениями в РБД являются следующие: объединение, пересечение, разность, декартово произведение, деление, проекция, соединение, выбор (селекция, ограничение). Эффективность конкретной СУБД определяется наличием и удобством использования средств выполнения этих операций.
Языки для выполнения операций над отношениями в реляционной СУБД делятся на два класса: языки реляционной алгебры (ЯРА); языки реляционного исчисления (ЯРИ).
ЯРА основаны на реляционной алгебре (алгебра Кодда, альфа-алгебра). Записывая последовательности операций над отношениями в соответствующем порядке, можно получить желаемый результат. Поэтому ЯРА называются процедурными. Большинство языков СУБД являются таковыми процедурными языками программирования.
ЯРИ основаны на классическом исчислении предикатов. Они представляют пользователю набор правил для записи запросов к БД. В таком запросе содержится лишь информация о желаемом результате. На основании запроса СУБД автоматически, путем формирования новых отношений, выдает желаемый результат.
Первый ЯРИ ALFА был разработан Коддом. В настоящее время в реляционных СУБД широкое распространение получил язык запросов SQL (Structured Query Language), разработанный фирмой IBM. В частности, СУБД dBase IУ фирмы Ashton -Tate построена на основе языка SQL. Почти все СУБД персональных компьютеров поддерживают реляционную модель данных.
Отношения РБД в зависимости от содержания могут быть объектными (хранят данные об объектах и экземплярах объектов) и связные (хранят ключи двух или более объектных отношений).
В объектном отношении один из атрибутов однозначно идентифицирует отдельный объект и называется ключом отношения или первичным (ключевым) атрибутом. Остальные атрибуты функционально зависят от этого ключа. Ключ может быть составным (включать несколько атрибутов) или частичным (быть частью значения атрибута).
По ключам связного отношения устанавливаются связи между объектами отношений.
Например, пусть БД имеет объектные отношения СТУДЕНТ (Ф.И.О, КУРС, СПЕЦИАЛЬНОСТЬ) и ПРЕДМЕТ (НАЗВАНИЕ, ЧИСЛО ЧАСОВ) со следующими данными
СТУДЕНТ


ПРЕДМЕТ
Название
Число часов
Тогда связное отношение ИЗУЧАЕТ может содержать такие данные:
ИЗУЧАЕТ

Связное отношение, кроме связываемых ключей, может иметь и другие атрибуты, которые функционально зависят от этой связи. На пример, можно иметь отношение ИЗУЧАЕТ (СТУДЕНТ,ПРЕДМЕТ, ОЦЕНКА, СЕМЕСТР).
Ключи в связных отношениях называются внешними (посторонними) ключами, поскольку являются первичными ключами других отношений. Каждому внешнему ключу должна соответствовать строка какого-либо объектного отношения (ограничение ссылочной целостности данных).
В РБД каждое отношение должно быть нормализовано, т.е. каждый атрибут должен быть простым (содержать атомарные, надежные значения). Для этого сложные атрибуты, например: ДЕТАЛЬ (ШИФР, ЦЕНА), надо превратить в простые введением самостоятельных столбцов (ШИФР, ДЕТАЛИ, ЦЕНА).
На отношения РМД накладываются следующие условия и ограничения, которые позволяют таблицы считать отношениями.
1. Не может быть одинаковых первичных ключей, т.е. все строки (записи) таблицы должны быть уникальны.
2. Все строки таблицы должны иметь одну и ту же структуру, т.е. одно и то же количество атрибутов с соответственно совпадающими именами.
3. Имена столбцов должны быть, различны, а значения столбцов должны быть однородными (однотипными).
4. Значения атрибутов должны быть атомарными, следовательно отношения не могут иметь в качестве компонент другие отношения.
5. Должна соблюдаться ссылочная целостность внешних ключей, т.е. каждому внешнему ключу должна соответствовать строка какого-либо объектного отношения.
6. Порядок следования строк в таблице несуществен, т.к. влияет лишь на скорость доступа к строке.
Основной единицей обработки в операциях РМД является отношение (а не отдельные ее записи, как это пропято в традиционных языках обработки данных). Степенью отношения называется число входящих в него атрибутов. Мощностью (кардинальным числом) отношения называется число кортежей (строк) отношения. При выполнении некоторых операций отношения должны иметь совместимые схемы, т.е. иметь одинаковую степень и одинаковые типы соответствующих атрибутов.
Рассмотрим на примерах восемь операций алгебры отношений. Объединение выполняется над двумя совместимыми отношениями. Результат объединения включает все кортежи первого отношения и все кортежи из второго отношения (список 3, рис. 7.1). Результат пересечения содержит только те кортежи первого отношения, которые есть во втором (описок 4, рис.7.1). Результат вычитания включает только те кортежи первого отношения, которых нет во втором (список 6, рис. 7. 1).

Рис. 7.1. Табличное представление результатов объединения, пересечения и вычитания над исходными отношениями СПИСОК 1 и СПИСОК 2
В декартовом произведении отношения (операнды) могут иметь разные схемы. Степень результирующего отношения равна сумме степеней отношений операндов, а мощность - произведению их мощностей (рис. 7.2).
При делении результирующее отношение содержит только те атрибуты делимого, которых нет в делителе. В него включают только те кортежи, декартовы произведения которых с делителем содержатся в делимом (рис.7.3). 
Рис.7.2. Декартово произведение над отношениями СТУДЕНТЫ и ЭКЗАМЕНЫ

Рис. 7.3 Пример операции деления
Операция проекции выполняется над одним отношением на некоторые атрибуты. Результирующее отношение включает часть атрибутов исходного, на которые выполняется проекция (например, НОМЕР ОТДЕЛА и ДОЛЖНОСТЬ). Кортежи-дубликаты отсутствуют (рис. 7.4)
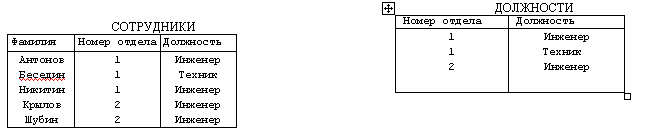
Рис. 7.4. Пример операции проекции
Операция соединения выполняется над двумя отношениями. В каждом отношении выделяется атрибут, по которому будет производиться соединение. Результирующее отношение включает все атрибуты первого и второго отношений (рис. 7.5).
Рис. 7.5. Пример операции соединения
Операция выбора выполняется над одним отношением. Результирующее отношение содержит подмножества кортежей, выбранных по некоторому условию, например, ВОЗРАСТ > 22 лет (рис. 7.6).

Рис. 7.6. Пример операции выбора
Рассмотренные выше операции позволяют выделить из отношений их подмножества, при необходимости снова объединять эти подмножества в более "крупные" отношения, обновлять содержимое отношений и представлять их в требуемом виде. Однако при выполнении операций обновления над отношениями БД могут возникать побочные эффекты, если между атрибутами отношений существуют нежелательные функциональные зависимости. Устранение побочных эффектов достигается нормализацией отношений БД, т.е. рациональной группировкой атрибутов в отношениях.
Лекция 10 ЛОГИЧЕСКОЕ ПРОЕКТИРОВАНИЕ БАЗ ДАННЫХ (продолжение)
Проектирование реляционных БД с использованием нормализации
При проектировании базы данных решаются две основных проблемы:
* Каким образом отобразить объекты предметной области в абстрактные объекты модели данных, чтобы это отображение не противоречило семантике предметной области и было по возможности лучшим (эффективным, удобным и т.д.)? Часто эту проблему называют проблемой логического проектирования баз данных.
* Как обеспечить эффективность выполнения запросов к базе данных, т.е. каким образом, имея в виду особенности конкретной СУБД, расположить данные во внешней памяти, создание каких дополнительных структур (например, индексов) потребовать и т.д.? Эту проблему называют проблемой физического проектирования баз данных.
Более того, мы не будем касаться очень важного аспекта проектирования - определения ограничений целостности (за исключением ограничения первичного ключа). Дело в том, что при использовании СУБД с развитыми механизмами ограничений целостности (например, SQL-ориентированных систем) трудно предложить какой-либо общий подход к определению ограничений целостности. Эти ограничения могут иметь очень общий вид, и их формулировка пока относится скорее к области искусства, чем инженерного мастерства. Самое большее, что предлагается по этому поводу в литературе, это автоматическая проверка непротиворечивости набора ограничений целостности.
Так что будем считать, что проблема проектирования реляционной базы данных состоит в обоснованном принятии решений о том,
* из каких отношений должна состоять БД и
* какие атрибуты должны быть у этих отношений.
Проектирование реляционных баз данных с использованием нормализации
Сначала будет рассмотрен классический подход, при котором весь процесс проектирования производится в терминах реляционной модели данных методом последовательных приближений к удовлетворительному набору схем отношений. Исходной точкой является представление предметной области в виде одного или нескольких отношений, и на каждом шаге проектирования производится некоторый набор схем отношений, обладающих лучшими свойствами. Процесс проектирования представляет собой процесс нормализации схем отношений, причем каждая следующая нормальная форма обладает свойствами лучшими, чем предыдущая.
Каждой нормальной форме соответствует некоторый определенный набор ограничений, и отношение находится в некоторой нормальной форме, если удовлетворяет свойственному ей набору ограничений. Примером набора ограничений является ограничение первой нормальной формы - значения всех атрибутов отношения атомарны. Поскольку требование первой нормальной формы является базовым требованием классической реляционной модели данных, мы будем считать, что исходный набор отношений уже соответствует этому требованию.
В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм:
* первая нормальная форма (1NF);
* вторая нормальная форма (2NF);
* третья нормальная форма (3NF);
* нормальная форма Бойса-Кодда (BCNF);
* четвертая нормальная форма (4NF);
* пятая нормальная форма, или нормальная форма проекции-соединения (5NF или PJ/NF).
Основные свойства нормальных форм:
* каждая следующая нормальная форма в некотором смысле лучше предыдущей;
* при переходе к следующей нормальной форме свойства предыдущих нормальных свойств сохраняются.
В основе процесса проектирования лежит метод нормализации, декомпозиция отношения, находящегося в предыдущей нормальной форме, в два или более отношения, удовлетворяющих требованиям следующей нормальной формы.
Наиболее важные на практике нормальные формы отношений основываются на фундаментальном в теории реляционных баз данных понятии функциональной зависимости. Для дальнейшего изложения нам потребуются несколько определений.
Определение 1. Функциональная зависимость
В отношении R атрибут Y функционально зависит от атрибута X (X и Y могут быть составными) в том и только в том случае, если каждому значению X соответствует в точности одно значение Y: R.X (r) R.Y.
Определение 2. Полная функциональная зависимость
Функциональная зависимость R.X (r) R.Y называется полной, если атрибут Y не зависит функционально от любого точного подмножества X.
Определение 3. Транзитивная функциональная зависимость
Функциональная зависимость R.X -> R.Y называется транзитивной, если существует такой атрибут Z, что имеются функциональные зависимости R.X -> R.Z и R.Z -> R.Y и отсутствует функциональная зависимость R.Z --> R.X. (При отсутствии последнего требования мы имели бы "неинтересные" транзитивные зависимости в любом отношении, обладающем несколькими ключами.)
Определение 4. Неключевой атрибут
Неключевым атрибутом называется любой атрибут отношения, не входящий в состав первичного ключа (в частности, первичного).
Определение 5. Взаимно независимые атрибуты
Два или более атрибута взаимно независимы, если ни один из этих атрибутов не является функционально зависимым от других.
Вторая нормальная форма
Рассмотрим следующий пример схемы отношения:
СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ
(СОТР_НОМЕР, СОТР_ЗАРП, ОТД_НОМЕР, ПРО_НОМЕР, СОТР_ЗАДАН)
Первичный ключ:
СОТР_НОМЕР, ПРО_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР -> СОТР_ЗАРП
СОТР_НОМЕР -> ОТД_НОМЕР
ОТД_НОМЕР -> СОТР_ЗАРП
СОТР_НОМЕР, ПРО_НОМЕР -> СОТР_ЗАДАН
Как видно, хотя первичным ключом является составной атрибут СОТР_НОМЕР, ПРО_НОМЕР, атрибуты СОТР_ЗАРП и ОТД_НОМЕР функционально зависят от части первичного ключа, атрибута СОТР_НОМЕР. В результате мы не сможем вставить в отношение СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ кортеж, описывающий сотрудника, который еще не выполняет никакого проекта (первичный ключ не может содержать неопределенное значение). При удалении кортежа мы не только разрушаем связь данного сотрудника с данным проектом, но утрачиваем информацию о том, что он работает в некотором отделе. При переводе сотрудника в другой отдел мы будем вынуждены модифицировать все кортежи, описывающие этого сотрудника, или получим несогласованный результат. Такие неприятные явления называются аномалиями схемы отношения. Они устраняются путем нормализации.
Определение 6. Вторая нормальная форма (в этом определении предполагается, что единственным ключом отношения является первичный ключ)
Отношение R находится во второй нормальной форме (2NF) в том и только в том случае, когда находится в 1NF, и каждый неключевой атрибут полностью зависит от первичного ключа.
Можно произвести следующую декомпозицию отношения СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ в два отношения СОТРУДНИКИ-ОТДЕЛЫ и СОТРУДНИКИ-ПРОЕКТЫ:
СОТРУДНИКИ-ОТДЕЛЫ (СОТР_НОМЕР, СОТР_ЗАРП, ОТД_НОМЕР)
Первичный ключ:
СОТР_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР -> СОТР_ЗАРП
СОТР_НОМЕР -> ОТД_НОМЕР
ОТД_НОМЕР -> СОТР_ЗАРП
СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО_НОМЕР, СОТР_ЗАДАН)
Первичный ключ:
СОТР_НОМЕР, ПРО_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР, ПРО_НОМЕР -> CОТР_ЗАДАН
Каждое из этих двух отношений находится в 2NF, и в них устранены отмеченные выше аномалии (легко проверить, что все указанные операции выполняются без проблем).
Если допустить наличие нескольких ключей, то определение 6 примет следующий вид:
Определение 6~
Отношение R находится во второй нормальной форме (2NF) в том и только в том случае, когда оно находится в 1NF, и каждый неключевой атрибут полностью зависит от каждого ключа R.
Здесь и далее мы не будем приводить примеры для отношений с несколькими ключами. Они слишком громоздки и относятся к ситуациям, редко встречающимся на практике.
Третья нормальная форма
Рассмотрим еще раз отношение СОТРУДНИКИ-ОТДЕЛЫ, находящееся в 2NF. Заметим, что функциональная зависимость СОТР_НОМЕР -> СОТР_ЗАРП является транзитивной; она является следствием функциональных зависимостей СОТР_НОМЕР -> ОТД_НОМЕР и ОТД_НОМЕР -> СОТР_ЗАРП. Другими словами, заработная плата сотрудника на самом деле является характеристикой не сотрудника, а отдела, в котором он работает (это не очень естественное предположение, но достаточное для примера).
В результате мы не сможем занести в базу данных информацию, характеризующую заработную плату отдела, до тех пор, пока в этом отделе не появится хотя бы один сотрудник (первичный ключ не может содержать неопределенное значение). При удалении кортежа, описывающего последнего сотрудника данного отдела, мы лишимся информации о заработной плате отдела. Чтобы согласованным образом изменить заработную плату отдела, мы будем вынуждены предварительно найти все кортежи, описывающие сотрудников этого отдела. Т.е. в отношении СОТРУДИКИ-ОТДЕЛЫ по-прежнему существуют аномалии. Их можно устранить путем дальнейшей нормализации.
Определение 7. Третья нормальная форма. (Снова определение дается в предположении существования единственного ключа.)
Отношение R находится в третьей нормальной форме (3NF) в том и только в том случае, если находится в 2NF и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
Можно произвести декомпозицию отношения СОТРУДНИКИ-ОТДЕЛЫ в два отношения СОТРУДНИКИ и ОТДЕЛЫ:
СОТРУДНИКИ (СОТР_НОМЕР, ОТД_НОМЕР)
Первичный ключ:
СОТР_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР -> ОТД_НОМЕР
ОТДЕЛЫ (ОТД_НОМЕР, СОТР_ЗАРП)
Первичный ключ:
ОТД_НОМЕР
Функциональные зависимости:
ОТД_НОМЕР -> СОТР_ЗАРП
Каждое из этих двух отношений находится в 3NF и свободно от отмеченных аномалий.
Если отказаться от того ограничения, что отношение обладает единственным ключом, то определение 3NF примет следующую форму:
Определение 7~
Отношение R находится в третьей нормальной форме (3NF) в том и только в том случае, если находится в 1NF, и каждый неключевой атрибут не является транзитивно зависимым от какого-либо ключа R.
На практике третья нормальная форма схем отношений достаточна в большинстве случаев, и приведением к третьей нормальной форме процесс проектирования реляционной базы данных обычно заканчивается. Однако иногда полезно продолжить процесс нормализации.
Нормальная форма Бойса-Кодда
Рассмотрим следующий пример схемы отношения:
СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, СОТР_ИМЯ, ПРО_НОМЕР, СОТР_ЗАДАН)
Возможные ключи:
СОТР_НОМЕР, ПРО_НОМЕР
СОТР_ИМЯ, ПРО_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР -> CОТР_ИМЯ
СОТР_НОМЕР -> ПРО_НОМЕР
СОТР_ИМЯ -> CОТР_НОМЕР
СОТР_ИМЯ -> ПРО_НОМЕР
СОТР_НОМЕР, ПРО_НОМЕР -> CОТР_ЗАДАН
СОТР_ИМЯ, ПРО_НОМЕР -> CОТР_ЗАДАН
В этом примере мы предполагаем, что личность сотрудника полностью определяется как его номером, так и именем (это снова не очень жизненное предположение, но достаточное для примера).
В соответствии с определением 7~ отношение СОТРУДНИКИ-ПРОЕКТЫ находится в 3NF. Однако тот факт, что имеются функциональные зависимости атрибутов отношения от атрибута, являющегося частью первичного ключа, приводит к аномалиям. Например, для того, чтобы изменить имя сотрудника с данным номером согласованным образом, нам потребуется модифицировать все кортежи, включающие его номер.
Определение 8. Детерминант
Детерминант - любой атрибут, от которого полностью функционально зависит некоторый другой атрибут.
Определение 9. Нормальная форма Бойса-Кодда
Отношение R находится в нормальной форме Бойса-Кодда (BCNF) в том и только в том случае, если каждый детерминант является возможным ключом.
Очевидно, что это требование не выполнено для отношения СОТРУДНИКИ-ПРОЕКТЫ. Можно произвести его декомпозицию к отношениям СОТРУДНИКИ и СОТРУДНИКИ-ПРОЕКТЫ:
СОТРУДНИКИ (СОТР_НОМЕР, СОТР_ИМЯ)
Возможные ключи:
СОТР_НОМЕР
СОТР_ИМЯ
Функциональные зависимости:
СОТР_НОМЕР -> CОТР_ИМЯ
СОТР_ИМЯ -> СОТР_НОМЕР
СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО_НОМЕР, СОТР_ЗАДАН)
Возможный ключ:
СОТР_НОМЕР, ПРО_НОМЕР
Функциональные зависимости:
СОТР_НОМЕР, ПРО_НОМЕР -> CОТР_ЗАДАН
Возможна альтернативная декомпозиция, если выбрать за основу СОТР_ИМЯ. В обоих случаях получаемые отношения СОТРУДНИКИ и СОТРУДНИКИ-ПРОЕКТЫ находятся в BCNF, и им не свойственны отмеченные аномалии.
Четвертая нормальная форма
Рассмотрим пример следующей схемы отношения:
ПРОЕКТЫ (ПРО_НОМЕР,ПРО_СОТР, ПРО_ЗАДАН)
Отношение ПРОЕКТЫ содержит номера проектов, для каждого проекта список сотрудников, которые могут выполнять проект, и список заданий, предусматриваемых проектом. Сотрудники могут участвовать в нескольких проектах, и разные проекты могут включать одинаковые задания.
Каждый кортеж отношения связывает некоторый проект с сотрудником, участвующим в этом проекте, и заданием, который сотрудник выполняет в рамках данного проекта (мы предполагаем, что любой сотрудник, участвующий в проекте, выполняет все задания, предусмотренные этим проектом). По причине сформулированных выше условий единственным возможным ключем отношения является составной атрибут ПРО_НОМЕР, ПРО_СОТР, ПРО_ЗАДАН, и нет никаких других детерминантов. Следовательно, отношение ПРОЕКТЫ находится в BCNF. Но при этом оно обладает недостатками: если, например, некоторый сотрудник присоединяется к данному проекту, необходимо вставить в отношение ПРОЕКТЫ столько кортежей, сколько заданий в нем предусмотрено.
Определение 10. Многозначные зависимости
В отношении R (A, B, C) существует многозначная зависимость R.A -> -> R.B в том и только в том случае, если множество значений B, соответствующее паре значений A и C, зависит только от A и не зависит от С.
В отношении ПРОЕКТЫ существуют следующие две многозначные зависимости:
ПРО_НОМЕР -> -> ПРО_СОТР
ПРО_НОМЕР -> -> ПРО_ЗАДАН
Легко показать, что в общем случае в отношении R (A, B, C) существует многозначная зависимость R.A -> -> R.B в том и только в том случае, когда существует многозначная зависимость R.A -> -> R.C.
Дальнейшая нормализация отношений, подобных отношению ПРОЕКТЫ, основывается на следующей теореме:
Теорема Фейджина
Отношение R (A, B, C) можно спроецировать без потерь в отношения R1 (A, B) и R2 (A, C) в том и только в том случае, когда существует MVD A -> -> B | C.
Под проецированием без потерь понимается такой способ декомпозиции отношения, при котором исходное отношение полностью и без избыточности восстанавливается путем естественного соединения полученных отношений.
Определение 11. Четвертая нормальная форма
Отношение R находится в четвертой нормальной форме (4NF) в том и только в том случае, если в случае существования многозначной зависимости A -> -> B все остальные атрибуты R функционально зависят от A.
В нашем примере можно произвести декомпозицию отношения ПРОЕКТЫ в два отношения ПРОЕКТЫ-СОТРУДНИКИ и ПРОЕКТЫ-ЗАДАНИЯ:
ПРОЕКТЫ-СОТРУДНИКИ (ПРО_НОМЕР, ПРО_СОТР)
ПРОЕКТЫ-ЗАДАНИЯ (ПРО_НОМЕР, ПРО_ЗАДАН)
Оба эти отношения находятся в 4NF и свободны от отмеченных аномалий.
Пятая нормальная форма
Во всех рассмотренных до этого момента нормализациях производилась декомпозиция одного отношения в два. Иногда это сделать не удается, но возможна декомпозиция в большее число отношений, каждое из которых обладает лучшими свойствами.
Рассмотрим, например, отношение
СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ (СОТР_НОМЕР, ОТД_НОМЕР, ПРО_НОМЕР)
Предположим, что один и тот же сотрудник может работать в нескольких отделах и работать в каждом отделе над несколькими проектами. Первичным ключем этого отношения является полная совокупность его атрибутов, отсутствуют функциональные и многозначные зависимости.
Поэтому отношение находится в 4NF. Однако в нем могут существовать аномалии, которые можно устранить путем декомпозиции в три отношения.
Определение 12. Зависимость соединения
Отношение R (X, Y,..., Z) удовлетворяет зависимости соединения * (X, Y,..., Z) в том и только в том случае, когда R восстанавливается без потерь путем соединения своих проекций на X, Y,..., Z.
Определение 13. Пятая нормальная форма
Отношение R находится в пятой нормальной форме (нормальной форме проекции-соединения - PJ/NF) в том и только в том случае, когда любая зависимость соединения в R следует из существования некоторого возможного ключа в R.
Введем следующие имена составных атрибутов:
СО = {СОТР_НОМЕР, ОТД_НОМЕР}
СП = {СОТР_НОМЕР, ПРО_НОМЕР}
ОП = {ОТД_НОМЕР, ПРО_НОМЕР}
Предположим, что в отношении СОТРУДНИКИ-ОТДЕЛЫ-ПРОЕКТЫ существует зависимость соединения:
* (СО, СП, ОП)
На примерах легко показать, что при вставках и удалениях кортежей могут возникнуть проблемы. Их можно устранить путем декомпозиции исходного отношения в три новых отношения:
СОТРУДНИКИ-ОТДЕЛЫ (СОТР_НОМЕР, ОТД_НОМЕР)
СОТРУДНИКИ-ПРОЕКТЫ (СОТР_НОМЕР, ПРО_НОМЕР)
ОТДЕЛЫ-ПРОЕКТЫ (ОТД_НОМЕР, ПРО_НОМЕР)
Пятая нормальная форма - это последняя нормальная форма, которую можно получить путем декомпозиции. Ее условия достаточно нетривиальны, и на практике 5NF не используется. Заметим, что зависимость соединения является обобщением как многозначной зависимости, так и функциональной зависимости.








