 2014-01-27
2014-01-27 851
851План лекции
Банки данных. Структура БнД. Компоненты БнД.
Уровни абстракции. Архитектура БнД. Основные этапы проектирования
1. Банки данных
Представим структуру БнД в виде следующей схемы на рис.1.
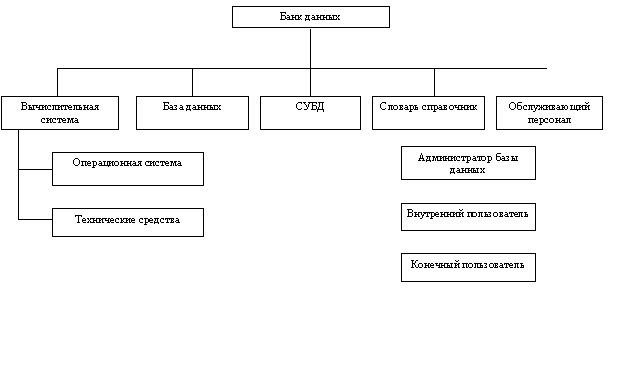
Рис. 1.
Основу БнД составляет БД.
БД – совокупность данных, отражающая динамическое состояние объектов и их отношений в рассматриваемой предметной области.
Предметная область – часть реального мира, подлежащая изучению с целью организации управления и в конечном счете автоматизации.
Например, это может быть предприятие, библиотека и т.д.
Основные требования к БД:
1) должны иметь минимальную избыточность,
2) динамически обновляться,
3) данные не должны зависеть от программ (описание данных не в программе, а в БД).
Современный подход требует, чтобы в программе были лишь перечислены необходимые данные, заданы форматы без учета физического представления данных, при такой организации описание БД независимо от пользователей. В ряде современных систем эти описания, а также информация о пользователях и некоторые др. сведения хранятся в словаре-справочнике.
Словарь-справочник
Словарь данных – это централизованное хранилище сведений об объектах, составляющих их элементах данных, взаимосвязях между объектами, их источниках, значении, использовании и форматах представления.
Словарь-справочник является инструментом управления при проектировании БД. Он позволяет при проектировании, эксплуатации и развитии БД поддерживать и контролировать информацию о данных. Цель его создания: помощь разработчику при совместном использовании данных, при вводе в систему новых элементов или изменении существующих, для уменьшения избыточности и противоречивости и т.д.
Помимо перечисленных в определении сведений об объектах и их описаний словарь-справочник может также содержать информацию о физическом местоположении данных (например, для распределенных БД), кодах защиты, статистические сведения по работе с БД и т.д.
Одно из главных назначений состоит в документировании данных. На первых этапах разработки готовятся описания элементов на естественном языке (чтобы не совпадали названия, что является входным, что выходным и т.д.). Далее он все более расширяется.
Словарь данных называют метабазой. Организован как БД, но содержит специфические сведения об элементах проектируемой БД.
Можно вести словарь данных «вручную на бумаге», однако неавтоматизированный словарь не может обеспечить необходимой информацией, сложно корректировать, сложность доступа к нему и, как правило, процесс проектирования становится трудно управляемым.
Для успешного применения словаря данных требуется его автоматизация. Идеально, если создание и ведение словаря обеспечивается СУБД. В этом случае БД, СУБД и словарь данных образуют единый замкнутый контур. При изменении типов данных привлекается словарь, средствами СУБД проводится проверка корректности изменений и только после этого допускается обновление.
За ведение и сохранность словаря отвечает администратор БД.
СУБД
СУБД – совокупность языковых и программных средств, предназначенных для создания, ведения и использования БД одним или несколькими пользователями.
Главная роль СУБД – это обеспечения пользователя инструментарием, позволяющим оперировать данными в абстрактных терминах, не связанных с физическим представлением данных. СУБД – это комплекс программ, служащий интерфейсом между пользователем и хранимыми данными. В этом смысле СУБД можно сравнить с интерпретатором языка высокого уровня (Си, Паскаль).
СУБД должна выполнять и ряд других функций:
Непосредственное управление данными во внешней памяти
Эта функция включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы). В некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но подчеркнем, что в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД.
Управление буферами оперативной памяти
СУБД обычно работают с БД значительного размера; по крайней мере этот размер обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти. При этом, даже если операционная система производит общесистемную буферизацию (как в случае ОС UNIX), этого недостаточно для целей СУБД, которая располагает гораздо большей информацией о полезности буферизации той или иной части БД. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов.
Заметим, что существует отдельное направление СУБД, которое ориентировано на постоянное присутствие в оперативной памяти всей БД. Это направление основывается на предположении, что в будущем объем оперативной памяти компьютеров будет настолько велик, что позволит не беспокоиться о буферизации. Пока эти работы находятся в стадии исследований.
Управление транзакциями
Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует (COMMIT) изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД. Если вспомнить наш пример информационной системы с файлами СОТРУДНИКИ и ОТДЕЛЫ, то единственным способом не нарушить целостность БД при выполнении операции приема на работу нового сотрудника является объединение элементарных операций над файлами СОТРУДНИКИ и ОТДЕЛЫ в одну транзакцию. Таким образом, поддержание механизма транзакций является обязательным условием даже однопользовательских СУБД (если, конечно, такая система заслуживает названия СУБД). Но понятие транзакции гораздо более важно в многопользовательских СУБД.
То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый из пользователей может в принципе ощущать себя единственным пользователем СУБД (на самом деле, это несколько идеализированное представление, поскольку в некоторых случаях пользователи многопользовательских СУБД могут ощутить присутствие своих коллег).
С управлением транзакциями в многопользовательской СУБД связаны важные понятия сериализации транзакций и сериального плана выполнения смеси транзакций. Под сериализаций параллельно выполняющихся транзакций понимается такой порядок планирования их работы, при котором суммарный эффект смеси транзакций эквивалентен эффекту их некоторого последовательного выполнения. Сериальный план выполнения смеси транзакций - это такой план, который приводит к сериализации транзакций. Понятно, что если удается добиться действительно сериального выполнения смеси транзакций, то для каждого пользователя, по инициативе которого образована транзакция, присутствие других транзакций будет незаметно (если не считать некоторого замедления работы по сравнению с однопользовательским режимом).
Существует несколько базовых алгоритмов сериализации транзакций. В централизованных СУБД наиболее распространены алгоритмы, основанные на синхронизационных захватах объектов БД. При использовании любого алгоритма сериализации возможны ситуации конфликтов между двумя или более транзакциями по доступу к объектам БД. В этом случае для поддержания сериализации необходимо выполнить откат (ликвидировать все изменения, произведенные в БД) одной или более транзакций. Это один из случаев, когда пользователь многопользовательской СУБД может реально (и достаточно неприятно) ощутить присутствие в системе транзакций других пользователей.
Журнализация
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции.
Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД.
Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД журнализуются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), иногда - минимальной внутренней операции модификации страницы внешней памяти; в некоторых системах одновременно используются оба подхода.
Во всех случаях придерживаются стратегии "упреждающей" записи в журнал (так называемого протокола Write Ahead Log - WAL). Грубо говоря, эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Известно, что если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя.
Самая простая ситуация восстановления - индивидуальный откат транзакции. Строго говоря, для этого не требуется общесистемный журнал изменений БД. Достаточно для каждой транзакции поддерживать локальный журнал операций модификации БД, выполненных в этой транзакции, и производить откат транзакции путем выполнения обратных операций, следуя от конца локального журнала. В некоторых СУБД так и делают, но в большинстве систем локальные журналы не поддерживают, а индивидуальный откат транзакции выполняют по общесистемному журналу, для чего все записи от одной транзакции связывают обратным списком (от конца к началу).
При мягком сбое во внешней памяти основной части БД могут находиться объекты, модифицированные транзакциями, не закончившимися к моменту сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования буферов оперативной памяти, содержимое которых при мягком сбое пропадает). При соблюдении протокола WAL во внешней памяти журнала должны гарантированно находиться записи, относящиеся к операциям модификации обоих видов объектов. Целью процесса восстановления после мягкого сбоя является состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций. Для того, чтобы этого добиться, сначала производят откат незавершенных транзакций (undo), а потом повторно воспроизводят (redo) те операции завершенных транзакций, результаты которых не отображены во внешней памяти. Этот процесс содержит много тонкостей, связанных с общей организацией управления буферами и журналом. Более подробно мы рассмотрим это в соответствующей лекции.
Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Грубо говоря, архивная копия - это полная копия БД к моменту начала заполнения журнала (имеется много вариантов более гибкой трактовки смысла архивной копии). Конечно, для нормального восстановления БД после жесткого сбоя необходимо, чтобы журнал не пропал. Как уже отмечалось, к сохранности журнала во внешней памяти в СУБД предъявляются особо повышенные требования. Тогда восстановление БД состоит в том, что исходя из архивной копии по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя. В принципе, можно даже воспроизвести работу незавершенных транзакций и продолжить их работу после завершения восстановления. Однако в реальных системах это обычно не делается, поскольку процесс восстановления после жесткого сбоя является достаточно длительным.
Поддержка языков БД
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка - язык определения схемы БД (SDL - Schema Definition Language, чаще встречается аббревиатура DDl – Data Definition Language, язык описания данных) и язык манипулирования данными (DML - Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т.е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные. Мы рассмотрим более подробно языки ранних СУБД в следующей лекции.
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language). В нескольких лекциях этого курса язык SQL будет рассматриваться достаточно подробно, а пока мы перечислим основные функции реляционной СУБД, поддерживаемые на "языковом" уровне (т.е. функции, поддерживаемые при реализации интерфейса SQL).
Прежде всего, язык SQL сочетает средства SDL и DML, т.е. позволяет определять схему реляционной БД и манипулировать данными. При этом именование объектов БД (для реляционной БД - именование таблиц и их столбцов) поддерживается на языковом уровне в том смысле, что компилятор языка SQL производит преобразование имен объектов в их внутренние идентификаторы на основании специально поддерживаемых служебных таблиц-каталогов. Внутренняя часть СУБД (ядро) вообще не работает с именами таблиц и их столбцов.
Язык SQL содержит специальные средства определения ограничений целостности БД. Опять же, ограничения целостности хранятся в специальных таблицах-каталогах, и обеспечение контроля целостности БД производится на языковом уровне, т.е. при компиляции операторов модификации БД компилятор SQL на основании имеющихся в БД ограничений целостности генерирует соответствующий программный код.
Специальные операторы языка SQL позволяют определять так называемые представления БД, фактически являющиеся хранимыми в БД запросами (результатом любого запроса к реляционной БД является таблица) с именованными столбцами. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в БД, но с помощью представлений можно ограничить или наоборот расширить видимость БД для конкретного пользователя. Поддержание представлений производится также на языковом уровне.
Наконец, авторизация доступа к объектам БД производится также на основе специального набора операторов SQL. Идея состоит в том, что для выполнения операторов SQL разного вида пользователь должен обладать различными полномочиями. Пользователь, создавший таблицу БД, обладает полным набором полномочий для работы с этой таблицей. В число этих полномочий входит полномочие на передачу всех или части полномочий другим пользователям, включая полномочие на передачу полномочий. Полномочия пользователей описываются в специальных таблицах-каталогах, контроль полномочий поддерживается на языковом уровне.
Более точное описание возможных реализаций этих функций на основе языка SQL будет приведено в лекциях, посвященных языку SQL и его реализации.
Пользователи
Пользователей БнД условно можно разделить на две группы: внутренние и конечные.
Внутренние пользователи разрабатывают ИС и поддерживают ее функционирование. Это администратор БД (АБД), администраторы подсистем, системные и прикладные программисты.
Конечные пользователи – это потребители готовой ИС. Сюда же относятся и пользователи, которые не общаются с ЭВМ непосредственно, а формулируют свои запросы АБД, получают ответы на бумаге.
АБД
Особую роль при проектировании и обслуживании БД играет лицо или группа лиц, называемых АБД. Это лицо ответственное за функционирование БнД.
АБД – это лицо (или группа лиц), реализующее управление БД (ее администрирование).
АБД можно сравнить с ревизором. Ревизор на предприятии отвечает за денежные ресурсы, их сохранность и т.д., а АБД – за данные.
Функции АБД:
1) разработка структур данных и взаимосвязей между ними для эффективной работы с ИС различными пользователями, согласование представлений пользователей – администрирование БД;
2) координировать все действия по проектированию, реализации и ведения БД; следить, что БД удовлетворяла актуальными информационным потребностям;
3) решать вопросы, связанные с изменением БД (например, расширением границ предметной области, изменением методов доступа и т.д.);
4) разрабатывать и реализовывать меры по обеспечению секретности и защиты данных от сбоев;
5) выполнять работы по ведению словаря данных;
6) координировать вопросы тех. обеспечения, исходя из требований БД;
7) координировать работу системных программистов (разрабатывающих доп. ПО для улучшения работы СУБД) и прикладных программистов, выполнять проверку нового ПО.
Т.о., АБД – это именно то лицо, с помощью которого осуществляется централизованное управление БД.
Часто считается АБД должен быть квалифицированный технический специалист, часто совмещающий функции программиста. Однако, АБД должен быть специалистом во многих сферах: он должен хорошо представлять себе всю структуру предприятия, его функционирование, как оно использует данные (менеджер). Кроме того АБД должен уметь общаться с людьми, координировать их, решать конфликты, т.е. быть психологом. АБД не только является руководителем проекта на этапе проектирования, но и должен постоянно сопровождать БД, следить за ее состоянием и ПО.
Вычислительная техника
Это понятие включает в себя все тех. средства (ЭВМ, принтеры и т.д.) и программное обеспечение (ОС, драйверы устройств и т.д.), необходимые для нормального функционирования БнД.
Понятие архитектуры БнД тесно связано с его проектированием, т.к. основано на уровнях абстрагирования предметной области.
Очевидно, что существует множество уровней абстракций между реальным (физическим) представлением данных в ЭВМ, имеющим дело с байтами и битами, и конечным пользователем, имеющим свое абстрактное мнение о предметной области (например, список рейсов самолетов с кол-вом свободных мест).
Обычно уровни абстракции отражают в след. схеме:
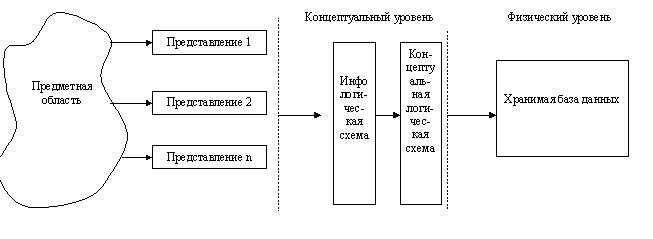
Рис. 2.
Одну и ту же предметную область разные пользователи видят по-разному, на разных уровнях абстракции.
Представления о предметной области (особенно, если она велика) отображаются в сознании нескольких пользователей в виде лог. представлений. Например, при создании ИС «Диспетчер авиарейсов» предметная область по-разному представляется кассиру, диспетчеру рейсов, отв. за тех. обеспечение (начальник ангара) и т.д. Для кассира понятие авиарейса связано с номером рейса, часами и датой вылета, прилета, пункта назначения, кол-вом свободных мест, данными пассажира; Для диспетчера то же понятие авиарейса связано с номером рейса, номером самолета, пилотами и стюардессами; для начальника ангара наибольший интерес представляют номер самолета, тип, данные тех. осмотра, пилоты. Видно, что, в основном, их представления о предметной области совсем разные, их интересуют разные данные, хотя некоторые из них могут и пересекаться (например, номер рейса, данные о пилотах).
Множество различных представлений пользователей АБД собирает в единое представление всей предметной области (отбираются именно те данные, которые необходимы, объединяются, так чтобы не было противоречий и между ними устанавливаются взаимосвязи). Общее представление о предметной области находится на концептуальном уровне. Понятие “концептуальный” подчеркивает, что это единое глобальное представление предметной области. На концептуальном уровне абстракции различают два возможных представления БД: инфологическая схема предметной области и концептуальная логическая схема предметной области.
Понятие “инфологический” указывает на то, что это представление предметной области существует в некоторой общей информационной терминологии, без привязки к конкретной технической системе и СУБД. На этом уровне определяются лишь информационные потребности разрабатываемой системы, отражающие особенности предметной области, но не затрагиваются вопросы представления данных в памяти ЭВМ.
Концептуальная логическая схема – это след. уровень представлений, когда инфологическую схему расширяют, привязывая к средствам реализации – конкретной СУБД. На этом уровне говорят о модели данных.
Физический уровень соответствует физ. представлению БД. В современных СУБД этот уровень абстракции доступен только самой СУБД и частично АБД.
Лекция 5 МОДЕЛИ ДАННЫХ (продолжение)
План лекции
1. СЕТЕВАЯ MОДЕЛЬ ДАННЫХ
2. ИЕРАРХИЧЕСКАЯ МОДЕЛЬ ДАННЫХ
1. СЕТЕВАЯ MОДЕЛЬ ДАННЫХ
Сетевые модели данных базируются на использовании графовой формы представления данных. Вершины графа используются для интерпретации типов объектов. При реализации вершины графа представляются совокупностью описаний экземпляров объемов соответствующего типа. Дуги графа (связи между вершинами) используются для интерпретации типов связей между типами объектов. Такое изображение структуры БД называется диаграммой Бохмана.
Сетевые МОД и соответствующие СУБД построены на основе предложений КОДАСИЛ с основными типами структур данных: элемент, агрегат, запись, набор, база. МОД допускает существование записей с простой (только из элементов) в сложной внутренней структурой.
Во втором случае запись имеет многоуровневую древовидную иерархическую структуру с использованием агрегатов. Типы наборов используются в МОД для представления типов связей между типами объектов и изображаются поименованной дугой, которая исходит из типа записи - владельца набора и заходит в тип записи - члена набора.
В модели КОДАСИЛ основным внутренним ограничением целостности является функциональная связь, т.е. с помощью наборов можно реализовать непосредственно связи типа 1:1, 1:М, М:1. В модели это внутреннее ограничение выражается утверждением: в конкретном экземпляре набора экземпляр записи - члена набора может иметь не более одного экземпляра записи - владельца набора. Отсюда следует второе внутреннее ограничение целостности - экземпляр записи может быть членом только одного экземпляра набора среди всех экземпляров набора одного типа (он может входить в состав двух и более экземпляров наборов, но разных типов).
Для представления связи типа М:М вводят вспомогательный тип записи и две функциональные связи типа 1:М (рис. 1).
Еще одно внутреннее ограничение сетевой МОД - невозможность непосредственного представления данных, описывающих связи (между объектами), имеющие собственные атрибуты. В этом случае вводится вспомогательный тип записи.
Рис. 1. Пример представления связи типа "многие ко многим"
В модели можно представлять типы связей, заданных между несколькими типами объектов. Для этого используют многочленные наборы, которые представляют собой отношение между тремя или более типами записей, один из которых назначается владельцем набора, а остальные – членами набора (рис. 2)
Рис.2. Пример многочленного набора
В модели КОДАСИЛ еще сингулярный набор, владельцем которого является система. При его реализации возможен только один экземпляр набора этого типа. Это тип набора без записи – владельца (рис. 3).
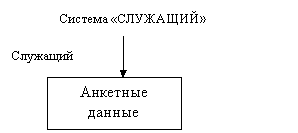
Рис.3. Пример сингулярного типа набора
Сингулярный набор можно использовать для создания традиционного файла, состоящего из однотипных записей. Количество объявляемых сингулярных наборов произвольно. Один и тот же тип записи может быть объявлен членом сингулярного набора и одновременно владельцем либо членом других наборов. Сингулярный набор объявляется обычно для записи владельца набора, чтобы получить доступ ко всем экземплярам записей - владельцев некоторого типа, а следовательно, и ко всем экземплярам набора соответствующего типа (владельцем которого этот тип записи является).
Любой вводимый в схему БД тип набора представляет приклад-ному программисту соответствующий путь доступа к специфицированным в этом наборе записям. Необходимость введения какого-либо типа набора в схему БД полностью определяется необходимостью реализации соответствующего пути доступа к данным в БД.
Эталонный вариант сетевой модели данных впервые был описан в проекте КОДАСИЛ. Сетевые (и, как частный случай, иерархические)СУБД получили наибольшее распространение на больших и мини-ЭВМ. Для отечественных ЭВМ создано несколько СУБД, поддерживающих сетевые модели данных: система СЕТЬ, реализующая под-множество предложений КОДАСИЛ: система БАНК, родственная зарубежной системе IDS; системы семейства СЕТОР, имеющие версии для ЭВМ разных классов.
2. ИЕРАРХИЧЕСКАЯ МОДЕЛЬ ДАННЫХ
Здесь структура данных также определяется в терминах сетевой модели (элемент, агрегат, запись, групповое отношение, база данных) для графического обозначения структур используют диаграммы Бахмана. Отличие иерархической модели данных состоит в том, что БД может иметь только древовидную структуру.
Групповые отношения в иерархической модели данных не именуются, поскольку они определяются парой типов записей: владелец (исходная запись) - подчиненный. К каждой записи БД существует только один путь (иерархический) от корневой записи. Для упорядочения подчиненных записей в групповых отношениях могут использоваться разные способы, но наиболее употребляемый - сортировка по возрастающим значениям ключевого данного.
Корневая запись обязательно должна содержать ключевые данные (ключ) о уникальным значением. Ключи некорневых записей должны иметь уникальные значения только в экземплярах групповых от ношений. Каждая запись идентифицируется полным (сцепленным ключом про которым понимается совокупность ключей всех записей от корневой по иерархическому пути. Например, для записи МБ (рис. 4) полный сцепленный ключ представляет конкатенацию ключей записей А1, В3, М5.
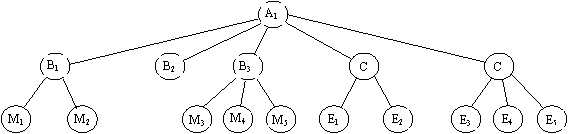
Рис. 4. Графическое изображение иерархической БД
В иерархической МОД действуют более жесткие внутренние ограничения на представление связей между объектами, чем в сетевой модели: 1) все типы связей функциональные, т.е. 1: 1, 1: М, М:1; 2) структура связей древовидная.
Иерархическая древовидная структура, ориентированная от корня, удовлетворяет следующим условиям (рис 5):
- иерархия всегда начинается о корневого узла;
- "на первом (верхнем) уровне (i = 1) может находиться только один узел - корневой;
- на нижних уровнях (i=2,3,...,n) находятся порожденные (зависимые) узлы;
- каждый исходный узел может иметь один или несколько непосредственно порожденных (подобных) узлов;
- каждый порожденный узел i-го уровня связан только с одним непосредственно исходным (родительским) узлом (i-1)-го уровня иерархии дерева;
- доступ к каждому порожденному узлу выполняется через его непосредственно исходный узел;
- существует единственный линейный иерархический путь доступа к любому узлу, начиная от корня дерева.
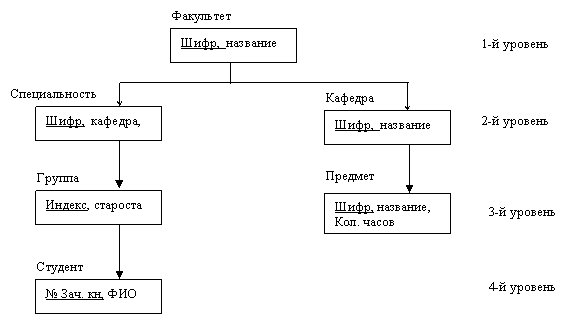
Рис.5. Пример схемы иерархической базы данных
Каждую сетевую структуру (с небольшими изменениями) можно представить средствами иерархической модели. В этом случае запись сетевой структуры будет представлена несколькими записями иерархической модели данных, а сама сеть – одной или несколькими древовидными структурами
Рассмотрим пример (рис. 6). В сетевой модели данных можно перейти от некоторой записи-владельца к подчиненной записи, а от нее к владельцу другого группового отношения.
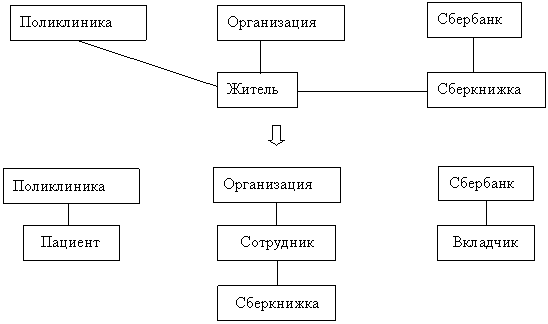
Рис. 5. Преобразование сетевой структуры в иерархическую
Так от записи ПОЛИКЛИНИКА, просматривая запись ЖИТЕЛЬ, можно для каждого жителя извлекать запись ОРГАНИЗАЦИЯ, Для обеспечения такой возможности при использовании иерархической модели данных необходимо дополнительное дублирование данных, так, в записи ПАЦИЕНТ следует хранить ключ записи ОРГАНИЗАЦИЯ. Поэтому после преобразования исходной сетевой модели в три иерархические модели сведения о жителе будут содержаться в трех записях: ПАЦИЕНТ, СОТРУДНИК, НАЛАДЧИК. Состав данных в этих записях будет различным (у пациента – медицинские данные, у сотрудника – производственные), но часть сведений будет дублироваться (например, фамилия, адрес и т.п.). Такие записи часто называются парными. Ответственность за поддержание соответствия между парными записями ложится на пользователя (модель данных этого соответствия не обеспечивает).
Сетевые структуры могут быть простыми (отсутствуют связи «многие ко многим») и сложными (допускаются связи N:M). С помощью введения избыточности можно переходить от сложной сети к простой, от простой к древовидной. При упрощении сложной сети простым повторением информации не обойтись. В этом случае создается новый узел вместо связи N:M, который составляется как сцепление первичных ключей соединяемых записей. Этот узел выполняет роль соотношения N:M.








