 2014-01-27
2014-01-27 1163
1163План лекции
1. ОРГАНИЗАЦИЯ ДАННЫХ ВО ВНЕШНЕЙ ПАМЯТИ
2. СПИСКОВЫЕ СТРУКТУРЫ
1. ОРГАНИЗАЦИЯ ДАННЫХ ВО ВНЕШНЕЙ ПАМЯТИ
Каждая БД состоит из файлов. Файлы состоят из логических записей. Данные хранятся во внешней памяти на соответствующих носителях (магнитные ленты, диски, "винчестеры" и др.). Каждый файл представляется в виде одного или нескольких блоков (страниц) данных. В одном блоке может быть одна логическая запись, несколько записей (блокированные записи), часть ее (сегмент). В последнем случае сегменты одной записи хранятся в разных блоках. Адресные ссылки между сегментами позволяют выбрать запись целиком в оперативную память.
Обмен данными между внешней я оперативной памятью выполняется блоками, т.е. блок - минимальная единица обмена между оперативной памятью и внешним носителем. При чтении с внешнего носителя блок данных размещается в буферный участок памяти. Несколько буферов образуют буферный пул. Каждый байт в блоке пронумерован (0, 1, 2,...). Номер байта блока, с которого начинается запись, определяет относительный адрес записи файла в блоке.
В качестве адресов записей файла во внешней памяти используют: машинный адрес, относительный адрес, ключ записи. В качестве относительного адреса записи файла используют ее номер по порядку (внутрисистемный номер) в файле, либо комбинацию номера блока и относительного адреса в блоке, либо номер блока и значение ключа. Во многих системах при вводе записи ей присваивается уникальный системный идентификатор - ключ базы данных. Ключ БД не следует отождествлять с ключом записи. Последний задается и используется пользователем (прикладной программой).
Данные, которые присутствуют в физической БД, но отсутствуют в логической БД, называют прозрачными. Такие данные никогда не представляются пользователю (например, адресные ссылки, ключ БД, различные счетчики в т.п.,). Данные, которые присутствуют в логической БД, но отсутствуют в физической БД называются виртуальными (например, возраст).
Каждая физическая запись, соответствующая логической, состоит обычно из двух частей - служебной и информационной. Поля служебной (прозрачной) части используются СУБД для идентификации записи, задания ее типа, хранения признака логического удаления, для кодирования значений элементов, для установления структурных связей между записями. Никакие пользовательские программы не имеют доступа к служебной части записи.
Поля информационной части содержат значения элементов данных логической записи. При этом существует два основных способа размещения значений элементов в физической записи.
1. Размещение с заранее предписанных позиций предполагает, что значение элемента в каждом экземпляре записи появляется с одной и той же позиций, определенной в описании БД.
2. Размещение с разделителями позволяет не хранить в памяти незначащие символы. Здесь элементы отделяются друг от друга разделителями (специальными кодами, часто со смысловой негрузкой, например, с указанием длины размещенного за ним значения). Если длина элементов варьируется, то память расходуется более экономно, но требуются дополнительные затраты времени м рас кодировку записи. Записи могут быть фиксированной и переменной длины.
Записи обычно размещаются в блоках плотно, без промежутков, последовательно одна за другой. В блоке часть памяти отводится также для служебной информации о блоке: относительные адреса свободных участков памяти, указатели на следующий блок и т.д.
Обычно блоки заполняются не полностью. Оставшаяся часть блока остается некоторое время незаполненной (зарезервированной). В дальнейшем эта область заполняется при увеличении (расширении) записей, хранящихся в блоке, или при поступлении в систему новых записей, которые в соответствии со значениями их ключей (или по другим условиям) надо поместить в одном блоке с уже хранящимися записями. По истечении некоторого времени блок заполняется полностью. Для хранения новых поступающих данных, которые должны были бы попасть в этот блок, выделяется дополнительный блок памяти в области переполнения. Записи, которые должны были размещаться в одном блоке, связываются специальными указателями в одну цепь. Файл периодически реорганизуется: при необходимости файлу добавляется требуемое количество блоков в основной внешней памяти и выполняется требуемая перекомпоновка записей, с целью освобождения области переполнения внешней памяти. Необходимое количество блоков определяется выражением:
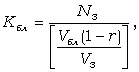
где N3 – количество записей в файле;
V3, Vбл – объем записи и блока, байт; (r < 1) – незаполненная часть блока.
Все блоки каждого файла пронумерованы (1,2,3,...,Nб) и система определяет требуемый блок по имени файла и номеру блока. Если файл состоит из записей фиксированной длины, записи организованы последовательно и имеют внутри файла системный номер, то по этому номеру i вычисляют номер блока, в котором находится запись:
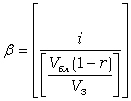
.Среднее время выполнения операции обмена t0 зависит от типа устройства внешней памяти (от его характеристик) и от размера блока:
T0 = Vбл tp + tпод,
где tp – время считывания одного байта, tпод - время подготовки устройства к обмену.
Время поиска данных в файле tп определяется следующим образом
tп = x0 t0 + xc tc,
t0 – среднее время выполнения (в процессоре) одной операции сравнения; xc - количество операций сравнения (в оперативной памяти); x0 – количество операций обмена.
Если tc << t0, то время поиска в основном определяется временем, затрачиваемым на обмен с внешней памятью.
На скорость потока данных в файле наибольшее влияние оказывает следующие характеристики файла и технических устройств внешней памяти, использованных для его организации: объем блока (в байтах); объем файла (в байтах); количество записей в блоке файла n збл; количество записей в блоке индекса; количество блоков в файле данных nблф; доля резервируемой части блока r; длина записи; размер записи (в байтах) Vз; длина ключевого поля в записи; число записей файла, удовлетворяющих условию поиска Q; среднее число блоков переполнения на один блок файла; среднее время обмена t0.
2. СПИСКОВЫЕ СТРУКТУРЫ
Форма представления структур данных в памяти ЭВМ зависит от предполагаемого использования данных, поскольку для различных типов структур эффективность выполнения тех или иных операций обработки данных различна. Элементы структуры данных в памяти ЭВМ могут адресоваться двумя способами - по месту или по содержимому. В первом случае указываются логические или физические адреса данных, определяющие место расположения данных в памяти машины. Во втором случае размещение данных и их выборка осуществляются по известному значению ключа, т.е. определяются содержимым самих данных. Этот случай реализуется в специальной ассоциативной памяти ЭВМ. Некоторый аналог ассоциативной памяти может быть реализован средствами специального программного обеспечения в обычной памяти ЭВМ.
Наиболее простой формой хранения данных в памяти ЭВМ является одномерный линейный список, обеспечивающий линейное упорядочение элементов данных (вектора данных). Это удобно и с точки зрения свойств оперативной памяти ЭВМ. Здесь байты упорядочены по возрастанию их адресов от 0 до наивысшего (проидентифицированы адресом), образуя вектор памяти.
Отображение логической структуры данных на физическую структуру хранения называют адресной функцией. При реализации адрес-Ной функции использует два основных метода: последовательное распределение памяти; связное распределение памяти.
При последовательном распределении узлы линейного списка размещаются в последовательных элементах памяти и адрес каждой записи можно вычислить с помощью адресной функции
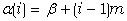 ,
,
где i - индекс элемента (i= 1,N); (- адрес базы начала вектора в памяти; m - размер элемента (записи) списка.
С помощью линейного списка при последовательном распределении памяти можно реализовать регулярное двоичное дерево (рис. 9.1).
По дереву, которое при этом получается, можно двигаться в обоих направлениях, так как от узла yк можно перейти к его потомкам, удвоив k (или удвоив k и прибавив единицу). Можно двигаться к узлу, являющемуся исходным для уk, разделив k пополам и отбросив дробную часть.
Адрес
Содержимое
?(1) =?
Y1
?(2) =?+m
Y2
?(3) =?+2m
Y3
?(4) =?+3m
Y4
?(5) =?+4m
Y5
?(6) =?+5m
Y6
?(7) =?+6m
Y7
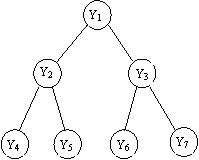
Рис. 9.1. Пример реализации регулярного двоичного дерева с помощью линейного списка
Другой способ размещения в памяти сбалансированного (регулярного) двоичного дерева заключается в следующем. Если для представления двоичного дерева используется вектор памяти от элемента i до элемента j включительно, то корень дерева размещается в элементах памяти с адресом?= [(i+j)/2], где знак [] обозначает округление до ближайшего меньшего целого.
Корень дерева размещается в середину вектора. В элементах памяти от i-го до (m-1)-го включительно размещается левое поддерево. В элементах памяти от (m+1)-го до j-го включительно размещается правое поддерево. Аналогично процесс повторяется для размещения каждого поддерева. При этом корень левого поддерева размещается в элемент (квант)?п = [i+(? - 1)]/2, а корень правого поддерева в элемент?п = [(? + 1) + j]/2. Адреса элементов вычисляются по формуле?(?) =?+ (? -1)m.
При связном распределении памяти (связные списки) задаются отношения следования и предшествования элементов с помощью указателей. Указателями служат адреса, хранимые в записях данных. В связных списках значение адресной функции можно получить только путем просмотра хранящихся указателей.
Связанное распределение - более сложный, но и более гибкий способ хранения линейного списка. Здесь не требуется, чтобы список хранился в последовательных элементах памяти, а линейная структура списка (цепи) обеспечивается указателями (рис. 9.2). Окончание списка кодируется (обозначается) специальным шифром, например, NIL или ^.
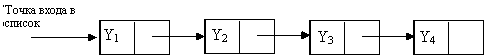
Рис. 9.2. Пример связанного линейного списка
Частными случаями линейного связного списка являются стек, очередь, дек. В стеке записи вводятся и удаляются только с одного конца. Стековую структуру еще называют структурой с магазинной памятью (последним пришел, первым ушел), а также LIFO-cписком. Стек имеет один конец и для него требуется всего один указатель.
Очередь представляет собой список, у которого добавление записей ведется на одном конце, а извлечение (удаление) - на другом. Такую структуру еще называют FIFI-списком (первая поступившая запись первой и выбирает). Очередь предполагает использование двух указателей: один не удаление, другой на добавление записи (узла).
Дек - логическая структура, в которой удаление и добавление узлов происходит на обоих концах.
Для достижения большей гибкости при работе с линейными списками в каждый узел X[i] вводятся два указателя. Один из указателей реализует связь X[i] с узлом X[i+1], а другой с узлом X[i-1] (рис. 9.3).

Рис. 9.3. Пример двунаправленного линейного списка
Удобством связанных списков является то, что при изменении порядка записей, сокращении или расширении вектора данных не требуется перемещение записей в памяти ЭВМ. Достаточно лишь изменить значения полей связи (указателей). Однако доступ к конкретному узлу может сказаться намного длительнее, чем при последовательном распределении памяти (т.к. надо просмотреть все предшествующие узлы). Компромиссом является организация связанного линейного списка с пропусками (рис. 9.4).
Для этого линейный список делится на группы узлов, связанные между собой обратными указателями. Вначале осуществляется доступ по обратным указателям к группе, в которой находится требуемый узел, а затем по прямым указателями перебираются узлы группы, пока не будет найден требуемый узел. Вход в список при таком способе организации осуществляется с конца.
Другой способ (рис. 9.4) заключается в построении специального дополнительного списка - индекса, например, с последовательным распределением памяти. Элементы индекса - значения первых узлов каждой группы и указатели на них.
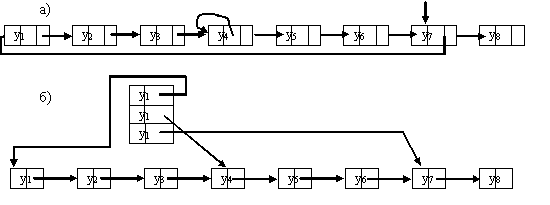
Рис. 9.4. Способы ускорения доступа к узлам линейного связанного списка:
а) организация линейного списка с пропусками; б) то же с использованием индекса
Оптимальный размер группы при равновероятном нахождении узла в любой из групп: nг = (n, где n - количество элементов списка. Число групп: l = [ n/nг ].
При равновероятном нахождении узла в любой из групп при доступе к узлу необходимо просмотреть в среднем l/2 групп, а в каждой группе nг/2 узлов. Следовательно, общее количество просмотров
А = l/2 + nг /2 = 0.5 ([n/nг] + nг).
Разновидностью представления в памяти линейного списка является циклический список(кольцевая структура, кольцо), который обладает той особенностью, что связь от последнего узла идет к первому узлу списка. Это позволяет получить доступ к любому узлу списка, отправляясь от любого заданного узла. Иногда используют двунаправленные циклические списки (рис. 9.5).
В ряде случаев удобно использовать циклический список с указателями на голову списка из каждого узла. Связанные линейные списки позволяют реализовать в памяти ЭВМ и более сложные нелинейные структуры, в частности, древовидные и сетевые. Такие представления структур называются многосвязанными списками (несколько указателей).
Рис. 9.5. Примеры двунаправленного циклического списка:
а-обычное кольцо; б- кольцо с головкой списка
Основой построения связанных списковых структур являются указатели. Практически используются три типа указателей: машинный (действительный); относительный; символьный (идентификатор). Машинный тип указателей дает жесткую привязку записей к конкретному месту памяти, но обеспечивает наибольшую скорость обработки данных. Относительный адрес (указатель) позволяет размещать записи в любом месте памяти и на различных внешних устройствах без изменения значений указателей, при этом относительное расположение в памяти узлов списка между собой должно оставаться постоянным. При перемещении списка меняется только базовый адрес памяти. Относительный адрес в качестве указателей применяются при страничной организации памяти.
Символические адреса (идентификаторы) позволяют перемещать отдельные записи относительно друг друга, включать или удалять записи в список без изменения указателей во всех остальных записях списка. Однако скорость доступа здесь наименьшая. Такие указатели удобно использовать для интенсивно меняющихся файлов.
Различают встроенные указатели и справочник указателей. Если указатели образуют часть записи, то они называются встроенными. Если указатели хранятся отдельно от записей, то они образуют справочник.
Лекция 12 ФИЗИЧЕСКАЯ ОРГАНИЗАЦИЯ БАЗ ДАННЫХ. МЕТОДЫ РАСПРЕДЕЛЕНИЯ ПАМЯТИ (продолжение)
План лекции
1. ПРЕДСТАВЛЕНИЕ ДРЕВОВИДНЫХ И СЕТЕВЫХ СТРУКТУР
1. ПРЕДСТАВЛЕНИЕ ДРЕВОВИДНЫХ И СЕТЕВЫХ СТРУКТУР
Если логическую структуру данных удается свести к последовательности элементов данных (записей), то такую логическую структуру называют линейной, в противном случае – нелинейной (деревья, сети).
Древовидные структуры часто представляются линейным списком с последовательным распределением памяти. Здесь возможны следующие два метода.
1. Метод использования адресной арифметики. Хорошо применим к сбалансированным (регулярным) деревьям. В сбалансированном дереве количество исходящих узлов из любого произвольного узла может быть больше двух (например, r), однако обязательно из каждого произвольного узла (кроме концевого) исходит одинаковое количество порожденных узлов. В этом случае узлы представляются записями фиксированной длины.
Пусть для размещения одного узла дерева требуется квант памяти размером m единиц. В имеющемся векторе памяти А в первом кванте А[1] c адресом? [1] =? помещают корень дерева. Кванты А[2] с адресом? [2] =? + m; А[3] с адресом? [3] =? + 2m;...; А[r+1] с адресом? [r+1] =? + rm заполняют непосредственными потомками корня дерева. Последующие r квантов заполняются непосредственными потомками узла, размещенного в кванте А[2]. Далее r квантов заполняются непосредственными потомками узла кванта А[3] и т.д. Адрес k-го кванта А[k] вычисляют по формуле? [k] =? +(k-1)m. В зависимости от r определяется функциональная зависимость между адресами квантов, в которых размещаются узел и его непосредственные потомки. Для r = 3 непосредственные потомки кванта А[k] – это кванты А[3k-1], А[3k], А[3k+1] с адресами? [3k-1] =? +(3k-2)m,? [3k] =? +(3k-1)m,? [3k+1] =? +3km. Чтобы получить адрес узла, являющегося исходным для узла кванта А[k], надо k разделить на 3 и округлить до целого значения по общим правилам округления. Адрес определяют по формуле? [l] =? +(l-1)m.
Для двоичных сбалансированных деревьев применяют и другой способ адресной арифметики (рис. 9.1 лек.9).
2. Метод использования левосписковых структур. Этот метод примени для любой древовидной структуры и строит последовательность узлов при обходе структуры сверху вниз и слева направо по следующему алгоритму. Выбираются узлы, начиная от корня дерева и до концевого узла включительно по крайней левой ветке дерева. Затем осуществляется подъем вверх до первой следующей ветки, и процесс повторяется. Узлы, выбранные ранее, в последовательность не включаются. Схема обхода дерева поясняется на рис. 10.1.
Рис. 10.1. Пример построения левосписковой структуры
В результате обхода дерева получим такую последовательность узлов (а, б1, в1, г1, в1, г2, в1, г3, в1, б1, в2, г4, в2, б1, а, б2, в3, г5, в3, г6, в3, б2, в4, г7, в4, б2, а, б3, в5, г8). Затем удалим ранее выбранные узлы и получим левосписковую структуру (список внизу рис.10.1). При размещении полученной последовательности в памяти можно использовать либо специальные разделители (а (б1 (в1 (г1, г2, г3) в2 (г4)) б2)(в3 (г5, г6) в4 (г7)) б3 (в5 (г8)))), либо в каждой записи резервировать поле, в котором указывается номер уровня. Доступ к узлам дерева реализуется в прямом и обратном направлениях.
Часто древовидные структуры представляются связанными линейными списками. В этом случае можно использовать следующие методы.
1. Метод указателей на порожденные записи. Он реализует движения по дереву в прямом направлении. Здесь любая запись, кроме записей самого нижнего уровня, должна иметь столько указателей, сколько имеется порожденных записей (рис. 10. 2).
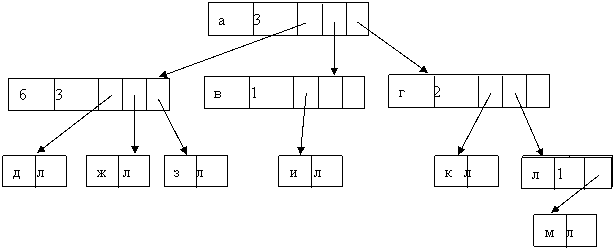
Рис.10.2. Реализация древовидной структуры
С использованием указателей на порожденные узлы
2. Метод указателей на исходные записи. В этом методе указатели используются для организации прохода по дереву в обратном направлении – от концевых узлов к корню. (Рис. 10.3)
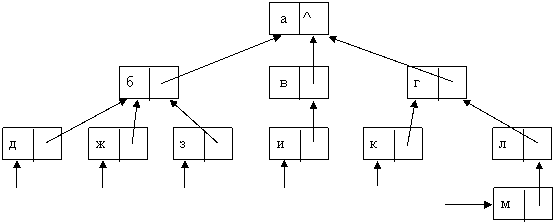
Рис.10.3. Представление древовидной структуры
С помощью указателей на исходные записи
3. Метод указателей на порожденные и исходные записи. Он обеспечивает прохождение дерева как в прямом, так и в обратном направлениях, так как используется двунаправленный список.
4. Метод указателей на порожденные и подобные записи. Он обеспечивает прохождение дерева в прямом направлении. Здесь используется по одному указателю в концевых узлах и по два в остальных (рис. 10.4).
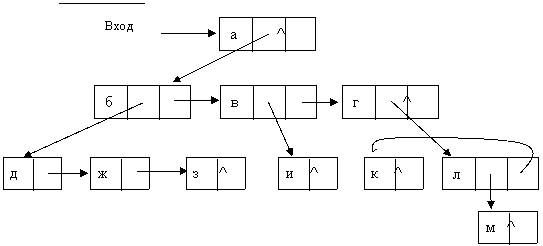
Рис. 10.4. Использование указателей на порожденные и подобные узлы
5. Метод указателей на порожденные, подобные и исходные записи. Он реализует прохождение дерева и в прямом, и в обратном направлениях.
7. Метод кольцевых структур. Если в каждом узле по два указателя (порожденных и подобных записей), то получим однонаправленные циклические списки (рис. 10.5)
8.
Часто используются двунаправленные циклические списки с четырьмя указателями в каждом узле для обхода в прямом и обратном направлениях как по кольцам порожденных записей, так и по кольцам подобных записей.
7. Метод справочников. Здесь указатели удаляются из записей и организуются в специальные файлы-справочники (рис.10.6). Справочники занимают мало места, обычно полностью размещаются в оперативной памяти, что повышает скорость поиска данных.
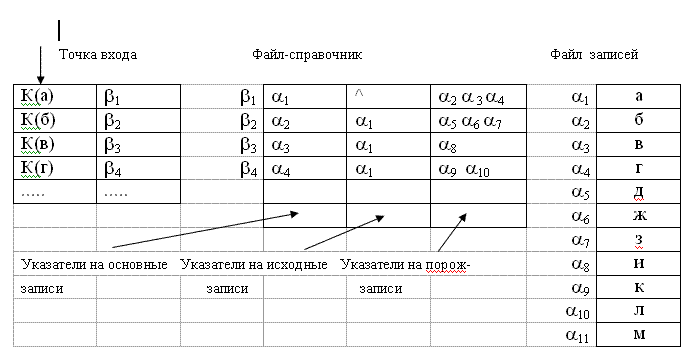
Рис.10.6. Реализация древовидной структуры методом справочника
Для представления сетевых структур часто используют рассмотренные выше методы в определенной комбинации, позволяющей реализовывать сетевую структуру. Например, используют комбинацию методов с указателями на порожденные, подобные и исходные записи. Часто используют кольцевые структуры. Однако для сложных сетевых структур необходимо вводить для каждой записи переменный список указателей. При этом одни связи между записями в сети могут добавляться, другие устраняться. Это создает серьезные проблемы при создании соответствующих обслуживающих программ.
Сложность и трудоемкость организации и использования записей со встроенными указателями переменной длины приводит к целесообразности использования метода справочника (как и для древовидных структур). Чем сложнее структура данных, тем более целесообразно применять справочник.
МЕТОДЫ ВЫЧИСЛЕНИЯ АДРЕСА ПО ЗНАЧЕНИЯМ КЛЮЧЕЙ
Для реализации адресной функции "Ключ - Адрес памяти" возможны две группы методов: 1) адресная функция реализует взаимно однозначное соответствие адресов и ключей; 2) адресная функция реализует только однозначное преобразование ключа в адрес, но обратное преобразование не всегда имеет место (методы хеширования). Методы взаимно однозначного соответствия ключей и адресов используются двух видов.
1. Методы адресации с помощью ключа, эквивалентного адресу. Например, адрес записи счета печатается в расчетной книжке клиента Сбербанка и тогда при последующих обращениях к системе поиск записи счета клиента в БД осуществляется непосредственно по ключу-адресу.
2. Метод адресации с использованием алгоритма преобразования ключа в адрес. Предполагается линейная упорядоченность записей фиксированной длины в файле. В соответствии с размером записей и характером их упорядоченности составляется уравнение адресной функции. Недостаток метода - малое заполнение отведенной для файла памяти.
Методы хеширования называют еще методами перемешивания, методами рассеянной памяти, методами рандомизации. Здесь каждый экземпляр записи размещается с помощью программы хеширования в памяти по адресу, вычисляемому с помощью некоторой адресной функции (хеш-функции) по значению первичного ключа записи. При поиске записи выполняются те же самые вычисления и запись считывается из памяти по полученному адресу.
Недостатки методов хеширования: 1) последовательность расположения в памяти записей не совпадает с последовательностью, определяемой первичным ключом; 2) возможность коллизий, когда для двух различных записей (с разными значениями ключе) вычисляется один и тот же адрес памяти.
Хеш-функция h имеет не более М различных значений и удовлетворяет условию 0< h(k)
1. Метод квадратов. Здесь значение ключа представляется целым двоичным числом и затем возводится в квадрат. Далее из ной части полученного результата выделяется l двоичных разрядов, которые интерпретируются как двоичный адрес памяти. Это можно промасштабировать по границам выделенного участка памяти умножением числа на подобранную константу. Недостаток метода квадратов: если в файле много ключей, заканчивающихся нулями, то воз ведение в квадрат вдвое увеличивает количество нулей и эти нули распространяются на среднюю часть квадрата ключа (адрес) и вызывают коллизии.
2. Метод деления. Здесь хеш-функция вычисляется по формуле h(k) = mod M., т.е. ее значение равно остатку от деления значения ключа на число М. Рекомендуется в качестве М выбирать простое число, равное или близкое к размеру участка памяти. Например, если число записей равно 4096, то можно принять делитель 4093. Тогда для значений ключа 51844, 29100, 18, 37445, 37446 будут подучены следующие адреса: 2728, 449, 18, 608, 609.
3. Метод умножения. Он основан на следующем свойстве: если значения k равномерно распределены на отрезке [a,b], то и значения С-К равномерно распределены на отрезке [c-a, c-b]. Отрезок [c.a, c.b] отображается не пространстве адресов. Существует две способа построения схемы разрешения коллизий. 1. Метод открытой адресами. Он состоит в том, что при возникновении коллизий просматривается один за другим отведенные участки памяти до тех пор, рока не будет найден свободный ток, куда и помещается записью. При поиске записи последователь гость действий аналогична. Участки памяти просматриваются до тех пор, пока не будет найдена запись с нужным ключом. В данном методе обычно задается правило, согласно которому каждый ключ К определяет последовательность адресов в памяти)?0 =h(k),?1,?2..?nk, которые надо просматривать каждый раз при вставке или поиске записи о ключом K. Если при поиске обнаружится свободная позиция, то это означает отсутствие записи в файле. Пример алгоритма формирования последовательности адресов ("линейное опробование):?0.=h(k);?1= h(k)-1;?2 = h(k)-2...?ik=0;?ik+1 = M-1;?ik+2 = M-2;...;?nk = h(k)+1.
Основной недостаток метода открытой адресации - вторичное скучивание. Первичное скучивание возникает, когда таблица содер жит много ключей о одинаковыми хеш-адресами. Вторичное окучивание возникает, когда имена о различными хеш-адресами имеют почти одинаковые последовательности адресов (в связи с работой алгоритма схемы разрешения коллизий), Чтобы избежать вторичное скучивание, принимают специальные меры. Например, алгоритм "двойное хеширование" в алгоритме "линейное опробование" формирует последовательность адресов о приращением?k (а не "1"). 2. Метод цепочек. Здесь организуются М связанных линейных списков по одному на каждый возможный хеш-адрес (рис. 4.12).
Основная область Область
памяти переполнения
Рис. 10.7. Пример метода цепочек
После хеширования ключа, если участок памяти по вычисленному адресу свободен, выполняется размещение записи по этому адресу в основ ной области памяти. Если же указанный участок занят, то происходит обращение по указателю к следующему участку памяти (элементу списка из области переполнения), и так до конца списка. После это го запись помещается на свободный участок памяти и с помощью указателей подсоединяется к концу своего списка. При поиске записей действия выполняются в той же последовательности.

