 2014-02-01
2014-02-01 717
717Первоначально он был разработан для кодирования текстовых файлов. Для изображений, которые имеют большую долю основного цвета, также бывает очень эффективным.
Основан он на использовании некоторых предварительно вычисленных статистических данных. Предварительно вычисляется статистическая информация для данных и такая же для устойчивых сочетаний у данных. Пусть у нас есть последовательность:
abbbcccddeeeeeeeee f
1 3 3 2 9 1
На основе этой последовательности строится граф. Его начинают строить с тех данных, которые встречаются в последовательности реже всего.
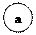 |  |
0 
 1
1
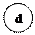 | |||
 | |||


 0 0 1
0 0 1

 1
1
 1
1
 |
0  1
1
Те данные, которые встречаются чаще всего, будут иметь короткие коды:
е.: 1
b: 010
c: 011
d: 001
a: 0000
f: 0001
Таким образом, мы заменяем данные некоторым двоичным кодом, который тем короче, чем чаще встречаются данные. Эффективность метода зависит от ряда причин:
1. Опирается на предварительную статистику.
2. Степень сжатия зависит от правильного определения статистики.
3. Следует строить граф для определения кодировки. Так как граф можно построить несколькими методами, то минимизация будет разной, то есть сам граф влияет на коды.
Эффективность от вида текста зависит крайне существенно. Существует ограниченный набор задач, где мы получаем нужный эффект. Одна из областей применения – это криптография. Оказывается, что в каждом языке, вероятность, что попадётся данная буква строго фиксируется, и если мы имеем кусок шифрованного текста, то можно вычислить вероятность каждого знака и по таблице расшифровать его.








