 2014-02-01
2014-02-01 939
939Рис. 4.2. Автокорреляция остатков
Более достоверным способом проверки существования автокорреляции является применение статистических критериев. Хорошо известны два – критерий знаков (относится к непараметрическим критериям) и критерий Дарбина-Уотсона.
Для проведения проверки по критерию знаков необходимо расположить остатки ei во временной последовательности, выписать их знаки, подсчитать число образующихся при этом серий nu из одинаковых знаков, а также n 1 – число остатков со знаком плюс и n 2 – число остатков со знаком минус. Далее определяется вероятность Pr (nu) появления nu групп при нулевой гипотезе – последовательность остатков полностью случайна (автокорреляция отсутствует). Если Pr (nu) < 1– a, где a – уровень доверия, то нулевая гипотеза отвергается.
Для ускорения расчетов для выборок с n 1, n 2 не больше 20 составлены таблицы с критическими значениями nu при уровне доверия a =0,05.
Для больших выборок истинное распределение ошибок достаточно точно аппроксимируется нормальным со средним m =2 n 1 n 2/(n 1+ n 2)+1 и дисперсией s2 =2 n 1 n 2(2 n 1 n 2 – n 1 – n 2)/(n 1 + n 2)2/(n 1 + n 2 – 1), а величина z =(u – m + 0,5)/ s подчиняется нормированному нормальному распределению, следовательно, критические значения nu могут быть вычислены по формулам (m + zas) и (m – zas), где za определяется из условия F 0(za)=(1– a)/2 (значения 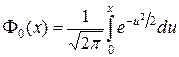 даны в справочниках).
даны в справочниках).
Пример. Получены остатки 0,6; 1,9; –1,8; –2,7; –2,9; 1,4; 3,3; 0,3; 0,8; 2,3; –1,4; –1,1, которые обнаруживают следующую последовательность знаков + + – – – + + + + + – –. Имеем nu =4, n 1=7, n 2=5. По таблице находим критические значения для nu: 3 и 11. Так как 3 < nu < 11, то нулевая гипотеза принимается, то есть остатки независимы и автокорреляция отсутствует.Ñ
Критерий знаков достаточно прост и не использует информацию о величине ei, и поэтому недостаточно эффективен.
Для проверки гипотезы о существовании линейной автокорреляции первого порядка, которая чаще всего имеет место на практике, предпочтителен критерий Дарбина-Уотсона, основанный на статистике:
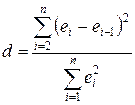 (4.9)
(4.9)
Значения первых разностей ошибки в (4.9) будут обнаруживать тенденцию к уменьшению по абсолютной величине по сравнению с абсолютными значениями ei при положительной автокорреляции и к увеличению при отрицательной автокорреляции.
Для статистики d имеются верхний d U и нижний d L пределы уровня значимости. Различные статистические решения для нулевой гипотезы H0: автокорреляция равна нулю, даны в табл. 4.3. При этом появляются области неопределенности, так как величина ei зависит не только от значений u, но и от значений последовательных X.
Следует отметить, что критерий Дарбина-Уотсона предназначен для моделей с детерминированными (нестохастическими) регрессорами X и не применим, например, в случаях, когда среди объясняющих переменных есть лаговые значения переменной Y.
Таблица 4.3
Области статистических решений для критерия Дарбина-Уотсона
| d < d L | d L< d < d U | d U< d <2; 2< d <(4– d U) | (4– d U)< d <(4– d L) | d >(4– d L) |
| Отвергаем H0 в пользу гипотезы о положительной автокорреляции | H0 не принимается и не отвергается | Принимается H0 | H0 не принимается и не отвергается | Отвергаем H0 в пользу гипотезы об отрицательной автокорреляции |
Пример. Для примера 1 из п. 3.2 n =20, k =2 имеем табл. 4.4.
Далее по формуле (4.9) d =4397,66/2050,37=2,14.
Значения d L и d U при уровне значимости 5% получим из справочника при n =20 и k =2: d L=1,10, d U=1,54.
Так как d >2, то вычисляем 4– d U=2,46 и 4– d L=2,90 и 2< d <4– d U.
Согласно табл. 4.3 гипотеза о равенстве нулю автокорреляции принимается. Ñ
Какой бы тест на автокорреляцию не использовался, необходимо помнить, что рекомендуется в случаях неопределенности (см. табл. 4.3) принимать гипотезу о наличии автокорреляции, поскольку это гарантирует от отрицательных последствий автокорреляции. В случаях же некорректного принятия гипотезы о равенстве нулю автокорреляции получаем модель, которая не может иметь удовлетворительного применения, хотя формально проходит все проверки.
Таблица 4.4
Вычисление значения статистики d
| Ошибка ei | ei 2 | ei-1 | (ei-ei-1)2 | Ошибка ei | ei 2 | ei -1 | (ei - ei -1) 2 |
| -2,49 | 6,20 | -0,68 | 0,46 | -8,72 | 64,64 | ||
| -1,86 | 3,46 | -2,49 | 0,40 | 5,27 | 27,72 | -0,68 | 35,40 |
| 31,93 | 1019,21 | -1,86 | 1141,76 | -5,29 | 27,93 | 5,27 | 111,51 |
| -3,18 | 10,11 | 31,93 | 1232,71 | -16,74 | 280,23 | -5,29 | 131,10 |
| -2,17 | 4,71 | -3,18 | 1,02 | 8,94 | 79,87 | -16,74 | 659,46 |
| -18,38 | 337,64 | -2,17 | 262,76 | -3,57 | 12,74 | 8,94 | 156,50 |
| -3,45 | 11,90 | -18,38 | 222,90 | 5,18 | 26,79 | -3,57 | 76,56 |
| 5,58 | 31,14 | -3,45 | 81,54 | 7,72 | 59,60 | 5,18 | 6,45 |
| -3,11 | 9,67 | 5,58 | 75,52 | -0,85 | 0,72 | 7,72 | 73,44 |
| -8,72 | 76,04 | -3,11 | 31,47 | 4,85 | 23,47 | -0,85 | 32,49 |
| Сумма | 2050,37 | 4397,66 |
Рассмотрим методы оценивания уравнения регрессии при наличии автокорреляции остатков.
Пусть имеем обобщенную линейную модель множественной регрессии в виде (4.3)-(4.7) с гомоскедастичными остатками 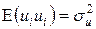 .
.
Предположим, что остатки ui удовлетворяют следующему уравнению:
ui = rui -1+ ei, i =2,..., n, (4.10)
представляющему собой авторегрессионную модель первого порядка, для которой выполнено | r |£1, а ei удовлетворяют условиям:
E (ei)=0; 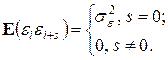 (4.11)
(4.11)
Тогда несложно показать, что будет выполняться:
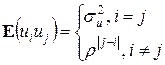 . (4.12)
. (4.12)
Условие (4.12) является аналогом (4.5) и фактически означает гомоскедастичность дисперсии случайного члена (первая строчка) и автокорреляцию первого порядка (вторая строчка). Ясно, что если бы было известно значение r в (4.10) и затем в (4.12), то можно было бы применить ОМНК (элементы матрицы W в этом случае вычисляются согласно (4.12)) и получить эффективные оценки коэффициентов регрессии. Однако на практике значение r в большинстве случаев не известно, поэтому используются следующие методы оценивания регрессионной модели.
Метод 1. Отказавшись от определения величины r, являющейся узким местом модели, статистически, можно положить r =0,5; 1 или -1. Однако даже грубая статистическая оценка будет, видимо, более эффективной, поэтому другой способ определения r с помощью статистики Дарбина-Уотсона r»1–0,5 d. Применяя затем непосредственно ОМНК, получим оценки коэффициентов.
Метод 2. Если значение r в (4.12) задано, то альтернативная схема отыскания оценок коэффициентов модели множественной регрессии суть (в целях упрощения, не нарушая общности, иллюстрация метода дана для случая парной регрессии):
а) Запишем уравнение модели для случая i и i –1:
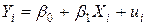
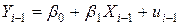 .
.
Вычтем из обеих частей первого уравнения умноженное на r второе уравнение:
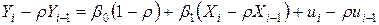
или переобозначив:
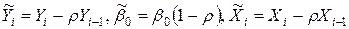
с учетом (4.10) 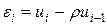 , получим модель
, получим модель
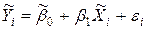 , (4.13)
, (4.13)
для случайного члена которой выполняется условие (4.11), т.е. автокорреляция отсутствует. При указанном преобразовании первое наблюдение умножается на 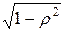 , т.е.
, т.е. 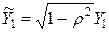 ,
, 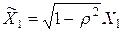 .
.
б) Применяем обыкновенный МНК к модели (4.13).
В общем случае мы не располагаем информацией о порядке автокорреляции и значениях параметров в авторегрессионном уравнении, а значит, и методы 1 и 2 не дадут искомого результата.
Тем не менее, оценки коэффициентов можно найти приближенно с помощью следующих методов (опять в целях упрощения, не нарушая общности, иллюстрация методов дана для случая парной регрессии).
Метод 3. Итеративная процедура Кохрейна-Оркатта.
а) Оценивается регрессия с исходными не преобразованными данными с помощью обыкновенного МНК.
б) Вычисляются остатки ei.
в) Оценивается регрессия ei = rei -1+ ei, и коэффициент при ei -1 дает оценку r.
г) С учетом полученной оценки r уравнение преобразовывается к виду (4.13), оценивание которого позволяет получить пересмотренные оценки коэффициентов b 0 и b 1.
д) Вычисляются остатки регрессии (4.13) и процесс выполняется снова, начиная с этапа в).
Итерации заканчиваются, когда абсолютные разности последовательных значений оценок коэффициентов b 0, b 1 и r будут меньше заданного числа (точности).
Подобная процедура оценивания порождает проблемы, касающиеся сходимости итерационного процесса и характера найденного минимума: локальный или глобальный.
Метод 4. Метод Хилдрета-Лу основан на тех же принципах, что и рассмотренный метод 3, но использует другой алгоритм вычислений. Здесь регрессия (4.13) оценивается МНК для каждого значения r из диапазона [-1, 1] с некоторым шагом внутри него. Значение, которое дает минимальную стандартную ошибку для преобразованного уравнения (4.13), принимается в качестве оценки r, а коэффициенты регрессии определяются при оценивании уравнения (4.13) с использованием этого значения.
Метод 5. Дарбиным была предложена простая схема, дающая эффективные оценки коэффициентов:
а). Подставляя (4.10) в модель Yi = b 0+ b 1 Xi + ui, получим с учетом ui- 1 = Yi -1 - b 0 - b 1 Xi -1:
Yi = b 0(1- r)+ rYi-1 + b 1(Xi - rXi -1) + ei,
где ошибка ei удовлетворяет (4.11). Применяя обыкновенный МНК к последней модели, получаем оценку r как коэффициента при Yi -1.
б). Вычисляем значения преобразованных переменных и применяем к ним обыкновенный МНК. Получаем искомые оценки коэффициентов регрессии.
Достоинством метода является простота его распространения на случай автокорреляции более высокого порядка.
Как показывают эксперименты, проведенные для малых выборок, лучшим является двухшаговый метод 2, использующий оценку r, полученную по методу, предложенному Дарбиным (метод 5 шаг а)).
Факторы (объясняющие переменные), применяемые в задаче регрессии до сих пор, принимали значения из некоторого непрерывного интервала. Иногда может понадобиться ввести в модель переменные, значения которых детерминированы и дискретны. Например, данные получены для трех разных районов, или на двух фабриках, или на разных машинах и т.п. Переменные такого типа обычно называют фиктивными или искусственными. Эти переменные позволяют отразить в модели эффекты сдвига во времени или в пространстве, воздействия качественных переменных. Пример фиктивной переменной - это переменная X 0 при свободном члене b 0 в уравнении регрессии (3.1), которая принята равной 1. Эту переменную необязательно вводить в модель, но ее использование обеспечивает некоторое удобство в обозначениях. Во многих других случаях введение фиктивных переменных диктуется необходимостью.
Пример. Допустим, мы хотим отразить в модели разное происхождение куриных окорочков (исходные данные7 - таблица 4.5), часть из которых получены в Америке, а часть в Канаде, при построении регрессионной зависимости веса окорочков Y от возраста кур X. Для этого в модель включим фиктивную переменную Z: Z =0 для Америки, Z =1 для Канады:
Y = b 0 + b 1 X + aZ.








