 2018-03-09
2018-03-09 3203
3203Зная величину ошибки, можно рассчитать необходимый объем наблюдений для проведения выборочного исследования и получения достоверных результатов. Поскольку искомые закономерности можно выявить, исследовав только генеральную совокупность, не следует забывать, что проведение выборочных исследований требует существенно меньше средств. Однако получение достоверных результатов возможно лишь в том случае, если выборочная совокупность является репрезентативной, т. е. представительной по отношению к генеральной совокупности по количеству и по качеству. Научной основой выборочного метода является закон больших чисел и теория вероятности, которые позволяют сформулировать следующие основные положения закона больших чисел:
· при увеличении числа наблюдений данные выборочной совокупности стремятся воспроизвести данные генеральной совокупности;
· при достижении определенного, достаточного количества данные выборочной совокупности воспроизводят данные генеральной совокупности.
Статистические методы позволяют обрабатывать любое число наблюдений (как было показано ранее), но чтобы застраховать себя от получения недостоверного результата, следует заранее определить необходимый объем наблюдений для получения достоверных результатов. С этой целью используют специальные формулы, полученные при помощи преобразования формул предельных ошибок для средних и относительных величин:
tmабс. = t 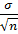 , tm%= t
, tm%= t  ,
,
где n— число наблюдении,
t— доверительный коэффициент,
а — среднее квадратическое отклонение,
р — результирующий признак, выраженный в процентах,
q— величина, равная 100 — р,
tm= ∆ — предельно допустимая максимальная ошибка с достаточной степенью вероятности.
Решая приведенные равенства путем алгебраических преобразований относительно "п", получают формулы для определения числа наблюдений, когда выбранный признак берется:
· в абсолютных цифрах n =  ,
,
· в относительных величинах n = 
Приведенные формулы для случайного повторного отбора определяют оптимальный объем выборки для исследования существующих закономерностей и получения достоверных результатов. Необходимо лишь выбрать признак или признаки для проведения соответствующих вычислений, что в ряде случаев затруднено, поскольку единицы наблюдения в исследуемых совокупностях характеризуются множеством учетных признаков. Так, в комплексных социально-гигиенических исследованиях изучают не только комплекс показателей, свидетельствующих о состоянии здоровья изучаемой группы населения, но и окружающие условия, факторы, воздействующие на здоровье. Вести расчет по всем исследуемым признакам невозможно, поэтому, как правило, выделяют 2—3 результирующих признака и конкретно по ним рассчитывают необходимый объем наблюдений.
Сведения о критериях, характеризующих разнообразие признаков (σ и Р) и нужных для расчета необходимого числа наблюдений, получают:
· из данных литературы;
· если признак выражен абсолютным числом и в литературе данных о нем нет, то используют результаты пробного исследования, объем которого обычно составляет не менее 30 единиц наблюдения;
· если признак выражен относительным числом, то берут значение максимального произведения pq= 2500 (р = q= 50 %) или pq= 0,25 (р = q= 0,5), так как не следует пробное исследование проводить и вычислять проценты при числе наблюдений менее 100.
Степень доверительной вероятности при вычислении необходимого объема наблюдений зависит от целей и задач исследования, но обычно составляет не менее 95,5 % (или 0,95), при которой t= 2. Величина максимальной ошибки (∆) выражается в единицах изучаемого признака, характеризует допускаемую неточность искомой величины в сравнении с генеральной совокупностью, задается в разумных пределах в зависимости от целей и задач исследования. Незначительное увеличение ∆ ведет к резкому сокращению необходимого объема выборки, напротив, незначительное уменьшение ∆ резко его увеличивает.
Например, для изучения состояния здоровья детей первых 3 лет жизни в связи с особенностями состояния здоровья родителей необходимо рассчитать среднее квадратическое отклонение, равное 1,6; число наблюдений для получения достоверного результата. В качестве результирующего признака была взята кратность перенесенных детьми заболеваний на 2-м году жизни. Индивидуальная характеристика заболеваемости детей ранее не изучалась. При проведении пробного исследования, включающего обследование 28 детей 2-го года жизни, были получены следующие данные:
М - среднее число перенесенных ребенком заболеваний в год составило 3,8;
σ — предельно допустимая ошибка, равная 0,2;
р - доверительная вероятность, равная 95,5 %;
t - доверительный коэффициент, равный 2.
Расчет производят по формуле:n =  = 256 единиц наблюдения
= 256 единиц наблюдения
Вывод: для получения статистически достоверных данных о состоянии здоровья детей первых 3 лет жизни в связи с особенностями здоровья их родителей необходимо обследовать 256 детей.
В качестве другого результирующего признака был взят показатель "индекс здоровья", отражающий удельный вес детей, не болевших на 1-м году жизни. При анализе данных литературы было установлено, что среди детей количество не болевших на 1-м году жизни в Москве составило 9,5 %. При доверительной вероятности 95,5 % и предельно допустимой ошибке 3,5 % необходимое число наблюдений было определено по формуле и составило 280,7:
n =  = 280,7 единиц наблюдения
= 280,7 единиц наблюдения
где р - результирующий признак, выраженный в процентах и равный 9,5 %;
q- величина, равная 100 — р и составившая 90,5 %;
∆ - предельно допустимая ошибка, равная 3,5 %;
Р - доверительная вероятность, равная 95,5 %;
t- доверительный коэффициент, равный 2.
Вывод: для получения статистически достоверных данных о состоянии здоровья детей необходимо обследовать 281 ребенка в возрасте от 0 до 3 лет.
Учитывая результаты определения необходимого объема наблюдений для получения статистически достоверных данных о состоянии здоровья детей первых 3 лет жизни на основании произведенных расчетов по двум результирующим признакам (в первом случае 256 единиц наблюдения, а во втором - 281), необходимо обследовать не менее 282 детей данного возраста.
Иногда при определении основного (результирующего) признака и его предельно допустимой ошибки, особенно при изучении совсем незнакомых совокупностей, возникают трудности, которых можно избежать, если воспользоваться данными табл.12, где значения ∆ и σ не определяют заранее, а беруториентировочное соотношение ∆ и σ (∆/σ). Последнее обозначают как коэффициент точности (К), уровень соотношения выбирают в зависимости от цели и задач исследования в пределах от 0,5 до 0,1.
Как следует из табл.12, необходимый объем выборки для получения устойчивых результатов с достаточной степенью уверенности и точности составляет 400 единиц наблюдения при точности исследования (К) 0,1 и доверительной вероятности (Р) 95,4 %, что несколько выше, чем при проведении расчетов.
Таблица 12
Необходимый объем выборки в зависимости от точности исследования и доверительной вероятности
| Вид исследования | Желаемая точность исследования K = ∆/σ | |||
| t = 2 P = 95,5% | t = 2,5 P = 98,6% | t = 3,0 P = 99,7 % | ||
| Ориентировочное знакомство | 0,5 0,4 0,3 | 16 25 44 | 25 39 69 | 36 56 100 |
| Исследование средней точности | 0,2 | 100 | 156 | 225 |
| Исследование повышенной точности | 0,1 | 400 | 625 | 900 |
1.4.5. Пятое свойство статистической совокупности — взаимосвязь признаков в статистической совокупности
Пятое свойство статистической совокупности — это определение взаимосвязи между признаками. В природе и обществе все процессы и явления взаимно связаны. Формами проявления количественных связей служат функциональная и корреляционная связи.
Функциональная связь характеризуется тем, что каждому значению одного признака соответствует строго определенное значение другого признака и изменение величины одного признака неизбежно вызывает совершенно определенные изменения величины другого признака. Как правило, функциональная связь характерна для физико-химических явлений и присуща неживой природе: например, с возрастанием скорости увеличивается пройденное расстояние.
При корреляционной связи каждому значению одного признака соответствует несколько значений другого признака, поэтому она проявляется лишь при массовом сопоставлении признаков в качественно однородной совокупности и характерна для социально-гигиенических и медико-биологических процессов. Например, при увеличении роста, как правило, возрастает масса тела человека, хотя могут встречаться высокие люди, но с дефицитом массы тела, и наоборот, при небольшом росте наблюдается избыточная масса тела.
Признаки могут быть качественными и количественными несгруппированными величинами (абсолютными и производными). Главным является установление причинных взаимосвязей, подтверждающих зависимость одного явления от другого или от какой-то общей причины. С этой целью определяют коэффициент корреляции, который позволяет оценить характер, силу и достоверность взаимосвязи изучаемых признаков. По направлению связь между явлениями может быть прямой (+) и обратной (-). Если связь между признаками прямая, то с увеличением одного признака увеличивается и другой. Например, чем старше ребенок, тем больше его рост; по мере снижения температуры тела, как правило, частота пульса уменьшается и т. д. При обратной связи между изучаемыми явлениями с увеличением одного признака другой увеличиваться не будет. Например, с увеличением возраста снижается показатель средней продолжительности предстоящей жизни. В зависимости от численного выражения коэффициента корреляции различают связь слабую (от 0,0 до 0,3), среднюю (от 0,3 до 0,7) и сильную (от 0,7 до 1,0). Фактически, если коэффициент корреляции составит 0,0, то это значит, что связь между явлениями отсутствует, а если коэффициент корреляции будет равен 1,0, то это свидетельствует о сильной и полной (или функциональной) связи между явлениями. Достоверность коэффициента корреляции определяется величиной ошибки и доверительным коэффициентом t. В том случае, если полученный коэффициент корреляции в 3 раза и более превышает свою ошибку, он считается достоверным.
Для вычисления коэффициента корреляции используют методы рангов, или метод Спирмена (р), квадратов, или метод Пирсона (r), корреляционной решетки (η) и множественной корреляции. Наиболее простым методом является вычисление коэффициента корреляции методом рангов (метод Спирмена), но полученный коэффициент дает приближенные результаты. Для вычисления коэффициента корреляции данным методом используют формулу:
Ρxy = 1 - 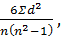
где d— разность рангов;
1 и 6 — постоянные коэффициенты;
п — число наблюдений сравниваемых пар.
Применение данной формулы предполагает обязательное ранжирование признаков в порядке их возрастания (или убывания)
Таблица 13
Определение связи между ростом и массой тела у студентов-мужчин 20-22 лет по методу рангов
| Число обследованных | Признаки | Ранги | Разность рангов | |||
| Рост (x), см. | Масса тела (y), кг. | x | y | -y | d2 | |
| 1 2 3 4 5 6 7 8 9 10 11 12 n = 12 | 169 170 171 174 176 180 181 184 185 185 187 188 | 55 61 62 68 75 75 81 78 71 80 81 82 | 1 2 3 4 5 6 7 8 9,5 9,5 11 12 | 1 2 3 4 6,5 6,5 10,5 8 5 9 10,5 12 | 0 0 0 0 -1,5 -0,5 -3,5 0 4,5 0,5 0,5 0 | 0 0 0 0 2,25 0,25 12,25 0 20,25 0,25 0,25 0 𝞢 = 35,5 |
Главным условием является соблюдение определенных правил:
• ранжировать каждую колонку цифр (вариант) нужно независимо от данных других столбцов;
• при ранжировании соблюдать единые требования, состоящие в том, что если в первой колонке вариант ранжирование начали с минимальной величины, то и во второй колонке цифр необходимо сделать также. Например, для определения взаимосвязи роста и массы тела были обследованы 12 студентов-мужчин в возрасте 20—22 года. Полученные данные представлены в табл. 13.
При определении порядкового номера следует учитывать, что при наличии одинаковых вариант им всем дается среднее значение тех рангов, которые они (варианты) занимают. Так, в данном примере две варианты роста имели одинаковое значение 185 см и занимали по порядку 9-е и 10-е места, при этом каждая варианта получила среднее значение приходящихся наних порядковых (ранговых) мест, равное 2J_!5 = 9,5. Аналогичным образом рассчитывали ранговые места для массы тела.
Подставляя полученные значения (d и п) в формулу, вычисляем коэффициент корреляции, он равен +0,876, что свидетельствует о наличии прямой и сильной зависимости между ростом и массой тела у студентов-мужчин в возрасте 20 - 22 года
Ρxy= 1 -  = 1-
= 1-  = 1- 0,124 = +0,876
= 1- 0,124 = +0,876
Для определения достоверности полученного коэффициента корреляции вычисляют величину ошибки по формуле:
mp = 
где mp — средняя ошибка коэффициента корреляции, вычисленного методом рангов;
р — величина коэффициента корреляции, вычисленного методом рангов;
п — число наблюдений.
Величина ошибки коэффициента корреляции (р = +0,876).
Таким образом, вычисленный по методу рангов коэффициент корреляции, равный +0,876 ± 0,153, отражает наличие прямой, сильной и достоверной корреляционной зависимости и свидетельствует о том, что в целом с увеличением роста возрастает масса тела.
Метод рангов применяют в тех случаях, когда:
• число наблюдений не больше 30;
• признаки имеют не только количественное, но и качественное выражение (описательного характера);
• ряды распределения имеют открытые варианты (20 лет и более).
Наиболее точным и часто применяемым является метод квадратов или метод Пирсона:
rxy =  ,
,
где ρ – коэффициент корреляции, вычисленный методом квадратов
dx – отклонения вариант от средней величины (Vx – Mx)
dy - отклонения вариант от средней величины(Vy- My)
Ошибку для коэффициента корреляции, вычисленного методом квадратов, определяют по формуле:
mr = 
где mr - ошибка коэффициента корреляции, вычисленного методом
квадратов;
п - число наблюдений.
При большом числе наблюдений (более 30 единиц) для определения коэффициента корреляции целесообразно применять метод корреляционной решетки, а при определении связи одновременно между тремя и более признаками используют метод множественной корреляции. При этом коэффициент корреляции (характер, сила и достоверность) оценивают по критериям, описанным ранее.
Метод стандартизации. При сравнении тех или иных общих показателей необходимо соблюдать важнейшее условие, которое заключается в однородности состава сравниваемых совокупностей по признаку, влияющему на величину этих показателей. Так, например, для того чтобы сопоставить летальность в двух больницах и сделать вывод, где она выше, следует прежде всего проанализировать, однороден ли в этих больницах состав больных по нозологическим формам болезни, по возрастному составу больных, по уровню оснащенности оборудованием и медикаментами и т. д.
Безусловно, в больнице, в которой среди госпитализированных больше лиц с тяжелыми хроническими заболеваниями, находящихся в более старших возрастных группах, будет выше общий показатель летальности. Разный состав пациентов в этих больницах делает несопоставимыми общие показатели летальности. Однако в ряде случаев не только в социально-гигиенических клинических исследованиях, а и в практическом здравоохранении нередко невозможно составить однородные группы для сравнения тех или иных показателей. Это касается, прежде всего, заболеваемости, рождаемости, общей смертности, а также показателей, характеризующих деятельность лечебно-профилактических учреждений в странах, областях, городах, районах внутри города, имеющих разный состав населения по возрасту, полу, исходному состоянию здоровья, условиям жизни и т. д. Например, при сравнении деятельности учреждений здравоохранения одним из ведущих показателей является число больных, выписанных из стационара с осложнениями. Так, в одной из больниц города этот показатель составил 3,4, а в другой — 3,7 на 100 больных. Но прежде чем сравнивать эти показатели и делать выводы, следует проанализировать совокупности, из которых они получены. В данном случае необходимо обратить внимание на распределение больных по отделениям. Преобладание терапевтических больных, как правило, способствует увеличению показателя, так как именно в это отделение госпитализируют тяжелобольных, нередко имеющих сочетанную патологию.
Для сравнения данных показателей, вычисленных из неоднородных по своему составу совокупностей, применяют специальный метод, который называется методом стандартизации.
Стандартизация — метод сравнения показателей в двух неоднородных совокупностях на основании расчета условных (стандартизованных) показателей при использовании стандарта.
Рассчитанные при помощи этого метода стандартизованные показатели условны, потому что они, косвенно устраняя влияние того или иного фактора на истинные показатели, указывают, какими были бы эти показатели, если бы влияние данного фактора, мешающего сравнению, отсутствовало.
Следовательно, стандартизованные показатели могут быть использованы только с целью сравнения. Существует несколько способов расчета стандартизованных показателей, среди которых различают прямой, косвенный и обратный методы. Наиболее распространенным является прямой метод.
Суть прямого метода состоит в вычислении общих стандартизованных показателей в сравниваемых совокупностях, которые уравновешены благодаря выбранному стандарту. Предварительно на I этапе вычисляют интенсивные показатели в каждой из сравниваемых совокупностей, по которым судят об истинной частоте изучаемого явления в исследуемых совокупностях. Следующий II этап заключается в выборе стандарта, за который можно принять сумму данных двух рассматриваемых совокупностей, или средний состав обеих групп, или одну из сравниваемых групп, или какую-то третью группу, близкую к сравниваемым данным одной из статистических совокупностей. Главное условие — стандарт должен быть одинаковым для сравниваемых совокупностей.
На III этапе рассчитывают условные величины в каждой группе стандарта и на IV этапе — общие стандартизованные показатели, которые тоже являются условными, гипотетическими. Целесообразно все последовательные расчетные операции по этапам стандартизации оформить в виде таблицы (табл.14).
Таблица 14
Распределение больных, выписанных с осложнениями в больницах
А и Б (данные условные)
| Отделение | Больница А | Больница Б | I этап интенсив ные показа тели (на 100 больных) | II этап Выбор стандарта | III этап ожидаемое число больных на стандарт | ||||
| Число больных | Из них с осложнениями | Число больных | Из них с осложнениями | А | Б | 1+2 графы | А | Б | |
| Терапевтическое Хирурги ческое Гинеколо гическое В целом по больнице | 500 400 100 1000 | 25 8 4 37 | 200 600 200 1000 | 12 12 10 34 | 5,0 2,0 4,0 3,7 | 6,0 2,0 5,0 3,4 IV этап | 700 1000 300 2000 100 | 35,0 20,0 12,0 67,0 3,35 | 42,0 20,0 15,0 77,0 3,85 |
Таким образом, применение прямого метода стандартизации включает последовательное выполнение 5 этапов. На I этапе рассчитывают интенсивные и общие показатели (или средние величины) по всем группам в двух сравниваемых совокупностях. В нашем примере это вычисление частоты осложнений у больных в каждом отделении и в целом в двух больницах. На II этапе определяют стандарт, который в приведенном примере был равен сумме числа больных в каждом отделении. На III этапе рассчитывают ожидаемые величины осложнений в каждом отделении в больницах. На IV этапе определяют стандартизованные показатели в больницахА и Б. Выполнение V этапа, на котором сравнивают интенсивные и стандартизованные показатели в двух больницах, позволяет сделать вывод о величине показателя и степени влияния разного состава сравниваемых совокупностей по стандартизуемому признаку.
Так, в нашем примере (см. табл.14) полученные интенсивные показатели свидетельствуют о том, что частота осложнений выше в больнице А по сравнению с таковой в больнице Б (соответственно 3,7 и 3,4 случая осложнений на 1000 больных). Однако более высокий уровень осложнений в больнице А обусловлен преобладанием в ней терапевтических больных (число терапевтических коек в больнице А 500, а в больнице Б 400).
Такой вывод можно сделать на основании использования метода стандартизации. После проведения стандартизации (т. е. устранения различий в распределении больных в имеющихся отделениях) вычисленные стандартизованные показатели распространенности осложнений оказались ниже в больнице А по сравнению с показателями в больнице Б при одинаковой численности больных в отделениях (соответственно 3,35 и 3,85 ожидаемого случая осложнений на 100 больных). Таким образом, неравномерное распределение больных в отделениях влияет на показатель частоты осложнений в больнице в целом. Возможно, следует провести стандартизацию в отношении и других факторов, воздействующих на частоту осложнений.
Графические изображения. Статистическая обработка полученных данных завершается графическими изображениями, позволяющими дать наглядное представление результатов исследования. Практически в каждом статистическом исследовании применяют графический метод, для правильного использования которого нужно знать основные виды графических изображений и правила их построения.
Графиками в статистике называют условные изображения числовых величин (средних и относительных) в виде различных геометрических образцов (линий, плоских и объемных фигур в виде многоугольников, круга и т. д.). Статистический график дает возможность наглядно оценить характер изучаемого явления, присущие ему закономерности, особенности, тенденции развития, взаимосвязь характеризующих его показателей.
Каждый график состоит из графического образа и вспомогательных элементов. Графический образ — это совокупность точек, линий и фигур, с помощью которых изображают статистические данные. Вспомогательные элементы — это общее назначение графика, пояснение условных знаков и смысла графического образа, оси координат, шкалы, числовые сетки и числовые данные, дополняющие или уточняющие изображаемые показатели. Вспомогательные элементы облегчают чтение и толкование графика. Название графика должно быть кратким и точно раскрывать его содержание, располагается обычно под графиком в отличие от таблицы, название которой находится над ней. Пояснительные тексты могут располагаться в пределах графического образа, рядом с ним или выноситься за его пределы. Оси координат с нанесенными на них шкалами и числовые сетки необходимы для построения графика и пользования им. Шкалы могут быть прямо- или криволинейными (круговыми); равномерными (линейными) и неравномерными (например, логарифмическая шкала).
Статистические графики делят по разным признакам: способу построения, характеру графического образа и назначению (содержанию).
По способу построения графики делят на диаграммы, картограммы и картодиаграммы. По характеру графического образа различают графики точечные, линейные, плоскостные (столбиковые, полосовые или ленточные, квадратные, круговые, секторные, фигурные) и объемные. По назначению (содержанию) выделяют графики, изображающие различные относительные величины (структура явления, динамика процесса и др.) или показывающие сравнения в пространстве, размещения по территории, колеблемость вариационных рядов и взаимосвязанных показателей.
Диаграммой называют изображение статистических данных в виде точек, линий, плоскостей, фигур; они могут быть представлены в виде линейных, плоскостных, объемных и фигурных изображений.
Картограмма — графическое изображение статистических величин, представленных на географической карте.
В том случае, если статистические данные изображены в виде диаграммы на географической карте, то такой вид графического изображения называют картодиаграммой.
Вид графического изображения выбирают в зависимости от того, какие статистические величины требуется представить наглядно. Так, абсолютные величины (например, численность населения страны, города и т. д.) и интенсивные показатели (например, показатели рождаемости, смертности и т. д.) можно изобразить в виде диаграмм, картограмм и картодиаграмм. Причем в случае изображения динамики процесса пользуются линейными диаграммами, а если необходимо дать характеристику процесса за единый отрезок времени на различных территориях, то следует применять столбиковые диаграммы. Это же относится к использованию объемных или фигурных диаграмм. Для графического изображения экстенсивных показателей необходимо пользоваться внутристолбиковыми и секторными диаграммами.
Таким образом, обязательным правилом является применение графического метода в строгом соответствии графического изображения имеющимся статистическим величинам и правилам построения диаграмм.
Линейную диаграмму обычно используют для изображения динамики процесса, явления во времени.
Столбиковую диаграмму применяют для иллюстрации однородных, но не связанных между собой интенсивных показателей
Секторную диаграмму применяют для изображения экстенсивных показателей.
Наряду с секторной диаграммой для изображения экстенсивных показателей применяют внутристолбиковую диаграмму, в которой ширина и высота столбика — произвольные.
IVэтап. Статистический анализ изучаемого явления, формулировка выводов - ответственный этап исследования, на котором проводится вычисление статистических показателей (частоты, структуры, с редних размеров изучаемого явления), дается их графическое изображение, Изучается динамика, тенденции, устанавливаются связи между явлениями. Даются прогнозы и т. д. Анализ предполагает интерпретацию полученных данных, оценку достоверности результатов исследования. В заключение делаются выводы.
В проведении статистического исследования важнейшим элементом является соблюдение строгой последовательности в осуществлении названных этапов.
Результаты исследования могут быть оформлены в виде статьи, отчета, доклада, д иссертации и др. Для каждого вида оформления существуют определенные требования, к оторые должны соблюдаться при литературной обработке результатов статистического исследования.
Результаты медико-статистического исследования внедряются в практику здравоохранения. Возможны различные варианты использования результатов исследования: ознакомление с результатами широкой аудитории медицинских и научных работников; подготовка инструктивно-методических документов; оформление рационализаторского предложения и другие
По завершении статистического исследования разрабатываются рекомендации и управленческие решения, проводится внедрение результатов исследования в практику, оценивается эффективность.
Ошибки статистического анализа. Наиболее частые ошибки можно сгруппировать следующим образом:
1) методические ошибки;
2) неправильная оценка показателей;
3) логические ошибки формального анализа.
К первой группе — методическим ошибкам — относят дефекты программы и плана исследования, которые чаще всего заключаются в следующем:
· неправильное определение единицы наблюдения, в связи с чем формируется неоднородная статистическая совокупность, что не позволяет выявить закономерности и сделать правильные выводы;
· недостаточное число наблюдений ведет к получению недостоверных результатов, поэтому следует рассчитывать необходимый объем наблюдений по нескольким результирующим признакам;
· использование слишком сложных таблиц, содержащих много признаков (более 3—4 статистических сказуемых при одном статистическом подлежащем) и приводящее к дроблению материала и получению малочисленных групп, при этом трудно доказать достоверность полученных результатов и невозможно сделать обоснованные выводы.
Вторая группа ошибок обусловлена недостатками, которые связаны с расчетами, неправильным выбором статистического метода обработки полученного материала и неправильной оценкой статистических величин. К ним относятся:.
· арифметические ошибки, при этом целесообразно проводить проверку и перепроверку различных вычислений, особенно когда возникает неожиданный результат;
· недостаточная статистическая обработка данных, когда вывод делается только на основании анализа абсолютных чисел; не составлены динамические ряды, не рассчитаны относительные и средние величины, не доказана их достоверность, не рассчитаны коэффициенты корреляции и т. д.;
· неправильная оценка показателей и прежде всего экстенсивных, для сравнения которых следует использовать формулу сравнения показателей (см. ранее), а вывод о больших или меньших масштабах каких-то явлений или процессов можно и нужно делать только на основании анализа интенсивных показателей;
· сравнение результатов, полученных в качественно неоднородных или искусственно отобранных группах (например, при апробации нового медикаментозного средства для лечения какого-то заболевания среди пациентов с определенными показаниями нельзя сделать вывод, что это средство дает лучший эффект по сравнению с другими препаратами, лечение которыми может быть несколько менее эффективно, но применение их не имеет противопоказаний);
· оценка темпа роста без учета исходного уровня показателей, поскольку известно, что в соответствии со статистической закономерностью, чем ниже исходный уровень каждого явления, тем выше темп роста, и наоборот;
· неиспользование метода стандартизации при анализе показателей в неоднородных статистических совокупностях.
Третья группа ошибок статистического анализа включает в себя логические ошибки формального анализа, которые можно сгруппировать следующим образом:
· выводы, которые сделаны на основе простого сравнения цифр без учета качественной характеристики явления, в связи с чем не учитываются причины, способствующие возникновению изучаемого явления, и затруднена разработка мероприятий, направленных на воздействие, управление изучаемыми явлениями, процессами;
· выводы, сделанные по принципу "после этого, значит вследствие этого", что неверно (например, у пациента с гипертонической болезнью обострение наступило после ссоры с соседями по квартире, но это не означает, что ссора с соседями явилась причиной обострения, поскольку и проживание в коммунальной квартире, и наличие самого заболевания нельзя не учитывать в профилактической работе с данными пациентом).
Таким образом, статистический анализ — это не только анализ цифр и явлений, но и в значительной мере искусство специалиста, умение выделить из ряда последовательных событий ведущие, установить достоверную связь между ними, наметить пути воздействия.
КОНТРОЛЬНЫЕ ВОПРОСЫ
1. Организация статистического исследования.
2. Этапы статистического исследования.
3. I этап статистического исследования. Цель и задачи исследования.
4. Организационный план статистического исследования. Разработка плана исследования.
5. Программа статистического исследования.
6. Определение единицы наблюдения и составление программы сбора материала.
7. II этап статистического исследования. Сбор материала (статистическое наблюдение). Виды статистического наблюдения.
8. Виды статистического наблюдения по времени регистрации.
9. Виды статистического наблюдения по полноте охвата единиц совокупности.
10. III этап статистического исследования.Разработка материала, статистическая группировка и сводка.
11. Первое свойство статистической совокупности
12. Второе свойство статистической совокупности
13. Третье свойство статистической совокупности
14. Четвертое свойство статистической совокупности
15. Пятое свойство статистической совокупности
16. Статистические таблицы. Составные части таблицы.
17. Виды статистических таблиц.
18. IV этап статистического исследования.Статистический анализ изучаемого явления, формулировка выводов.

