 2018-02-14
2018-02-14 391
391Дискриминантный анализ является разделом многомерного статистического анализа, который включает в себя методы классификации многомерных наблюдений по принципу максимального сходства при наличии обучающих признаков.
Напомним, что в кластерном анализе рассматриваются методы многомерной классификации без обучения. В дискрими-нантном анализе новые кластеры не образуются, а формулируется правило, по которому объекты подмножества подлежащего классификации относятся к одному из уже существующих (обучающих) подмножеств (классов), на основе сравнения величины дискриминантной функции классифицируемого объекта, рассчитанной по дискриминантным переменным, с некоторой константой дискриминации.
Предположим, что существуют две или более совокупности (группы) и что мы располагаем множеством выборочных наблюдений над ними. Основная задача дискриминантного анализа состоит в построении с помощью этих выборочных наблюдений правила, позволяющего отнести новое наблюдение к одной из совокупностей.
Постановка задачи дискриминантного анализа. Пусть имеется множество М единиц N объектов наблюдения, каждая i-я единица которого описывается совокупностью р значений дискриминантных переменных (признаков) хij, (i=1,2,..., N; j = 1,2,..., р). Причем все множество М объектов включает q обучающих подмножеств (q≥ 2) Mk размером nk каждое и подмножество M0 объектов подлежащих дискриминации (под дискриминацией понимается различие). Здесь k – номер подмножества (класса), k = 1,2,..., q.
Требуется установить правило (линейную или нелинейную дискриминантную функцию f(X)) распределения m-объектов подмножества M0 по подмножествам Mk.
Наиболее часто используется линейная форма дискриминантной функции, которая представляется в виде скалярного произведения векторов А=(а1,а2,...,аp дискриминантных множителей и вектора Хi=(хi1,хi2,…,хip) дискриминантных переменных:
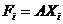
или 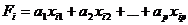
Здесь Xi – транспонированный вектор дискриминантных переменных; хij — значений j-х признаков у i-го объекта наблюдения.








