 2020-04-20
2020-04-20 213
213
Теперь познакомимся ещё с одним видом стеганографии, который в определённых случаях может оказаться настолько сложным для взлома, что иной криптоаналитик за голову схватится, но всё равно взломать не сможет. Этот способ очень сложен, поскольку информация прячется в тексте, который должен быть вполне обычным, чтобы не вызвать подозрений своей необычностью у криптоаналитика.
Представьте, что у переписывающихся лиц есть два канала передачи информации. Первый канал «абсолютно» закрыт (слово «абсолютно» взято в кавычки, потому что настоящую закрытость реализовать практически невозможно). К примеру, один из каналов – личное общение двух лиц тет‑а‑тет в закрытом помещении, проверенном на отсутствие прослушивающих устройств. Следовательно, эти лица могут обменяться какой‑то информацией. Само собой разумеется, что при помощи такого канала лучше всего обмениваться ключами, то есть информацией о том, как расшифровывать сообщения, посылаемые по другому каналу.
Другой канал – «открытый», поскольку в нём существует риск перехвата сообщения. Отправка писем (как обычных, так и незашифрованных электронных), телефонные переговоры, печатание объявлений в газетах – это всё примеры открытых каналов. Злоумышленник может получить доступ к передаваемой информации. Передавать секретную информацию в незашифрованном виде по открытому каналу нельзя, и именно поэтому необходим закрытый канал, чтобы договориться о способе шифрования. Потом уже, если способ шифрования достаточно сложен для взлома, можно обмениваться информацией по открытому каналу: технически это намного проще, но злоумышленник уже не сможет так просто получить секретную информацию.
Например, если мы договоримся, что в некотором тексте надо читать только каждую пятую букву, то это будет довольно серьёзный способ сокрытия. Не каждый начинающий криптоаналитик догадается, что надо сделать, чтобы найти секретное сообщение, особенно если оно короткое. В особенности, если текст, в котором считаются буквы, представляет собой связное и адекватное повествование. Если же текст неадекватен (похож, к примеру, на бессвязные творения поэтов‑авангардистов), то криптоаналитик с опытом поймёт подвох и сможет, проведя статистический анализ по разным критериям, в конце концов взломать секретное сообщение. Если же сообщение представляет собой случайный набор символов (поле букв), то оно тем более будет взломано, причём намного быстрее.
Понятно, что составить текст, в котором содержится тайное сообщение, так, чтобы он был адекватным, но при этом на нужных местах были правильные буквы, очень сложно. Намного сложнее, чем скрывать смысл сообщений при помощи шифров простой алфавитной замены. Например, пусть надо спрятать сообщение «ЗАВТРА НАЧНУ» в тексте так, чтобы читать надо было каждую пятую букву. Начинаем с простого:
«−−−−З−−−−А−−−−В−−−−Т−−−−Р−−−−А−−−−Н−−−−А−−−−Ч−−−−Н−−−−У*».
Теперь вместо знаков подчёркивания «−» подбираем буквы так, чтобы они составили вполне обычный текст, который не должен вызвать подозрения у криптоаналитика. Это сродни составлению кроссвордов.
Например, это может быть что‑то такое: «У НЕЁ З АВТР А К БЫЛ В ДЕВЯ Т Ь. ТАК Р АНО С А МОЙ И Н АГОЙ А ННЕ О Ч КИ НЕ Н УЖНЫ. У ШЛА». Как видно, текст странный, так письма не пишут. Поэтому, как говорилось ранее, составить нормальный текст затруднительно.
А можно пойти другим путём. Например, таким способом можно записать несколько сообщений, в том числе противоречащих друг другу, перемешав их буквы. Например, вот текст: «ЗСПСП АЕРПР ВГИАИ ТОДСВ РДУИЕ АНЗБЗ НЯАОИ АУВТМ ЧЕТЕЯ НДРБС УУАЕО». Если выписать эти пятибуквенные сочетания одно под другим в столбик, то в пяти столбцах можно будет прочитать пять разных посланий. Но какое из них нужное? Впрочем, получив эти расшифровки, криптоаналитик может учесть содержание каждой, так что такой способ сокрытия тайн тоже не очень хорош.
В общем, тут есть огромные возможности для экспериментов и изысканий. Главное – как было написано в начале этого раздела, необходимо договориться о способе передачи тайной информации.
Наконец, можно рассказать ещё об одном методе, самом простом в рассматриваемом классе. По его наименованию можно назвать всю группу – «Тарабарская грамота». Им мы на этой неделе и займёмся. Суть этого метода заключается в том, что сообщение прячется среди символов из других алфавитов. При этом читать надо только буквы русского гражданского письма, а остальные игнорировать. Примерно вот так: «ZСIWЕГ QUОLNД FIНUЯ DUПRОD ЕQДLЕSМ НRАQUSL ДRЕJUЛОN». Тут буквы кириллицы перемешаны с буквами латиницы. Вычёркиваем из этого текста все латинские буквы, которых нет в русском языке, и получаем открытый текст.
Тут можно использовать такой нюанс. В латинском и русском алфавитах есть набор символов, которые совпадают по начертанию. Это следующие символы: A B C E H K M O P T X Y (12 символов). Что, если составить открытое сообщение только из этих символов? Это сложно, но возможно. Вот несколько примеров слов, которые можно из них составить: ВЕСНА, РОТ, АВТОХТОН, МОРЕ, МОРЕНА, ТОРТ, КАМОРКА, KYPOPT и т. д. Можно составить огромное количество таких слов. Вероятно, можно составить и тайное послание. Тогда эти слова можно спрятать среди латинских букв. Тогда у криптоаналитика возникнет меньше подозрений, чем если он будет смотреть на предыдущий текст, в котором были перемешаны символы латиницы и кириллицы. Также можно придумать систему кодирования из двух таких символов, и при помощи таких пар кодировать все буквы русского алфавита.
То же самое можно сделать и с греческим алфавитом, который более похож на кириллицу. Вот совпадающие символы: Α Β Γ Ε Η Κ Λ Μ Ο Π Ρ Τ Φ Χ (14 символов). С ними можно поступить абсолютно так же, как и с латиницей.
Возьмём латиницу (все знают латиницу, лишь немногие знают греческий алфавит). Закодируем тайное послание при помощи упомянутых двенадцати символов. Затем подберём слова на английском языке, в которых содержатся эти символы, но только те, что нам нужны. Подобрать такие слова намного легче, нежели решать задачу, с которой мы боролись ранее. Например, давайте попробуем закодировать то же самое послание «ЗАВТРА НАЧНУ». Пусть код выглядит следующим образом (снова воспользуемся алфавитом из тридцати двух символов для единообразия):
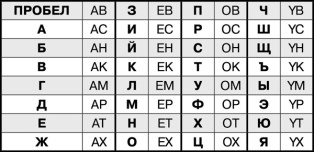
Внезапно оказалось кстати, что 32 = 4 × 8, а 12 = 4 + 8, и среди этих двенадцати символов 4 гласных и 8 согласных. Поэтому код получился очень забавным – это двухбуквенный код, где на первом месте стоит гласная, а на втором согласная буква. Гласная буква определяет номер четвёрки (то есть столбец, в котором записана шифруемая буква), а согласная – позицию внутри четвёрки. Всё очень логично. Кстати, хоть это и красиво, но сразу же снижает ценность кода, поскольку любая регулярность даёт криптоаналитику подсказки для взлома. Но сейчас мы воспользуемся именно таким методом.
Итак, наше послание
«ЗАВТРА НАЧНУ»
перекодируется при помощи созданного кода в такую последовательность:
«EBACAKOKOCACABETACYBETOM».
Здесь 24 символа латинского алфавита, из которых надо составить список английский слов. Например, вот так:
ZEBRA CAN KOFF KLON CAR UCLA BETA CYBER TIRO MUZZ
Опять же, не очень‑то складно (вообще нескладно), но это свойство всех подобных способов сокрытия информации.
Итак, на текущей неделе необходимо сделать следующее:
1. Придумать короткое сообщение, которое будет скрыто в тарабарской грамоте.
2. Закодировать его при помощи приведённой выше таблицы.
3. Придумать англоязычный текст, в котором будет скрыто сообщение.
4. Написать обычное письмо своему ребёнку, а в качестве одного из абзацев привести сгенерированный на предыдущем шаге текст на английском языке. Хорошо, если само письмо будет как‑то обыгрывать эту вставку английского текста.
5. Далее, надо быть готовым помочь ребёнку с расшифровкой, поскольку у него могут возникнуть затруднения, особенно если ещё не совсем хорошо знает латинский алфавит.
Кстати, задачка для вдумчивого читателя и неназойливых размышлений на досуге. Конечно же, для английского языка тоже есть таблица частоты проявления символов. Можно составить новую таблицу двухбуквенной кодировки при помощи двенадцати символов, в которой будут учтены частоты встречаемости букв как в русском, так и в английском языке. Например, буква «E» встречается в английском языке чаще всего, за ней на втором месте стоит буква «T», так что резонно код «ET» отдать пробелу. А вот буква «X» встречается очень редко, равно как и буква «Y», так что код «YX» отдаётся букве «Ъ». И так далее.








