2020-04-20
2020-04-20 522
522
При оцінки рівня розвитку регіону дуже важливою є його поведінка у майбутньому. Щоб спрогнозувати розвиток регіону у майбутніх періодах є доцільним використання методів прогнозування. Розглянемо основні з них.
Перш ніж проводити детальне вивчення рівнів часового ряду або виявлення тенденцій необхідно провести згладжування або механічне вирівнювання динамічного ряду. Суть різних прийомів, за допомогою яких здійснюється згладжування і вирівнювання, зводиться до заміни фактичних рівнів динамічного ряду розрахунковими, мають значно меншу коливається, ніж початкові дані.
Серед методів згладжування часового ряду найбільш часто використовують метод простої ковзаючої середньої, метод зваженої ковзаючої середньої, метод експоненціальної середньої.
Просте згладжування грунтується на складанні нового ряду з простих середніх арифметичних обчислених для лага ковзання m. Звичайно m=2k+1, тоді значення середньої в точці i буде таким:
 (2.37)
(2.37)
Експоненціальне згладжування ряду здійснюється по реккурентной формулі:
= αYt + (1 - α)* St-1 (2.38)
де St - значення експоненціальної середньої у момент t;
α - параметр згладжування, 0<a<1.
При використовуванні методу експоненціальній середній виникають дві проблеми: 1) вибір параметра α (якщо слід збільшити внесок попереднього значення, то α вибирають близьким до одиниці, якщо ж переслідується зворотна мета, усунути вплив окремих попередніх значень часового ряду, то використовують малі значення параметра α; 2) вибір початкового значення S0, звичайно вважають S0 або рівним першому значенню часового ряду, або середньоарифметичним декількох початкових членів ряду.
Експоненціальна середня часто використовується для короткострокового прогнозування. Гідністю експоненціальної середньої є адаптація моделі до розвитку економічного процесу при різних значеннях α.
При аналізі складних часових рядів важливою є задача дослідження часових рядів з урахуванням їх тенденцій, дії сезонних і циклічних складових, що відображають вплив різних чинників соціально-економічного, політичного і природного характеру.
Розвиток моделей адаптивного прогнозування є моделі, що поєднують в собі елементи адаптивного згладжування і елементи, що дозволяють виділити впливи лінійного і нелінійних трендів.
В практиці статистичного прогнозування найбільш часто використовуються дві базові моделі Брауна і Холта. Ці моделі представляють процес розвитку як тенденцію з параметрами, що постійно змінюються.
Прогнозна оцінка період попередження рівня ряду  обчислюється у момент часу по наступній формулі:
обчислюється у момент часу по наступній формулі:
 (2.39)
(2.39)
де  параметр постійно що змінюється
параметр постійно що змінюється
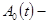 оцінка поточного t-ого рівня
оцінка поточного t-ого рівня
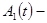 оцінка поточного приросту
оцінка поточного приросту
Крім того, визначається величина розбіжності реальних і прогнозних оцінок, за наступною формулою:
 (2.40)
(2.40)
Знайдені вирази для помилок враховуються при коректуванні параметрів моделі по методів Брауна і по методу Холта.
В моделі Брауна
 , (2.41)
, (2.41)
 (2.42)
(2.42)
де  - це коефіцієнт дисконтування даних що змінюється в межах від 1 до 0.
- це коефіцієнт дисконтування даних що змінюється в межах від 1 до 0.
 - коефіцієнт згладжування що знаходиться від 0 до 1
- коефіцієнт згладжування що знаходиться від 0 до 1  .
.
 - це помилка прогнозування рівня
- це помилка прогнозування рівня 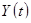 .
.
В моделі Холта коефіцієнт модифікується таким чином:
 , (2.43)
, (2.43)
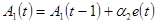 (2.44)
(2.44)
Параметри А0 і А1 обчислюються послідовно від рівня до рівня, початкові значення параметрів оцінюються по методу якнайменших квадратів на основі декількох рівнів ряду. Коефіцієнт А0 це значення близьке до подальшого рівня і воно представляє закономірність складову цього рівня. Коефіцієнт А1 визначає приріст, що сформувався в основному до кінця періоду спостереження, але що відображає так само у меншій мірі швидкість росту і на більш ранніх етапах.
Існують наступні моделі для опису такої моделі.
а) метод Холта [10]. Цей метод заснований на оцінці параметра у міру ступеня лінійного зростання (або падіння) показника в часі. Чинник зростання I оцінюється по коефіцієнту лінійного зростання bt, яке у свою чергу обчислюється як експоненціально зважене середнє різниці між поточними експоненціально зваженими середніми значеннями процесу ut і їх попередніми значеннями ut-1. Характерна особливість даного методу: обчислення поточного значення експоненціально зваженого середнього ut включає обчислення минулого показника зростання bt-1, пристосовуючись таким чином до попереднього значення лінійного тренда.
Перш ніж приступити до прогнозування по тій або іншій прогностичній моделі тренда, необхідно уточнити період, на який здійснюється прогноз. Вважатимемо, що прогноз обчислюється на ф моментів часу вперед (період установи), тобто до моменту t+т (горизонт прогнозування).
Після оцінки в моделі Холта показник зростання (або падіння) прогноз на т моментів часу, тобто ft+T, обчислюється підсумовуванням оцінки середнього поточного значення (ut) і очікуваного показника зростання bt помноженого на кількість моментів часу прогнозування т.
б) метод Холта з модифікаціями Муїра [10]. Муїр показав, що значення показника зростання bt співпадає з оцінкою коефіцієнта лінійного тренда по методу якнайменших квадратів; іншими словами, bt мінімізує суму квадратів відхилень фактичного значення dt від його тренда.
Модель Брауна може відображати розвиток не тільки у вигляді лінійної тенденції, але і у вигляді випадкового процесу не має тенденції. Розрізняють наступні класифікації моделі Брауна:
1) моделі нульового порядку - ці моделі відображають процеси не мають тенденції розвитку. Ця модель заснована на оцінці поточного рівня, на підставі якого і будується прогноз;
2) модель першого порядку -
) модель другого порядку - відображає розвитку у вигляді параболічної тенденції з швидкістю і прискоренням, що змінюється.
Ця модель має три параметри А0, А1 і А2. Параметр А2 це оцінка поточного приросту або прискорення. Прогноз здійснюється:
 . (2.45)
. (2.45)
Межі довірчого інтервалу визначаються на основі точкової оцінки і в значенні помилок прогнозу. Помилка прогнозу розраховується по наступній формулі:
 (2.46),
(2.46),
де  відхилення помилок моделей прогнозування;
відхилення помилок моделей прогнозування;
 розраховується для моделей різного ступеня складності (від 0 до 2 порядків) по наступних формулах
розраховується для моделей різного ступеня складності (від 0 до 2 порядків) по наступних формулах
для моделей 0 порядку:
 ; (2.47)
; (2.47)
для моделей 1 порядку:
 (2.48)
(2.48)
для моделей 2 порядки:
 (2.49)
(2.49)
Крім того існують наступні методи Брауна:
1) метод подвійного згладжування Брауна [11]. Як показав Браун, в умовах лінійного тренда простої експоненціально зважене середнє все менше лінійного тренда.
Браун показав також, що подвійне експоненціально зважене середнє ut, що задається рівнянням:
 (2.50)
(2.50)
також менше первинного ковзаючого середнього ut на ту ж величину, на яку ut менше dt. Проте в умовах стійкості можна фактичну різницю прирівняти до її оцінки.
Гідність методу Брауна в однопараметричності:
г) метод адаптивного згладжування Брауна [И]. Згідно другому методу Брауна передбачається, що якщо, наприклад, ряд значень продажів або попиту можна описати деякою моделлю, то логічніше всього було б застосування регресійного аналізу (коли мінімізується сума квадратів) на основі зваженої регресії, тобто більша увага необхідно уділити більш свіжій інформації. Здається вельми розумним, що з погляду прогнозу важливість кожного спостереження при відліку справа наліво повинна з кожним моментом часу убувати. Значить, якщо у момент часу t прогноз продажів або попиту на момент часу t + т описується рівнянням:
 (2.51)
(2.51)
де еt - випадкове відхилення з нульовим середнім, то, задаючись деяким г (відповідним рівню щомісячного дисконтування спостережень), на момент часу t виберемо а0, а1 і а2 так, щоб:
 (2.52)
(2.52)
Іншими словами, константи ат, a1і а2 на момент часу t вибираються так, щоб зважена сума квадратів відхилень між спостережуваними і очікуваними значеннями зверталася в мінімум. Очевидно, здійснювати на кожному кроці прогнозу такої складної процедури не має значення. Метод Брауна грунтується на дуже простому способі обчислення оцінок по методу зважених якнайменших квадратів dt у випадку лінійно - адитивного тренда.
В цих моделей коефіцієнт згладжування характеризує ступені адаптації моделі до зміни ряду спостережень. Вони визначають швидкість реакції моделі на зміну, що відбуваються в розвитку досліджуваного показника.
Чим коефіцієнт згладжування більше, тим швидше реагує модель на зміни.
Звичайно в стійких рядах їх величини більше, а для нестійких рядів слід вибирати величину параметра  менше.
менше.
В різних методах програмування використовуються різні підходи до визначення коефіцієнт згладжування. Іноді коефіцієнт згладжування берутьфіксований (постійним на всіх інтервалах згладжування), а іноді використовують динамічну зміну параметрів згладжування. Параметри згладжування можна визначити методом підбору так, щоб помилка прогнозу була якнайменшою.
В методах еволюції і симплекс-плануванні параметр адаптації змінюється на кожному кроці, для кожного коефіцієнта згладжування задається декілька значень, кожний набір параметрів згладжування розглядається як одна крапка в багатовимірному просторі.
Існують методи еволюції або симплекс-планування дозволяючі знайти якнайкращий варіант зміни параметрів.
Суть цих методів полягають в тому, що пошук оптимальних параметрів направлений на якнайшвидші усунення помилок прогнозування.
Іншим методом який слідує розглянути є метод Тейла Вейджа.
В цьому методі використовується лінійна модель, параметри якої коректуються по схемі моделі Холта, але в ній в явному вигляді враховується погрішність визначення параметра приросту. Для конкретного процесу розвиток якого характеризується параболічною тенденцією, існують методи оптимального співвідношення для параметрів згладжування.
Іноді як адаптивні моделі прогнозування використовують моделі, засновані на авторегресії. Авторегресійні моделей достатньо добре описує коливання показників ряду і можуть бути використаний для відображення нестійких тенденцій. В цьому випадку з такого ряду усувають тренд і досліджують стаціонарний ряд на коливання за допомогою методів авторегресії.
Крім того існує ще ряд методів згладжування
) метод Боксу - Дженкинса [12]. Спочатку цей метод використовувався в теорії управління і, таким чином, не був спеціально розроблений для прогнозування попиту.
Вард на основі z - перетворення показав, що і метод Холта і метод подвійного експоненціального згладжування Брауна, і метод Боксу - Дженкинса є окремі випадки більш загальної моделі, причому всі вони співпадають, якщо значення параметрів А, В, г1, г-1 і г0 є пов'язаний з параметром би наступними співвідношеннями:
 (2.53)
(2.53)
 (2.54)
(2.54)
2) метод Муїра [12]. Іноді зміна середнього процесу залежить від часу не лінійно, а пропорційно самому значенню середнього м (тобто лінійно в логарифмах). Тоді більш відповідною буде мультиплікативна модель.
Тепер (як і в аддитивному випадку) можна застосувати ту ж згладжуючу функцію ut, позначивши її через нt
Варто звернути увагу, що мультиплікативні тренди зводяться до лінійних заміною фактичних спостережень їх логарифмами.
3) Сезонно-декомпозиційна прогностична модель Холта Вінтера [12]. Вона заснована на застосуванні методу експоненціально зваженого середнього. Оцінка стаціонарно - лінійного і сезонного чинників для неї проводиться таким чином.
Оцінка стаціонарного чинника (тобто оцінка середньомісячно значення незалежно від пори року). Рівняння оцінки стаціонарного чинника таке ж, як і у випадку раннє розглянутого методу Холта. При цьому передбачається, що ряд поточних значень dt обчищений від сезонності розподілом його на величину Ft.L - коефіцієнт сезонної декомпозиції (або просто сезонності), відповідний момент часу t - L, тобто зсунутому на L - одиниць часу тому.
Оцінка лінійного зростання обчислюється на основі моделі зростання Холта:
Оцінка сезонного чинника (пристосовування коефіцієнта сезонності). Коефіцієнт сезонності є відношенням значення поточного спостереження до середньостаціонарного значення, тобто цей коефіцієнт у момент часу t рівний dt/ut.
прогноз. При ізольованій оцінці трьох чинників, визначальних рух процесу, прогноз на т моментів часу вперед (ft+T) будується з трьох елементів: підсумовуються оцінка лінійного зростання і оцінка стаціонарного чинника ut, і результат з урахуванням сезонності домножається на відповідне значення коефіцієнта сезонності Ft-L+T:
Через відносну складність модель Холта - Вінтера, як правило, використовується тільки за наявності ЕОМ або програмованого калькулятора.
Тамара показав, як у випадку сезонно - адитивного характеру попиту прогноз може бути збільшений за умови рівності одиниці середнього всіх коефіцієнтів сезонності року, попереднього року прогнозування.
Підвищення точності прогнозу в цьому випадку пояснюється тим, що теоретично, та і практично, коефіцієнти сезонності, обчислювані по стандартній схемі моделі експоненціального згладжування, мають середнє, відмінне від одиниці. Це у свою чергу приводить до зсуву прогнозів вгору або вниз залежно від того, чи буде середнє значення коефіцієнта сезонності більше або менше одиниці. Тамара також встановив, що в більшості практичних ситуацій значення А, В і З, рівні відповідно 0,2, 0,2 і 0,5, виявляються самими задовільними. Вінтер в більш ранній роботі також отримав близькі значення цих коефіцієнтів 0,2, 0,2 і 0,6 відповідно, що приводить до якнайменшої стандартної помилки прогнозу.
) Узагальнений адаптивно-згладжуючий метод Брауна [11]. Цей метод майже повністю співпадає з вже описаним зваженим методом якнайменших квадратів. Різниця полягає в складнішому (в другому випадку) виборі моделі, на основі якої будується зважена регресія.
Харрісон показав, що в умовах застосування адаптивного згладжування Брауна до сезонних моделей значення у (коефіцієнт дисконтування регресії) повинно бути достатньо велике, щоб додати значущу вагу, принаймні, останнім десяти точкам спостереження, і в той же час повинне бути достатньо малим, щоб виконувалася умова локальної адекватності моделі. Така суперечлива рекомендація часто робить модель Брауна непридатною, але не в умовах лінійного тренда.
5) комбінація лінійного і сезонно - мультиплікативного тренда [13]. Ця модель припускає генерацію процесу лінійно - мультиплікативним трендом.
Експоненціально зважене середнє (ut) для випадку мультиплікативного тренда, при тих же аргументах, що і для аддитивної моделі необхідно одержувати по формулі:
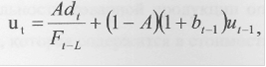 (2.55)
(2.55)
де показник лінійного зростання (bt) знаходиться з рівняння:
 (2.56)
(2.56)
Остаточно прогноз по цій моделі розраховується за допомогою формули:
 (2.57)
(2.57)
) Авторегресі. При аналізі економічних рядів динаміки, може виявитися, що значення досліджуваного явища у момент часу t знаходитися у функціональній залежності від значень явища в попередній момент часу. Такі ряди динаміки називаються авторегресійними рядами динаміки.
В загальному вигляді авторегресійна модель може бути представлений наступному показуючому ефект рівнянням:
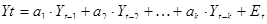 (2.58)
(2.58)
а1, а2, ак - коефіцієнт авторегресійної моделі;
к - порядок авторегресійної моделі;- помилка, випадкова состовляющая.
Параметри авторегресії аi звичайно оцінюються методом найменших квадратів.
Існують різні методи визначення порядку авторегресії, розглянемо суть першого методу.
Для знайдених значень Et розраховуємо коефіцієнти: циклічна кореляція
 (2.59)
(2.59)
Знайдені значення послідовності з коефіцієнтів циклічної кореляції r1, r2, rn-k-1 перевіряються по відповідній таблиці значущості (можна замість таблиці використовувати критерій Стьюдента для рівняння значущості  або).
або).
Якщо при деякому значенні i значення ri істотно, тобто існує автокореляція залишків Et то порядок початкового рівняння авторегресії слід збільшити.
Для визначення порядку авторегресії може використовуватися критерій Неймана.
Розраховується значення Q по критерію Неймана і сравниваються з пороговим значенням по відповідних таблицях для і  .
.
Якщо розрахункове значення Q потрапляє в допустиму область при 5% рівня значущості то приймається гіпотеза про неавтокоррелирования залишків і як базова модель приймається модель до - ого порядку.
Якщо розрахункове значення Q потрапляє в критичну область при 1% рівні значущості, то гіпотеза про неавтокоррелирования залишків відкидається і необхідно збільшити порядок авторегресійної моделі.
-ий метод: одним із способів визначення порядку авторегресії заснований на исследованири залишковій дисперсії отриманої при включенні в модель різної кількості минулих значень. Якщо в початковій моделі використовується недостатня кількість рівнів попередніх періодів, то залишкова дисперсія буде завишена, за рахунок тих рівнів які не були внесені в модель.
Якщо оцінювати залишкову дисперсію як функцію від порядку авторегресійної моделі, то оптимальний порядок авторегресійної моделі відповідатиме значенню де функція 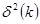 - приймає мінімальне значення або стає пологою.
- приймає мінімальне значення або стає пологою.
Таким чином, розглянуті моделі можуть бути використані для аналізу розвитку регіонів.