 2014-02-02
2014-02-02 13438
13438Системы кодирования и классификации экономической информации.
Простейшие системы кодирования и классификации:
1. Классификация не требуется, тогда производится нумерация объектов, и кодом каждого объекта является его порядковый номер. Такая система кодирования называется порядковой.
2. Множество объектов классифицируется по одному признаку; коды объектов делятся на несколько частей (серий) по количеству значений признака, а в пределах каждой серии используются порядковые номера.
3. Используются несколько классификационных признаков, их взаимная подчиненность соответствует выделению классов объектов, подклассов внутри классов и т.д. Здесь удобна разрядная система кодирования.
Разрядная система кодирования применяется для кодирования объектов, определяемых несколькими соподчиненными признаками. Кодируемые объекты систематизируются по классификационным признакам на каждой ступени классификации. Каждому признаку отводится определенное число разрядов, в пределах которого кодирование начинается с единицы. Классификационные группировки по младшим признакам кодируются в зависимости от кода более старшего признака.
7. Модели данных: концептуальные, логические и физические.
Организация данных во внутримашинной сфере характеризуется на двух уровнях: логическом и физическом. Физическая организация данных определяет способ размещения данных на машинном носителе.
Пользователь, как правило, при работе с программным обеспечением и данными оперирует логической организацией данных (ЛОД). Она определяется типом структур данных и видом модели данных, которая поддерживается применяемым ПО.
Модель данных – это совокупность взаимосвязанных структур данных и операций над этими структурами. Вид модели и используемые в ней типы структур данных отражают организацию и обработку данных, используемых в СУБД, поддерживающих эту модель, или в языке программирования, на котором создается прикладная программа обработки данных.
Выбор модели определяется объемом решаемой задачи, требуемым быстродействием, необходимостью обеспечения целостности и безопасности данных (защита от несанкционированного доступа), предпочтениями пользователя, возможностью аппаратных средств.
Модели данных делятся на две группы: синтаксические и семантические. Синтаксические связаны с формой представления данных, а семантические определяются содержанием.
Описание хранимой и обрабатываемой информации в ЭИС делается с разной степенью детализации. Различают 3 уровня детализации:
1. Внешний уровень - описание информационных потребностей конечного пользователя.
2. Концептуальный уровень - описание информационных потребностей на уровне ЭИС.
3. Внутренний уровень - описание способов хранения информации в памяти ЭВМ и методов доступа к ней.
Информационные потребности отдельного пользователя относятся лишь к некоторой части БД, описание этих потребностей может не совпадать с хранимыми в ЭИС представлениями данных.
Внешнее представление может пользоваться любым аппаратом понятий. Основное требование к внешнему представлению - возможность преобразования его в концептуальные представления. Цель концептуального уровня - создать такое представление о БД, чтобы любое внешнее представление являлось его подмножеством. В процессе интеграции внешних представлений устраняются двусмысленности и противоречия в информационных потребностях различных пользователей. Допускается множество внешних описаний, каждое из которых отображается частью БД, и единственное концептуальное описание, представляющее всю БД.
Внешний уровень достаточен для применения ряда прикладных программ, который можно назвать генератором отчетов. Поток входной информации преобразуется в поток выходной информации, который оформляется в виде отчетов, удобных для использования специалистами.
Концептуальное представление описывает полное информационное содержание БД в более абстрактной форме по сравнению со способом физического хранения данных. В нем необходимы не только сведения о структуре обрабатываемой информации, но и сведения о технологии ее обработки.
Концептуальный уровень описания оказывается достаточным для использования программной поддержки СУБД. Его при этом необходимо трансформировать к требованиям конкретной СУБД. После такого преобразования возможно наиболее эффективное использование этой СУБД, упрощаются проблемы разработки программного обеспечения системы, сокращаются сроки разработки ЭИС.
К концептуальному представлению предъявляется требование устойчивости. Это означает, что изменения в предметной области не должны приводить к обязательной корректировке концептуального представления. Оно должно быть достаточно абстрактным, т.е. не содержать ограничений, вытекающих из программной реализации требуемых методов обработки данных.
Для преодоления ограничении реляционной модели и обеспечения потребности проектировщиков базы данных в более удобных и мощных средствах моделирования предметной области проектирование бал данных обычно выполняется не в терминах реляционной модели, а с использованием концептуальных моделей предметной области.
Обычно различают концептуальные модели двух видов:
· объектно-ориентированные модели, в которых сущности реального мира представляются в виде объектов, а не записей реляционных таблиц;
· семантические модели, отражающие значения реальных сущностей и отношений.
Объектно-ориентированную модель можно рассматривать как результат объединения семантической модели данных и объектно-ориентированного языка программирования.
Несмотря на то что в последнее время все большее распространение получают объектно-ориентированные модели, не снижается и значение семантических моделей. Концептуальное моделирование баз данных на основе семантических моделей поддерживается во всех известных CASE-средствах (например, таких как ERWin и Power Designer). Кроме того, семантические модели более просты для понимания, особенно при проектировании сравнительно небольших баз данных. Как и реляционная модель, любая развитая семантическая модель данных ик.'почае структурную, манипуляционную и целостную части. Главным назначением семантических моделей является обеспечение' возможности выражения семантики данных. Целью семантическою моделирования — обеспечение наиболее естественных для человека способов сбора и представления той информации, которую предполагается хранить в создаваемой базе данных. Поэтому семантическую модель данных пытаются строить по аналогии с естественным языком (последний не может быть использован в чистом виде из-за сложности компьютерной обработки в тексте неоднозначности любого естественного языка). Основными конструктивными элементами семантических моделей являются сущности, связи между ними и свойства (атрибуты).
СУБД должна предоставлять доступ к данным любым пользователям, включая и тех, которые практически не имеют и (или) не хотят иметь представления о:
· физическом размещении в памяти данных и их описаний;
· механизмах поиска запрашиваемых данных;
· проблемах, возникающих при одновременном запросе одних и тех же данных многими пользователями (прикладными программами);
· способах обеспечения защиты данных от некорректных обновлений и (или) несанкционированного доступа;
· поддержании баз данных в актуальном состоянии
и множестве других функций СУБД.
При выполнении основных из этих функций СУБД должна использовать различные описания данных. А как создавать эти описания?
Естественно, что проект базы данных надо начинать с анализа предметной области и выявления требований к ней отдельных пользователей (сотрудников организации, для которых создается база данных). Подробнее этот процесс будет рассмотрен ниже, а здесь отметим, что проектирование обычно поручается человеку (группе лиц) – администратору базы данных (АБД). Им может быть как специально выделенный сотрудник организации, так и будущий пользователь базы данных, достаточно хорошо знакомый с машинной обработкой данных.
Объединяя частные представления о содержимом базы данных, полученные в результате опроса пользователей, и свои представления о данных, которые могут потребоваться в будущих приложениях, АБД сначала создает обобщенное неформальное описание создаваемой базы данных. Это описание, выполненное с использованием естественного языка, математических формул, таблиц, графиков и других средств, понятных всем людям, работающих над проектированием базы данных, называют инфологической моделью данных (рис. 1.3).
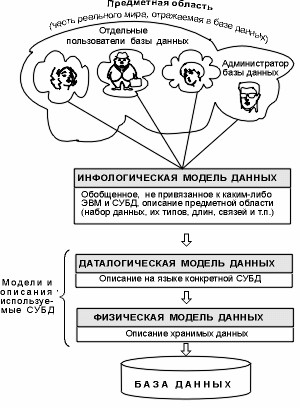
Рис. 1.3. Уровни моделей данных
Такая человеко-ориентированная модель полностью независима от физических параметров среды хранения данных. В конце концов этой средой может быть память человека, а не ЭВМ. Поэтому инфологическая модель не должна изменяться до тех пор, пока какие-то изменения в реальном мире не потребуют изменения в ней некоторого определения, чтобы эта модель продолжала отражать предметную область.
Остальные модели, показанные на рис. 1.3, являются компьютеро-ориентированными. С их помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным лишь по их именам, не заботясь о физическом расположении этих данных. Нужные данные отыскиваются СУБД на внешних запоминающих устройствах по физической модели данных.
Так как указанный доступ осуществляется с помощью конкретной СУБД, то модели должны быть описаны на языке описания данных этой СУБД. Такое описание, создаваемое АБД по инфологической модели данных, называют даталогической моделью данных.
Трехуровневая архитектура (инфологический, даталогический и физический уровни) позволяет обеспечить независимость хранимых данных от использующих их программ. АБД может при необходимости переписать хранимые данные на другие носители информации и (или) реорганизовать их физическую структуру, изменив лишь физическую модель данных. АБД может подключить к системе любое число новых пользователей (новых приложений), дополнив, если надо, даталогическую модель. Указанные изменения физической и даталогической моделей не будут замечены существующими пользователями системы (окажутся "прозрачными" для них), так же как не будут замечены и новые пользователи. Следовательно, независимость данных обеспечивает возможность развития системы баз данных без разрушения существующих приложений.
9. Иерархические, сетевые и реляционные модели представления данных.
ИМД основана на понятии деревьев, состоящих из вершин и ребер. Вершине дерева ставится в соответствие совокупности атрибутов данных, характеризующих некоторый объект. Вершины и ребра дерева как бы образуют иерархическую древовидную структуру, состоящую из n уровней.
Структура записей имеет иерархический характер. Все множество экземпляров записи единицы структуры образует тип записи. Объектом модели данных является запись определенного типа. На схеме агрегат – прямоугольник, элемент – окружность. Корнем иерархической модели является тип записи (договор).
Первую вершину называют корневой вершиной.
Она удовлетворяет условиям:
1. Иерархия начинается с корневой вершины.
2. Каждая вершина соответствует одному или нескольким атрибутам.
3. Hа уровнях с большим номером находятся зависимые вершины. Вершин предшествующего уровня является начальной для новых зависимых вершин.
4. Каждая вершина, находящаяся на уровне i, соединена с одной и только одной вершиной уровня i-1, за исключением корневой вершины.
5. Корневая вершина может быть связана с одной или несколькими зависимыми вершинами.
6. Доступ к каждой вершине происходит через корневую по единственному пути
7. Существует произвольное количество вершин каждого уровня.
Иерархическая модель данных состоит из нескольких деревьев, т.е. является лесом. Каждая корневая вершин образует начало записи логической базы данных. В ИМД вершины, находящиеся на уровне i, называют порожденными вершинами на уровне i-1.
Основные достоинства ИМД: простота построения и использования, обеспечение определенного уровня независимости данных, простота оценки операционных характеристик.
Основные недостатки: отношение "многие ко многим" реализуется очень сложно, дает громоздкую структуру и требует хранения избыточных данных, что особенно нежелательно на физическом уровне, иерархическая упорядоченность усложняет операции удаления и включения, доступ к любой вершине возможен только через корневую, что увеличивает время доступа.
В иерархической модели выполняются следующие операции над данными:
· Добавление новой записи (при добавлении новой записи должен быть организован уникальный ключ, значение которого однозначно характеризует ее).
· Изменение значения предварительно извлеченной записи (значение ключа при этом не должно изменяться).
· Удаление некоторых записей, при этом удаляются все записи, находящиеся с ней в групповом отношении.
· Извлечение
o Конкретной записи по значению ключа
o Следующей записи (эта операция выполняется в порядке левостороннего обхода дерева)
СЕТЕВАЯ МОДЕЛЬ ДАННЫХ
В СМД элементарные данные и отношения между ними представляются в виде ориентированной сети (вершины - данные, дуги - отношения).
В 1971 году на конференции по языкам систем данных был опубликован официальный стандарт сетевых баз данных, который известен как модель CODASYL.
Сетевые базы данных обладали рядом преимуществ:
· Гибкость. Множественные отношения предок/потомок позволяли сетевой базе данных хранить данные, структура которых была сложнее простой иерархии.
· Стандартизация. Появление стандарта CODASYL популярность сетевой модели, а такие поставщики мини-компьютеров, как Digital Equipment Corporation и Data General, реализовали сетевые СУБД.
· Быстродействие. Вопреки своей большой сложности, сетевые базы данных достигали быстродействия, сравнимого с быстродействием иерархических баз данных. Множества были представлены указателями на физические записи данных, и в некоторых системах администратор мог задать кластеризацию данных на основе множества отношений.
Конечно, у сетевых баз данных были недостатки. Как и иерархические базы данных, сетевые базы данных были очень жесткими. Наборы отношений и структуру записей приходилось задавать наперёд. Изменение структуры базы данных обычно означало перестройку всей базы данных.
Как иерархическая, так и сетевая база данных были инструментами программистов. Реализация пользовательских запросов часто затягивалась на недели и месяцы, и к моменту появления программы информация, которую она предоставляла, часто оказывалась бесполезной.
Над данными сетевой модели можно выполнять следующие действия:
· внести запись в БД (в зависимости от типа включения запись может быть внесена в групповое отношение или нет);
· включить запись в групповое отношение (связать запись с каким-либо владельцем);
· переключить (связать подчиненную запись с записью владельца в том же групповом отношении);
· изменить значение элементов предварительно извлеченной записи;
· извлечь запись либо по значению ключа, либо последовательно в рамках группового отношения;
· удалить – при удалении записи необходимо учитывать классы членства;
· исключить из группового отношения (разорвать связь между записью владельца и подчиненной записью).
Недостатки иерархической и сетевой моделей привели к появлению новой, реляционной модели данных, созданной Коддом в 1970 году и вызвавшей всеобщий интерес. Реляционная модель была попыткой упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы.
Реляционной называется база данных, в которой все данные, доступные пользователю, организованны в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами.
Реляционная СУБД также способна реализовать отношения предок/потомок, однако эти отношения представлены исключительно значениями данных, содержащихся в таблицах.
Ограничения реляционной модели данных:
1. Должны отсутствовать записи-дубликаты
2. Столбцы реляц.таблицы поименованы, поэтому их порядок не важен.
3. Порядок записей может быть произвольным
4. Каждая запись уникальна и однозначно определяется значением ключа.
5. Каждый элемент таблицы называется полем, может быть однозначно определен.
6. В столбце записываются данные одного типа
На значения таблицы накладываются ограничения, которые определяются именем домена и зависят от значения других полей.
Все операции, выполняемые над отношениями, можно разделить на две группы:
1. Операции над отношениями, к которым относятся проекция, соединение и выбор.
2. Операции над множеством, то есть над несколькими отношениями (объединение, пересечение, разность, деление, декартово произведение).

