2014-02-02
2014-02-02 1037
1037Представление и интерпретация функциональных программ
Лекция №20
Принципы построения определений с накапливающим параметром
1. Вводится новая функция с дополнительным аргументом (аккумулятором), в котором накапливаются результаты вычислений.
2. Начальное значение аккумулирующего аргумента задается в равенстве, связывающем старую и новую функции.
3. Те равенства исходной функции, которые соответствуют выходу из рекурсии, заменяются возвращением аккумулятора.
4. Равенства, соответствующие рекурсивному определению, выглядят как обращения к новой функции, в котором аккумулятор получает то значение, которое возвращается исходной функцией.
Возникает вопрос: любую ли функцию можно преобразовать для вычисления с аккумулятором? Очевидно, что ответ на этот вопрос отрицателен. Построение функций с накапливающим параметром — приём не универсальный, и он не гарантирует получения хвостовой рекурсии. С другой стороны, построение определений с накапливающим параметром является делом творческим. В этом процессе необходимы некоторые эвристики.
Определение:
Общий вид рекурсивных определений, позволяющих при трансляции обеспечить вычисления в постоянном объёме памяти через итерацию, называется равенствами в итеративной форме.
Общий вид равенств в итеративной форме может быть описан следующим образом:
fi (pij) = eij
При этом на выражения eij накладываются следующие ограничения:
1. eij — «простое» выражение, т.е. оно не содержит рекурсивных вызовов, а только операции над данными.
2. eij имеет вид fk (vk), при этом vk — последовательность простых выражений. Это и есть хвостовая рекурсия.
3. eij — условное выражение с простым выражением в условии, ветви которого определяются этими же тремя пунктами.
Пришло время уделить некоторое внимание рассмотрению программной реализации списков и списочных структур. Это необходимо для более тонкого понимания того, что происходит во время работы функциональной программы, как на каком-либо реализованном функциональном языке, так и на абстрактном языке.
Каждый объект занимает в памяти машины какое-то место. Однако атомы представляют собой указатели (адреса) на ячейки, в которых содержатся объекты. В этом случае пара z = x: y графически может быть представлена так, как показано на следующем рисунке.
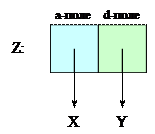
Рисунок 1. Представление пары в памяти компьютера
Адрес ячейки, которая содержит указатели на x и y, и есть объект z. Как видно на рисунке, пара представлена двумя адресами — указатель на голову и указатель на хвост. Традиционно первый указатель (на рисунке выделен голубым цветом) называется a-поле, а второй указатель (на рисунке — зеленоватый) называется d-поле.
Для удобства представления объекты, на которые указывают a- и d-поля, в дальнейшем будут записываться непосредственно в сами поля. Пустой список будет обозначаться перечеркнутым квадратом (указатель ни на что не указывает).
Таким образом, списочная структура, которая рассмотрена несколькими параграфами ранее ([a1, [a2, a3, [a4]], a5]) может быть представлена так, как показано на следующем рисунке:
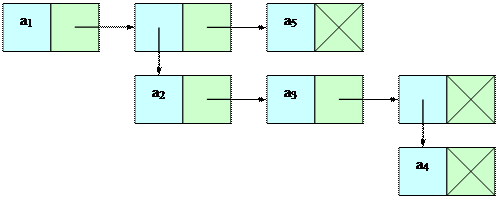
Рисунок 2. Графическое представление списочной структуры [a1, [a2, a3, [a4]], a5]
На этом рисунке также хорошо проиллюстрировано понятие уровня вложенности — атомы a1 и a5 имеют уровень вложенности 1, атомы a2 и a3 — 2, а атом a4 — 3 соответственно.
Остается отметить, что операция prefix требует расхода памяти, ибо при конструировании пары выделяется память под указатели. С другой стороны обе операции head и tail не требуют памяти, они просто возвращают адрес, который содержится соответственно в a- или d-поле.
В первую очередь большинство функциональных языков программирования реализуются как интерпретаторы, следуя традициям Lisp’а. Интерпретаторы удобны для быстрой отладки программ, исключая длительную фазу компиляции, тем самым укорачивая обычный цикл разработки. Однако с другой стороны, интерпретаторы в сравнении с компиляторами обычно проигрывают по скорости выполнения в несколько раз. Поэтому помимо интерпретаторов существуют и компиляторы, генерирующие неплохой машинный код (например, Objective Caml) или код на C/C++ (например, Glasgow Haskell Compiler). Что показательно, практически каждый компилятор с функционального языка реализован на этом же самом языке.
Работа интерпретатора описывается несколькими шагами:
1. В выражении необходимо выделить некоторое обращение к рекурсивной или встроенной функции с полностью означенными аргументами. Если выделенное обращение к встроенной функции существует, то происходит его выполнение и возврат к началу первого шага.
2. Если выделенное на первом шаге обращение к рекурсивной функции, то вместо него подставляется тело функции с фактическими параметрами (т.к. они уже означены). Далее происходит переход на начало первого шага.
3. Если больше обращений нет, то происходит остановка.
В принципе, вычисления в функциональной парадигме повторяют шаги редукции, но дополнительно содержат вычисления встроенных функций.