2014-02-02
2014-02-02 898
898Для текстовых ключевых полей обычно применяют подобные подходы, основанные на использовании операции сложения по модулю значений кодов первых нескольких символов ключа.
Основной проблемой хеширования с прямой адресацией записей является возможность появления одинаковых значений хеш-сверток при разных значениях полей (так называемые синонимы).
Такие ситуации называются hash collision-коллизиями, так как требуют определенного порядка, правил их разрешения.
Для разрешения коллизий применяются два подхода.
Первый подход основывается на использовании технологии цепных списков. Этот подход состоит в присоединении к конфликтующим записям, специальных дополнительных указателей, по которым размещаются новые записи. Как правило, для таких записей отводится специально выделенный участок памяти, называемый областью переполнения.
В алгоритм доступа добавляются операции перехода по цепному списку для нахождения искомой записи.
При большом количестве переполнений, однако, теряется главное достоинство хеширования - доступ к записи за одно обращение к памяти.
Второй подход разрешения коллизий основывается на использовании дополнительного преобразования ключей по схеме:
n i (доп.) = h (Кл i) + g (Кл i)= n i (о)+ g (Кл i),
где n i (о) – исходное конфликтующее значение адреса записи;
g (Кл i) - дополнительное преобразование ключа;
n i (доп.) – дополнительное значение адреса.
Может встретиться ситуация, когда и такое дополнительное преобразование вновь приводит к коллизии, т.е. полученное значение n i (доп.) также оказывается занятым.
Чтобы преодолеть такую ситуацию дополнительное преобразование g (Кл i) организуют на основе рекуррентной процедуры по следующей схеме:
n i(k)= n i(k-1)+ f (k),
где f (k) – некоторая функция над номером итерации (пробы).
В зависимости от вида функции f(k) такие подходы называют линейными или квадратичными пробами.
Основным недостатком второго подхода к разрешению коллизий является во многих случаях существенно больший объем вычислений, а также появление для линейных проб эффектов группирования номеров (адресов) текстовых ключевых полей, т.е. неравномерность номеров, если значения ключей отличаются друг от друга всего несколькими символами.
Несмотря на это коллизии (одинаковые значения хеш-сверток ключей) при использовании страничной организации структуры файлов баз данных во внешней памяти получили свое положительное и логичное разрешение и применение.
Значением хеш - свертки ключа в этом случае является номер страницы, куда помещается или где находится соответствующая запись (см. рис. 2.21).
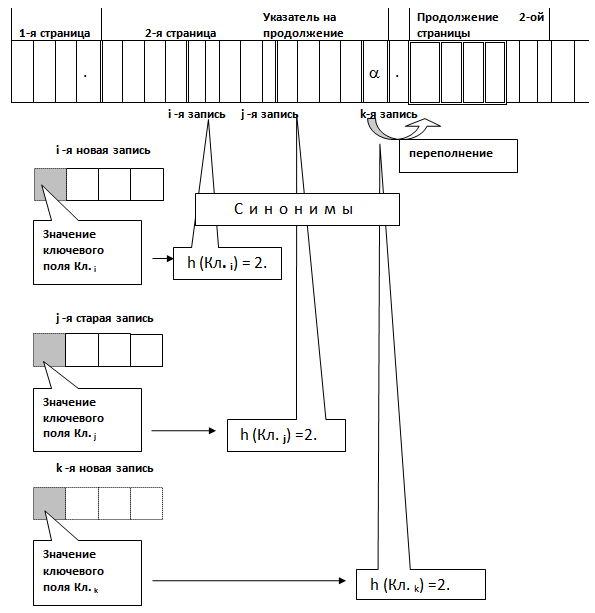
Рис. 2.21. Принцип хеширования записей по страницам файла данных.
Для доступа к нужной записи сначала производится хеш - свертка значения его ключевого поля и тем самым определяется номер страницы файла базы данных, содержащей нужную запись. Страница файла данных из дисковой памяти пересылается в оперативную память, где путем последовательного перебора отыскивается требуемая запись. Таким образом, при отсутствии переполнений доступ к записям происходит за одно страничное считывание данных из внешней памяти.
С учетом того, что количество записей помещающихся в одной странице файла данных, в большинстве случаев достаточно велико, случаи переполнения на практике встречаются не так часто. Вместе с тем, при большом количестве записей в таблицах файла данных, количество переполнений может существенно возрасти и так же, как и в классическом подходе, теряется главное достоинство хеширования – доступ к записям за одну пересылку страницы в оперативную память.
Для смягчения подобных ситуаций могут применяться комбинации хеширования и структуры Б-деревьев для размещения записей по страницам в случаях переполнения.
Внутренняя схема базы данных обычно скрыта от пользователей ИС, за исключением возможности установления и использования индексации полей. Вместе с тем, особенности физической структуры файлов данных и индексных массивов, принципы организации и использования дискового пространства и внутренней памяти, реализуемые конкретной СУБД, должны учитываться проектировщиками банков данных. Эти «прозрачные» (невидимые) для пользователей - абонентов особенности СУБД критично влияют на эффективность обработки данных в информационной системе.