 2014-02-17
2014-02-17 441
441Два последних критерия прокомментирует несколько позже.
Теперь перейдем к формальным определениям [17].
В традиционной прикладной математике множество понимается как совокупность элементов, обладающих некоторым общим свойством.
 Понятие нечеткого множества – это вариант математической формализации нечеткой информации. В основе этого понятия лежит представление о том, что составляющие данное множество элементы, обладающие общим свойством, могут обладать этим свойством в различной степени и, следовательно, принадлежать данному множеству с разной степенью. Пусть
Понятие нечеткого множества – это вариант математической формализации нечеткой информации. В основе этого понятия лежит представление о том, что составляющие данное множество элементы, обладающие общим свойством, могут обладать этим свойством в различной степени и, следовательно, принадлежать данному множеству с разной степенью. Пусть 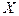 - обычное множество элементов.
- обычное множество элементов.
Определение П3.1. Нечетким множеством  в называется совокупность пар вида
в называется совокупность пар вида  , где
, где 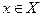 , а
, а 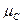 - функция, заданная на множестве и принимающая значения из интервала [0,1], т.е. :
- функция, заданная на множестве и принимающая значения из интервала [0,1], т.е. :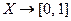 .
.
Функция называется функцией принадлежности нечеткого множества . Значение этой функции для конкретного 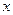 называется степенью принадлежности этого элемента нечеткому множеству .
называется степенью принадлежности этого элемента нечеткому множеству .
Обычно функция назначается экспертом. То, что любое нечеткое множество всегда является подмножеством некоторого обычного множества , послужило причиной тому, что в англоязычной литературе нечеткое множество зачастую называют нечетким подмножеством. Тем не менее, ниже будет использоваться термин «нечеткое множество». Если 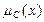 =1 для любого , то - обычное множество, совпадающее с .
=1 для любого , то - обычное множество, совпадающее с .
Рассмотрим примеры нечетких множеств.
Пример. Рассмотрим обычное конечное множество :
={a, b, c, d, e, f}.
Зададим на нем нечеткое множество:
={(a | 0), (b | 1), (c | 0.5), (d | 0), (e | 0.5), (f | 0)}.
Пример. Пусть N – множество натуральных чисел. Определим нечеткое множество «небольших» натуральных чисел:
={(0 | 1), (1 | 0.8), (2 | 0.6), (3 | 0.4), …}.
Иногда усматривается сходство между функцией принадлежности и вероятностью. Это сходство в значительной степени внешнее и ограничивается общностью области значений. Действительно, невозможно трактовать как вероятность степень принадлежности, например, конкретного человека с ростом 180 см к группе высоких людей, т.к. факт принадлежности не является случайным событием. Как следствие, нет необходимости в условии нормировки для значений функции принадлежности (в теории вероятностей для событий, образующих полную группу, сумма вероятностей должна быть равна единице).
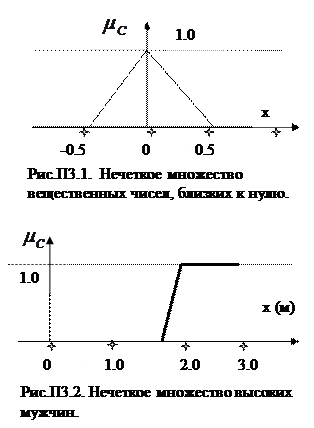
Нечеткое множество может быть описано графически в виде графика функции принадлежности. На рис.П3.1 приведено нечеткое множество вещественных чисел, близких к нулю, а на рис.П3.2 нечеткое множество высоких мужчин.
Вид функции принадлежности отражает мнение эксперта, ее назначающего, и, конечно же, контекст, в котором она используется. Так, например, в обыденной жизни мужчина ростом 1.8 м будет признан высоким, а среди баскетболистов будет числиться «малышом».
Существует свыше десятка типовых форм кривых для задания функций принадлежности. Наибольшее распространение получили: треугольная, трапецеидальная и гауссова функции принадлежности.
В теории нечетких множеств вводятся аналоги традиционных теоретико-множественных операций включения, объединения и пересечения.
Определение 2. Пусть 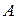 и
и 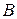 - нечеткие множества в
- нечеткие множества в 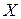 , а
, а 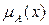 и
и 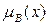 - их функции принадлежности соответственно, то говорят, что
- их функции принадлежности соответственно, то говорят, что 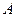 включает в себя
включает в себя 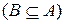 , если для любого
, если для любого 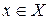 выполняется неравенство
выполняется неравенство 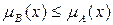 .
.
Определение 3. Объединением нечетких множеств и в называется нечеткое множество 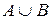 с функцией принадлежности вида
с функцией принадлежности вида
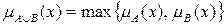 , .
, .
Определение 4. Пересечением нечетких множеств и в называется нечеткое множество 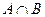 с функцией принадлежности вида
с функцией принадлежности вида
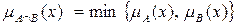 , .
, .
 С понятием «нечеткое множество» тесно связано понятие «лингвистическая переменная», т.е. переменная, принимающая «лингвистические» значения (значение, выраженное на естественном языке). Эти значения называются термами. Человек в своих рассуждениях очень часто использует лингвистические переменные, например, «рост – малый» или «рост – высокий». В этих выражениях лингвистическая переменная «рост» принимает лингвистические значения «малый» и «высокий». Однако сказанным не исчерпывается понятие «лингвистической переменной». Дополнительно с каждым ее лингвистическим значением связывается нечеткое множество, степень принадлежности к которому задается на некотором базовом множестве V={v).
С понятием «нечеткое множество» тесно связано понятие «лингвистическая переменная», т.е. переменная, принимающая «лингвистические» значения (значение, выраженное на естественном языке). Эти значения называются термами. Человек в своих рассуждениях очень часто использует лингвистические переменные, например, «рост – малый» или «рост – высокий». В этих выражениях лингвистическая переменная «рост» принимает лингвистические значения «малый» и «высокий». Однако сказанным не исчерпывается понятие «лингвистической переменной». Дополнительно с каждым ее лингвистическим значением связывается нечеткое множество, степень принадлежности к которому задается на некотором базовом множестве V={v).
На рис.П3.3 приведено описание лингвистической переменной «рост» с тремя термами – «низкий», «средний» и «высокий» – базовым множеством будет множество численных значений роста.
Одним из языков описания алгоритмов, в том числе и алгоритмов управления, являются продукционные правила, которое имеет вид:
n Продукционное правило при точной информации
Если «условие» То «заключение».
Если используемая в правиле информация, а также само правило неточны (ненадежны), то при описании могут быть использованы коэффициенты уверенности для характеризации условия (КУу), заключения (КУз) и правила в целом. Тогда правило принимает вид:
n Продукционное правило при неточной информации
ПР. (КУпр):Если «условие» (КУу):То «заключение» (КУз)
При этом коэффициент уверенности для заключения определяется как произведение
КУз= КУпр* КУу.
Если условие и заключения правила сформулированы на языке событий, то в качестве коэффициентов уверенности могут быть использованы субъективно назначаемые вероятности.
В рамках нечеткого подхода в управлении продукционные правила также нашли применение в виде так называемых нечетких продукционных правил. В частности в модели Такаги-Сугено они используются для задания соответствия между нечеткими интервалами с одной стороны и частными наблюдателями и контроллерами с другой стороны.
Определение. Продукционное правило является нечетким, если в условии или заключении используются лингвистические переменные.
При этом оперирование правилами осуществляется в соответствии с процедурой нечеткого логического вывода, которая далее и будет  рассмотрена на примере задачи управления кондиционером. В литературе описан целый ряд процедур нечеткого логического выводы, которые характеризуются общностью структуры, но различаются по ряду параметров.
рассмотрена на примере задачи управления кондиционером. В литературе описан целый ряд процедур нечеткого логического выводы, которые характеризуются общностью структуры, но различаются по ряду параметров.
Процедура нечеткого логического вывода всегда содержит 5 этапов:
n Определение для всех правил и для всех условий степеней принадлежности значений входных переменных нечетким множествам, указанным в условиях (фазификация).
n Определение степени истинности для посылки в целом для каждого правила (агрегирование).
n Модификация нечетких множеств, указанных в заключении правил, в соответствии со значениями степеней принадлежности, полученными на первом шаге.
n Объединение (аккумулирование) модифицированных множеств.
n Скаляризация результата объединения – переход от нечетких множеств к скалярным значениям (дефазификация).
Выполним эти этапы по отношению к рассматриваемому примеру, используя процедуру Мамдани. Предварительно определим нечеткие множества для термов входных переменных правил. Для значений лингвистической переменной «температура воздуха в комнате» - высокая, средняя, низкая - зададим соответствующие функции принадлежности 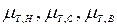 на базовом множестве T значений температур (рис.П3.4). Аналогично для значений лингвистической переменной «скорость вращения вентилятора» – высокая, средняя, низкая – зададим функции принадлежности
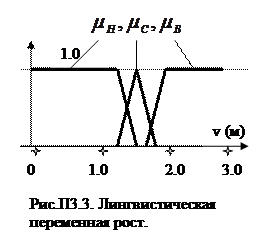
на базовом множестве T значений температур (рис.П3.4). Аналогично для значений лингвистической переменной «скорость вращения вентилятора» – высокая, средняя, низкая – зададим функции принадлежности 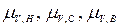 на базовом множестве V значений скоростей (рис.П3.5).
на базовом множестве V значений скоростей (рис.П3.5).
Рассмотрим теперь, как определяется скорость вращение вентилятора в зависимости от температуры воздуха в комнате. Пусть эта температура равна 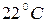 . Сначала на первом этапе определим степени истинности условий правил вывода при подстановке в них текущего значения температуры. Для этого надо определить степень принадлежности t = к каждому из указанных в условиях нечетких множеств. Они соответственно равны:
. Сначала на первом этапе определим степени истинности условий правил вывода при подстановке в них текущего значения температуры. Для этого надо определить степень принадлежности t = к каждому из указанных в условиях нечетких множеств. Они соответственно равны: 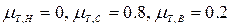 .
.
Второй этап процедуры логического вывода применительно к рассматриваемому примеру не имеет смысла, т.к. все три правила имеют в посылке по одному условию.
На третьем этапе полученные значения степеней истинности условий используются для модификации нечетких множеств, связанных с заключениями правил. Эта модификация осуществляется одним из двух методов – вычислением минимума или произведения. Первый ограничивает функцию принадлежности для нечеткого множества заключения значением истинности условия. Во втором методе значение истинности условия используется как коэффициент, на который умножается функция принадлежности заключения. Для каждого правила результат вычисляется отдельно. В процедуре Мамдани используется операция минимума. Результат операции представлен на рис. П3.6.

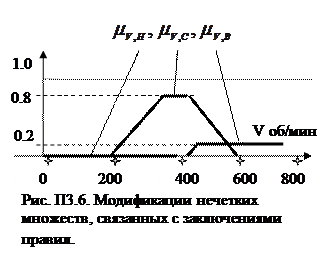 Далее на 4-м этапе необходимо обобщить результаты действий всех правил вывода, поскольку их заключения содержат одну и ту же лингвистическую переменную «скорость вращения вентилятора». Суперпозиция результатов правил может быть осуществлена двумя методами – взятия максимума и суммирования. В процедуре Мамдани используется операция максимума (рис.П3.7).
Далее на 4-м этапе необходимо обобщить результаты действий всех правил вывода, поскольку их заключения содержат одну и ту же лингвистическую переменную «скорость вращения вентилятора». Суперпозиция результатов правил может быть осуществлена двумя методами – взятия максимума и суммирования. В процедуре Мамдани используется операция максимума (рис.П3.7).
Конечный этап обработки – переход от нечетких значений к конкретным скалярным. Этот процесс часто называют дефазификацией. Для его реализации используются также два основных метода – вычисление «центра тяжести» фигуры и взятие максимума. В процедуре Мамдани используется метод центра тяжести. Центр тяжести фигуры находится в точке v = 550 об/мин. Это и будет значением скорости вентилятора, получаемое в результате логического вывода.
Литература
1. Андреев Ю.Н. Управление конечномерными линейными объектами. – М.: Наука, 1976. – 424 с.
2. Безмен Г.В., Колесов Н.В., Толмачева М.В. и др. Диагностирование систем реального времени // Приборы и системы. Управление, контроль, диагностика – 2008 – № 6. – С. 35 – 39.
3. Безмен Г.В., Колесов Н.В. Функциональное диагностирование линейных динамических систем с использованием нечеткого анализа // Информационно-управляющие системы – 2009 – № 6. – С.67 – 73.
4. Безмен Г.В., Колесов Н.В. Функциональное диагностирование динамических систем с использованием нечетких правил анализа и принятия решений об отказе // Известия РАН. Теория и системы управления – 2011 - № 3. – С. 3 – 12.
5. Бессекерский В.А., Попов Е.П. Теория систем автоматического управления. М.:Наука, 1975.
6. Бритов Г.С., Игнатьев М.Б., Мироновский Л.А., Смирнов Ю.М. Управление вычислительными процессами. – ЛГУ, 1973. 298 с.
7. Вентцель Е.С. Исследование операций. – М.: Советское радио, 1972.- 552 с.
8. Гильбо Е.П., Челпанов И.Б. Обработка сигналов на основе упорядоченного выбора. — М. Советское радио, 1975. 252 с.
9. Данилов В.В., Жирабок А.Н., Колесов Н.В., Шумский А.Е. Модель функционального диагностирования линейных цифровых систем//Электронное моделирование.- 1985.- № 1.- С.61-66.
10. Дмитриев С.П., Колесов Н.В., Осипов А.В. Информационная надежность, контроль и диагностика навигационных систем. – СПб.: Изд-во ЦНИИ «Электроприбор», 2003. 206 с.
11. Жирабок А.Н. Алгебраическая теория функционального диагностирования нелинейных и линейных динамических систем//Изв. АН РФ. Теория и системы управления.- 2001.- № 2.- С.29-38.
12. Жирабок А.Н., Шумский А.Е. Методы и алгоритмы функционального диагностирования сложных технических систем. Владивосток: Изд-во ДВГТУ, 2007. 134с.
13. Заде Л. Понятие лингвистической переменной и его применение для принятия приближенных решений.- М.: Мир, 1976. -165с.
14. Игнатьев М.Б., Мироновсий Л.А. и др. Контроль и диагностика робототехнических систем. Л.: Изд-во ЛИАП, 1985. 160 с.
15. Козлов Б.А., Ушаков И.А. Справочник по расчету надежности аппаратуры радиоэлектроники и автоматики. – М.: Советское радио, 1975.- 472 с.
16. Колесов Н.В. Построение проверяющего теста для линейного конечного автомата // Автоматика и телемеханика, 1982, № 2, с. 61 – 66.
17. Колесов Н.В. Диагностирование линейных дискретных нестационарных систем // Автоматика и телемеханика, 1988, № 7, с. 157 – 163.
18. Колесов Н.В. Многоуровневое проектирование средств тестового и функционального диагностирования специализированных вычислительных комплексов. Л.: Изд-во ЦНИИ «Румб», 1992. 70 с.
19. Колесов Н.В. Нестационарная диагностическая модель системы обмена распределенного управляющего комплекса // Автоматика и телемеханика, 1990, № 4, с. 144 – 154.
20. Кофман А. Введение в теорию нечетких множеств. - М.: Радио и связь, 1982. - 432с.
21. Мироновский Л.А. Функциональное диагностирование динамических систем. М.-СПб.: Изд-во МГУ-ГРИФ, 1998. 256 с.
22. Основы технической диагностики. – Под ред. Пархоменко П.П., М.:Энергия, 1976. – 464 с.
23. Пархоменко П.П., Согомонян Е.С. Основы технической диагностики. – М.: Энергия, 1981.
24. Шаршунов С.Г. Построение тестов микропроцессоров. Ч.1. // Автоматика и телемеханика – 1985, № 11, с. 145 – 155.
25. Шумский А.Е. Поиск дефектов в нелинейных системах методом функционального диагностирования на основе алгебраических инвариантов // Электронное моделирование.- 1992.- № 1.- С.70-76.
26. Clark, R.N. A simplified instrument detection scheme // IEEE Trans. Aerospace Electron. Syst., 1978, Vol. 14, pp. 558-563 and 456-465.
27. Elghatwary M. G., Ding S. X., Gao Z. Robust fault detection for uncertain Takagi-Sugeno fuzzy systems with parametric uncertainty and process disturbances. // Proceedings of 6th IFAC Symposium on Fault Detection, Supervision and Safety of Technical Processes, Aug. 29 – Sep. 1, 2006, Beijing, China, pp. 271-276.
28. Frank, P.M. Advanced fault detection and isolation schemes using nonlinear and robust observers. // 10th IFAC, 1987, Congress, München, Vol. 3, pp. 63-68.
29. Frank P.M. Fault diagnosis in dynamic systems using analytical and knowledge-based redundancy – A survey and some new results // Automatica. 1990. V. 26. P.459-474.
30. Isermann R. Model-based fault detection and diagnosis – status and applications // 16th IFAC Symposium on automatic control in aerospace, 2004, St.Petersburg, Russia, pp. 150-157.
31. Koscielny J.M. Application of fuzzy logic for fault isolation in a three-tank system // Proc. 14th World Congress IFAC. Beijing. 1999. V. 7, pp. 73-78.
32. Koscielny J.M., Syfert M. fuzzy diagnostic reasoning that takes into account the uncertainty of the relation between faults and symptoms // Int. J. Appl. Math. Comput. Sci., 2006, Vol. 16, № 1, 27–35.
33. Mendouca L. at al. Fault isolation using fuzzy model-based observers. – 6-th IFAC Symposium on Fault Detection. 2006. Beijing. P.R. China. P. 142-150.
Patton R J, Frank P M, Clark R N. Issues in fault diagnosis for dynamic systems, Springer-Verlag, London, April 2000
Временные диаграммы, поясняющие работу микросхемы, приведены на рис. 3. Из временных диаграмм видно, что моменты появления выходных управляющих импульсов микросхемы, а также их длительность (диаграммы 12 и 13) определяются состоянием выхода логического элемента DD1 (диаграмма 5). Остальная "логика" выполняет лишь вспомогательную функцию разделения выходных импульсов DD1 на два канала. При этом длительность выходных импульсов микросхемы определяется длительностью открытого состояния ее выходных транзисторов VT1, VT2. Так как оба эти транзистора имеют открытые коллекторы и эмиттеры, то возможно двоякое их подключение.
При включении по схеме с общим эмиттером выходные импульсы снимаются с внешних коллекторных нагрузок транзисторов (с выводов 8 и 11 микросхемы), а сами импульсы направлены выбросами вниз от положительного уровня (передние фронты импульсов отрицательны). Эмиттеры транзисторов (выводы 9 и 10 микросхемы) в этом случае, как правило, заземляются. При включении по схеме с общим коллектором внешние нагрузки подключаются к эмиттерам транзисторов и выходные импульсы, направленные в этом случае выбросами вверх (передние фронты импульсов положительны), снимаются с эмиттеров транзисторов VT1, VT2. Коллекторы этих транзисторов подключаются к шине питания управляющей микросхемы (Upom).
Выходные импульсы остальных функциональных узлов, входящих в состав цифровой части микросхемы TL494, направлены выбросами вверх, независимо от схемы включения микросхемы.
Триггер DD2 является двухтактным динамическим D-триггером. Принцип его работы заключается в следующем. По переднему (положительному) фронту выходного импульса элемента DD1 состояние входа D триггера DD2 записывается во внутренний регистр. Физически это означает, что переключается первый из двух триггеров, входящих в состав DD2. Когда импульс на выходе элемента DD1 заканчивается, то по заднему (отрицательному) фронту этого импульса переключается второй триггер в составе DD2, и состояние выходов DD2 меняется (на выходе Q появляется информация, считанная со входа D). Это исключает возможность появления отпирающего импульса на базе каждого из транзисторов VT1, VT2 дважды в течение одного периода.
Действительно, пока уровень импульса на входе С триггера DD2 не изменился, состояние его выходов не изменится. Поэтому импульс передается на выход микросхемы по одному из каналов, например верхнему (DD3, DD5, VT1). Когда импульс на входе С заканчивается, триггер DD2 переключается, запирает верхний и отпирает нижний канал (DD4, DD6, VT2). Поэтому следующий импульс, поступающий на вход С и входы DD5, DD6 будет передаваться на выход микросхемы по нижнему каналу. Таким образом каждый из выходных импульсов элемента DD1 своим отрицательным фронтом переключает триггер DD2 и этим меняет канал прохождения следующего импульса. Поэтому в справочном материале на управляющую микросхему указывается, что архитектура микросхемы обеспечивает подавление двойного импульса, т.е. исключает появление двух отпирающих импульсов на базе одного и того же транзистора за период.








