2014-02-24
2014-02-24 1368
1368Для демонстрации связей, существующих между отдельными компонентами системы, используются различные графические схемы. Некоторые из них, такие как граф-диаграммы, отображают главным образом прохождение потоков данных между процессами. Другие, в частности, функциональные схемы, выделяют моменты, связанные с хранением данных и используемыми для этого носителями. Существуют также схемы, в которых основное внимание уделяется взаимодействию процессов.
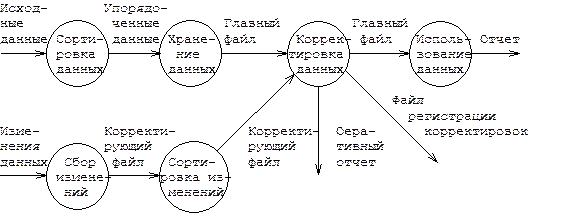
Рис. 3.1. Граф-диаграмма системы сопровождения данных.
Граф-диаграммы. Иногда называемые графами потоков данных. Каждый кружок на такой диаграмме отображает некоторое преобразование данных. Потоки данных отмечаются стрелками. Этот тип схем можно использовать как на системном уровне для описания внешних входов и выходов программ, так и при проектировании самих программ для описания перемещений данных между отдельными модулями. На рисунке 3.1 представлен пример граф-диаграммы системы сопровождения данных.
Диаграммы Варнье-Орра. На диаграмме Варнье-Орра в иерархической структуре системы выделяются ее элементарные составные части, которые снабжаются контурными изображениями носителей информации. Сначала система разделяется на ряд отдельных процессов. На следующем уровне иерархии указываются потоки данных для каждого процесса. Затем перечисляются наборы данных и наконец - соответствующие носители информации. Последние обозначаются с помощью стандартных условных изображений, применяемых на функциональных схемах. Направления потоков данных отмечаются стрелками, проведенными между наборами данных и физическими носителями информации. Наборы данных, используемые одновременно в нескольких процессах, связаны между собой и имеют одинаковые имена. На рисунке 3.4 представлена диаграмма Варнье-Орра для системы сопровождения данных.
Функциональные схемы. Функциональная схема системы состоит из одного или нескольких прямоугольных блоков, содержащих названия программ. Эти блоки соединяются входящими в них стрелками с источниками и исходящими из них стрелками - с приемниками данных. Источники и приемники изображаются в виде блоков, очертания которых напоминают определенные физические носители информации (некоторые блоки представлены на рис. 3.2). В каждом блоке записано имя программы или набора данных, иногда оно дополняется информацией, раскрывающей назначение блока. Основное внимание в схемах этого типа уделяется описанию потоков данных в системе и используемых наборов данных. На рисунке 3.3. изображена функциональная схема фрагмента системы корректировки главного файлов.
Все рассмотренные выше типы схем рассчитаны на описание потоков данных в программно-управляемых системах, в которых только программы могут инициализировать или прекращать генерацию потоков данных. Однако в ПС, для которых характерна работа в режиме реального времени, некоторые из системных функций управляются не столько программами, сколько самими данными, т.е. в таких системах данные приводят в действие или заставляют прекращаться определенные процессы. В одно и то же время в активном состоянии могут находиться несколько процессов.
ПЕРТ-диаграммы. На функциональных схемах нельзя показать порядок взаимодействия программ. Для этого удобнее использовать ПЕРТ-диаграммы. На ПЕРТ-диаграмме не указываются наборы или потоки данных. Она отображает связи по управлению, существующие в системе, а также координацию выполняемых действий. Каждая стрелка соответствует определенной операции, а каждый кружок - событию, под которым понимается завершение одной или несколько операций и переход к другим. По содержанию эти символы прямо противоположны аналогичным обозначениям на граф-диаграммах (см. рис. 3.5).
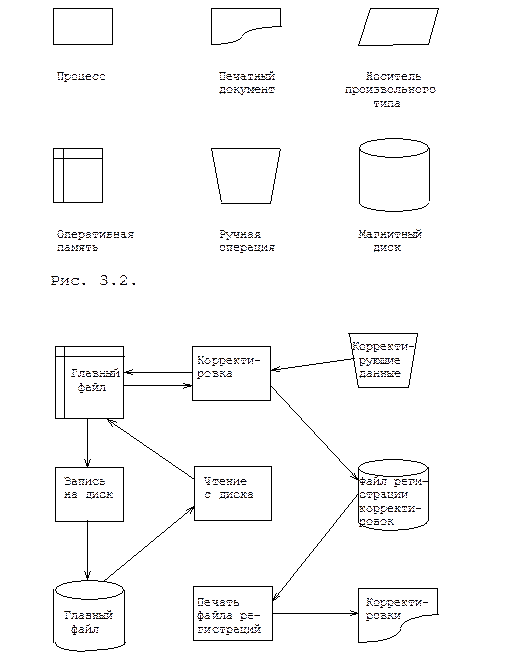
Рис. 3.3. Функциональная схема корректировки главного файла

Рис. 3.4. Диаграмма Варнье-Орра для системы
сопрождения данных
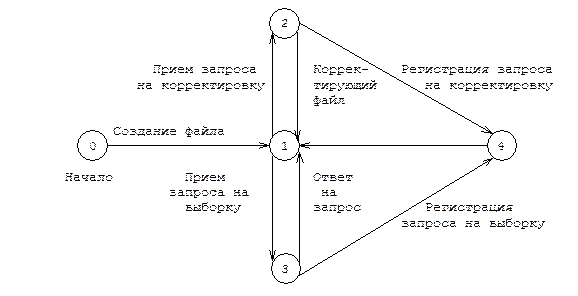
Рис. 3.5. ПЕРТ-диаграмма интерактивной системы сопровождения файлов.
Сети Петри. Диаграммы, называемые сетями Петри, используются в качестве моделей, которые описывают движение потоков данных в сетях, допускающих частичное или полное переключение потоков из одних магистралей в другие. Такая ситуация характерна для интерактивной системы корректировки - выборки данных, в которой данные могут проходить через программы, одновременная работа которых не допускается. Сети Петри позволяют исследовать как потоки данных, так и динамику передач управления в системе. Для этого строится несколько схем, отражающих последовательные состояния сети, из которых видно, как происходит перемещение точек управления вдоль потоков данных. Следующие друг за другом изображения сети Петри отличаются лишь расположением указанных точек (см. пример на рис. 3.6).
Схемы HIPO. Использование схем HIPO характерно для той стадии проектирования, когда системные аналитики уже могут приступать к разработке программ и данных. Эти схемы, определяя основные функции каждой программы и перечень основных элементов данных, не конкретизируют способы организации данных, иерархическую структуру подпрограмм и выбор алгоритмов обработки. На этапе разработки программ схемы HIPO могут применяться в качестве средства описания функций, реализуемых программой, и циркулирующих внутри нее потоков данных. На рисунке 3.7 представлена схема HIPO для программы корректировки файла.

Рис. 3.6. Сеть Петри для интерактивной системы сопровождения файлов
Схемы передач управления. Для изображения передач управления в программном модуле обычно используются структурные схемы программ. Структурное программирование и его влияние на применение основных управляющих конструкций способствовали тому, что стандартные символы схем были дополнены новыми символами и были разработаны новые типы схем. В частности, схемы Насси-Шнейдермана представляют для программиста средство описания вложенных управляющих структур.
На рисунке 3.8 показаны стандартные и нестандартные символы для изображения структурных схем. Их можно использовать для представления организации программы так же, как и для передач управления. Прокомментируем представленные символы.
Блок ограничения/прерывания. Этот символ предназначен для обозначения входов в структурную схему, а также для указания всех выходов из нее. Каждая структурная схема должна начинаться и заканчиваться символом ограничения.
Блок решения. Этот символ используется для обозначения переходов управления по условию. Для каждого блока решения должны быть указаны: вопрос, решение, условия или сравнение, которые он определяет. Стрелки, выходящие из этого блока, должны быть помечены соответствующими ответами так, чтобы были учтены все возможные ответы.
Блок обработки. Этот символ применяется для обозначения одного или нескольких операторов, изменяющих значение, форму представления или размещения информации. Для улучшения наглядности схемы несколько отдельных блоков обработки могут быть объединены в один блок.
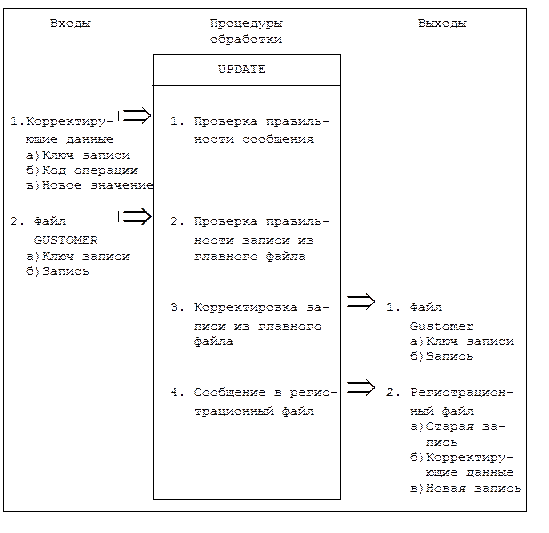
Рис. 3.7. Схема HIPO для программы корректиров-
ки файла GUSTOMER.
Блок вызова модуля. Этот модуль используется для обращений к модулям или подпрограммам. Вертикальные линии обозначают обращение к внешним модулям обработки, горизонтальная линия - данный блок представлен в документации отдельной структурной схемой.
Блок ввода/вывода. Этот символ используется для обозначения операций ввода/вывода информации. Отдельным логическим устройствам или отдельным функциям обмена должны соответствовать отдельные блоки. В каждом блоке указывается тип устройства или файла, тип информации, участвующий в обмене, а также вид операции обмена.

Соединители. Эти символы используются в том случае, если структурная схема должна быть разделена на части или не умещается на одном листе. Применение соединителей не должно нарушать структурности при изображении схем.
Блок комментария. Этот символ позволяет включать в структурные схемы пояснения к функциональным блокам. Частое использование комментариев нежелательно: оно усложняет структурную схему.
Структурные схемы можно применять на любом уровне абстракции. Основная тенденция в использовании структурных схем в настоящее время - не указание последовательности операций, а группирование символов, выражающих базовые конструкции: следование, выбор, повторение. На рис. 3.9 показаны схемы этих управляющих конструкций.
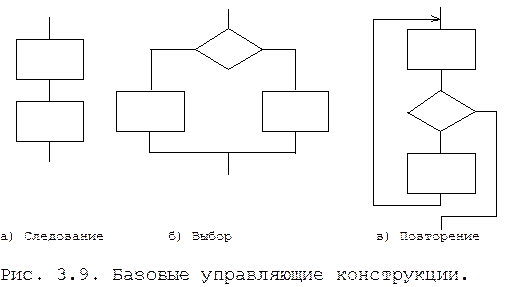
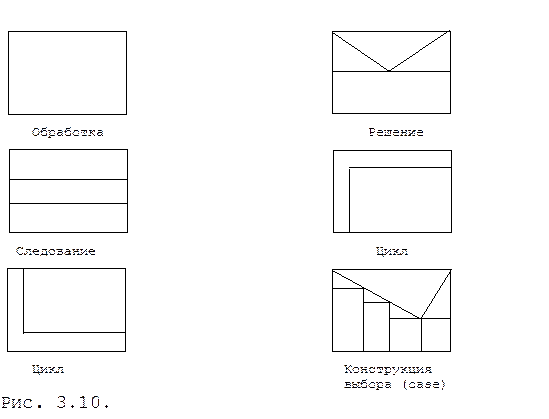
Схемы Насси-Шнейдермана. Способ изображения модуля с помощью схем Насси-Шнейдермана представляет собой попытку использования требований структурного программирования (см. ниже) в структурных схемах модулей. Он позволяет изображать схему передач управления не с помощью явного указания линий переходов по управлению, а с помощью представления вложенности структур. Некоторые из используемых в этом способе символов соответствуют символам структурных схем. Эти символы показаны на рисунке 3.10. Каждый блок имеет форму прямоугольника и может быть вписан в любой внутренний прямоугольник любого другого блока. Блоки помечаются тем же способом, что и блоки структурных схем, т.е. с использованием предложений на естественном языке или с помощью математических нотаций. Если использовать символы схем Насси-Шнейдермана одновременно с дополнительными символами структурных схем для изображения множественных выходов и обработки прерываний, то представление рассматриваемого модуля может быть упрощенно.
Синтаксические диаграммы. Так как грамматические правила просты и их немного, то для описания грамматических правил используют синтаксические диаграммы. Идея синтаксической диаграммы состоит в том, что надо войти в нее слева и пройти по ней до правого края. Синтаксические диаграммы, как правило, используются для описания синтаксиса операторов языков программирования при их представлении. На рис. 3.11 представлена синтаксическая диаграмма для оператора - цикла с заданными границами PASCAL ("FOR").

Таблицы решений. Метод проектирования с помощью таблиц решений заключается в перечислении вариантов управляющих решений, принимаемых на основе анализа данных. Поскольку в этих таблицах перечисляются все возможные сочетания данных, существует гарантия того, что учитываются все необходимые решения. Таблицы решений обычно состоят из двух частей. Верхняя часть используется для определения условий, а нижняя - для действий. Левая часть таблицы содержит описание условий и действий, а правая часть - соответствующую ситуацию. Рисунок 3.12 демонстрирует возможность использования таблицы решений для формализации задачи светофорного регулирования.
 |
Условия Правила
 |
1: КРАСНЫЙ 1 1 0 0 иначе
2: ЖЕЛТЫЙ 0 1 1 0
3: ЗЕЛЕНЫЙ 0 0 1 1
 |
Действия
1: СТОП X X
2: ПРОПУСТИ С X
ПРАВА И
ДВИГАЙСЯ
3: ДВИГАЙСЯ X
ВПЕРЕД
4: ПОДГОТОВКА X
К ДВИЖЕНИЮ
Рис. 3.12. Таблица решений для формализации
задачи светового регулирования.
Вопросы, на которые следует ответить в структуре управления, перечислены в столбце условий. Действия, выполняемые в зависимости от ответов, указаны в столбце действий. Затем рассматриваются все возможные комбинации ответов "да" и "нет". Если какая-либо комбинация невозможна, она может быть опущена. Крестами отмечены действия, необходимые для каждого набора условий. Порядок расположения условий не должен влиять на порядок их проверки. Однако действия могут быть записаны в порядке их выполнения.
Таблицы решений могут быть использованы для проектирования структуры управления модулями в иерархической схеме. Их также можно преобразовать в двоичные деревья решений и принять как основу для проектирования любого модуля, использующего решения.
3.3. СТРУКТУРНЫЕ ПРЕОБРАЗОВАНИЯ СХЕМ ПЕРЕДАЧ УПРАВЛЕНИЯ.
Простые преобразования. Простые преобразования схем передач управления связаны со сверсткой и разверткой: а - линейных участков; б - условий; в, г -циклов (рис. 3.13).
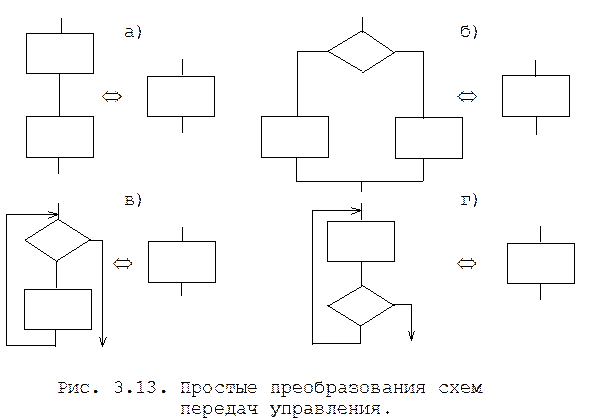
Дублирование элементов. Данное преобразование позволяет привести схему передачи управления к структурированному виду введением в нее по определенным правилам дополнительных элементов, эквивалентных уже имеющимся. Пусть имеется структура, представленная на рисунке 3.14.

В целом эта схема имеет один вход и один выход. Однако стремление использовать блоки 7,9,10 и 12 в ветвях, начинающихся в блоках 4 и 5, привело к запутанным связям по управлению. Дублируя соответствующим образом блоки 7,9,10,11 можно привести исходную схему к структурированному виду. При дублировании, строя очередной путь после разветвления, каждый раз вводят необходимые блоки, не обращая внимания на то, что они уже введены на альтернативных участках других путей. Каждый дублированный элемент, по существу, имеет собственное имя, однако в функциональном отношении эквивалентен исходному. На рис. 3.14,б изображена преобразованная исходная схема.
Введение переменной состояния. Второй подход преобразования управляющей структуры основывается на введении переменной состояния.
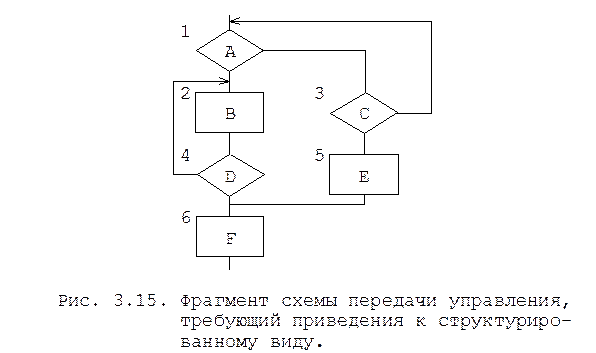
Процесс преобразования состоит из пяти шагов:
1. Каждому блоку схемы приписывается номер. Причем 0 - последний исполняемый элемент.
2. Вводится новая переменная, принимающая значение в диапазоне 0..n, где n - число блоков в схеме передачи управления.
3. Вводятся n операций присвоения значений введенной переменной состояния. С каждым блоком связывается одна (для логического блока по количеству выходов) операция, в которой значение переменной становится равным номеру очередного исполняемого блока.
4. Вводятся n операций анализа переменной состояния, причем, если значение переменной состояния равно m (m<n), то управление передается блоку с номером m.
5. Строится новая управляющая структура в виде цикла с вложенными в него операциями анализа пере-
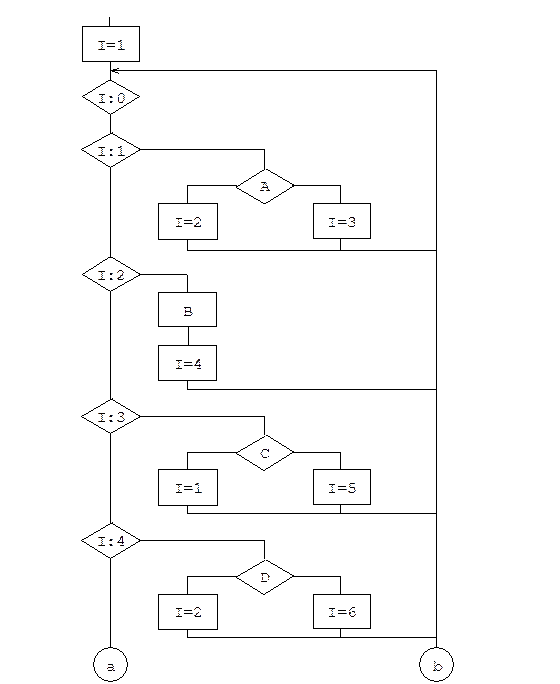
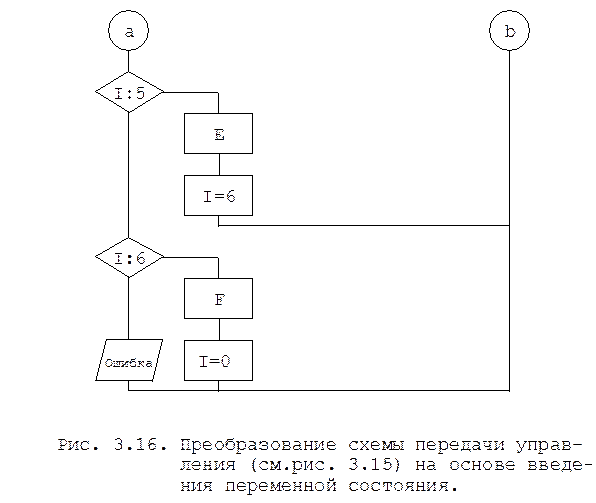
менной состояния и исполнения блоков исходной структуры с добавлением элементов присвоения значений переменной состояния.
Пример на рис. 3.16 иллюстрирует преобразование схемы передачи управления с циклами и метками к структурированному виду на основе введения переменной состояния.
5.1. НЕЗАВИСИМОСТЬ МОДУЛЕЙ.
Чтобы уменьшить сложность ПС, нужно разбить ее на множество небольших, в высокой степени независимых модулей. Довольно высокой степени независимости можно достичь с помощью двух методов оптимизации: усилением внутренних связей в каждом модуле и ослаблением взаимосвязи между модулями. Если рассматривать ПС как набор предложений, связанных между собой некоторыми отношениями (как по выполняемым функциям так и по обрабатываемым данным), то основное, что требуется, это догадаться, как распределить предложения по отдельным "ящикам" (модулям) так, чтобы предложения внутри каждого модуля были тесно связаны, а связь между любой парой предложений в разных модулях была минимальной.
Модульность. Понятие модульность носит универсальный характер и применяется при проектировании информационных систем, при проектировании вычислительной техники, при разработке программного обеспечения. Основной смысл разбиения системы на модули заключается в том, чтобы локализовать и изолировать влияние возмущающих воздействий или изменений. Существуют различные типы модульности в зависимости от того, какого рода возмущения или изменения рассматриваются.
5.2. ПРОЧНОСТЬ МОДУЛЕЙ.
Модульность, которая облегчает внесение изменений в систему, можно охарактеризовать как гибкость. Этот тип модульности имеет место в тех случаях, когда система спроектирована так, что изменение одного из требований приводит к необходимости корректировки лишь небольшого числа модулей (желательно только одного). Если модульная структура системы такова, что ее отдельные модули могут быть реализованы различными разработчиками практически независимо друг от друга, то имеет место конструктивная модульность. Модульность, при которой в системе локализуется влияние различных событий, происходящих в реальном масштабе времени, называется событийной модульностью. Если внесение изменений в аппаратуру не требует модификации программного обеспечения, то это свойство называется прозрачностью. И наконец, упомянем о функциональной модульности, обеспечивающей обозримость системы. В этом случае система разбивается на легко обозримые части с четко определенным набором функций. Необходимость в разбиении системы на модули по этому принципу может появляться даже тогда, когда другие критерии этого не требуют.
Степень модульности можно определить по двум критериям - прочности (связности) и сцеплению. Каждому из этих критериев соответствует некоторое разбиение на классы, позволяющее оценивать модульность системы количественно. Типы связности и сцепления, перечисленные ниже, приведены для того, чтобы дать представление о понятиях, ассоциируемых с критериями модульности.
Связность модулей. Связность модуля опpеделяется как меpа независимости его частей. Чем выше связность модуля, тем лучше pезультат пpоектиpования. Для обозначения связности используется также понятие силы связности модуля. Типы связности модулей приведены в таблице 5.1.
Название и оценки связности у разных авторов различаются, но незначительно.
Модуль с функциональной связностью не может быть разбит на два других модуля, имеющих связность того же типа. Модуль управления обработкой пакетов имеет функциональную связность. Модуль, который может быть разбит только на исток, преобразователь и сток, также имеет функциональную связность. Модуль, имеющий последовательную связность, может быть разбит на последовательные части, выполняющие независимые функции, но совместно реализующие единственную функцию. Если один и тот же модуль используется для оценки, а затем для обработки данных, то он имеет последовательную связность. Если модуль составлен из независимых модулей, разделяющих структуру данных, он имеет коммуникативную связность. Общая структура данных является основой его организации как единого модуля. Если модуль спроектирован так, чтобы упростить работу со сложной структурой данных, изолировать эту структуру, он имеет коммуникативную связность. Такой модуль предназначен для выполнения нескольких различных и независимо используемых функций. Модули высшего уровня иерархической структуры должны иметь функциональную или последовательную связность. Если модули имеют процедурную, временную, логическую или случайную связность, это свидетельствует о недостаточно продуманном их планировании. Процедурная связность обнаруживается в модуле, управляющие конструкции которого организованы так, как изображены на структурной схеме программы. Такая структура модуля может возникнуть при расчленении длинной программы на части в соответствии с передачами управления, но без определения какого-либо функционального базиса при выборе разделительных точек. Процедурная связность может появиться при группировании альтернативных частей программы.
Таблица 5.1.
 |
Связность Сила связности
 |
Функциональная 10 (сильная связность)
Последовательная 9
Коммуникативная 7
Процедурная 5
Временная 3
Логическая 1
По совпадению 0
Модуль, содержащий части функционально не связанные, но необходимые в один и тот же момент обработки, имеет временную связность или связность по классу. Связность такого типа имеет место в тех случаях, когда все множество требуемых в момент входа в программу функций выполняется независимым модулем активации. Если в модуле объединены операторы только по признаку их функционального подобия, а для его настройки применяется алгоритм переключения, такой модуль имеет логическую связность, поскольку его части ничем не связаны, а имеют лишь небольшое сходство между собой. Если операторы модуля объединяются произвольным образом, такой модуль имеет связность по совпадению.
5.3. СЦЕПЛЕНИЕ МОДУЛЕЙ.
Сцепление модулей представляет собой меру относительной независимости модулей, которая определяет их читабельность и сохранность. Независимые модули могут быть модифицированы без переделки каких-либо других модулей. Слабое сцепление более желательно, так как это означает высокий уровень их независимости. Модули являются полностью независимыми, если каждый из них не содержит о другом никакой информации. Чем больше информации о других модулях используется в них, тем менее они независимы и тем менее теснее сцеплены. Чем очевиднее взаимодействие двух связанных друг с другом модулей, тем проще определить необходимую корректировку одного модуля, зависящую от изменений, производимых в другом. Большая изоляция и непосредственное взаимодействие модулей приводит к трудностям в определении границ изменений одного модуля, которое устраняли бы неизбежные ошибки в другом. Ниже в таблице 5.2 приведены меры сцепления модулей.
Модули сцепления по данным, если они имеют общие единицы, которые передаются от одного к другому как параметры, представляющие собой простые элементы данных, то есть вызывающий модуль "знает" только имя вызываемого модуля, а также типы и значения некоторых его переменных. Изменения в структуре данных в одном из модулей не влияют на другой. Кроме того, модули с этим типом сцепления не имеют общих областей данных или неявных параметров. Меньшая степень сцепления возможна только в том случае, если модули не вызывают друг друга или не обрабатывают одну и ту же информацию.
Таблица 5.2.
 |
Сцепление Степень сцепления модулей
 |
Независимое 0 (слабое сцепление)
По данным 1
По образцу 3
По общей области 4
По управлению 5
По внешним ссылкам 7
По кодам 9 (сильное сцепление)
Модули сцеплены по образцу, если параметры содержат структуры данных. Недостатком такого сцепления является то, что оба модуля должны знать о внутренней структуре данных.
Модули сцеплены по общей области, если они разделяют одну и ту же глобальную структуру данных.
Модули имеют сцепление по управлению, если какой-либо из них управляет решениями внутри другого с помощью передачи флагов, переключателей или кодов, предназначенных для выполнения функций управления, то есть один из модулей знает о внутренних функциях другого.
Говорят, что модуль предсказуем, если его работа обусловлена только одними параметрами.
Модуль сцеплен по внешним ссылкам, если у него есть доступ к данным в другом модуле через внешнюю точку входа.
Модули имеют сцепление по кодам, если коды их команд перемежаются друг с другом.
Основы языка SQL
SQL (ˈɛsˈkjuˈɛl; англ. Structured Query Language — «язык структурированных запросов») — универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных. SQL основывается на исчислении кортежей. Язык манипулирования данными SQL включает следующие операторы:
1) Операторы определения данных (Data Definition Language, DDL)
- CREATE создает объект БД (саму базу, таблицу, представление, пользователя и т. д.)
- ALTER изменяет объект (добавление, удаление, изменение колонки таблицы)
Для добавления колонки в таблицу, используйте следующий синтаксис:
ALTER TABLE table_name ADD column_name datatypeДля удаления колонки в таблице:
ALTER TABLE table_name DROP COLUMN column_nameДля изменения типа данных колонки, используйте следующий синтаксис:
ALTER TABLE table_name ALTER COLUMN column_name datatype- DROP удаляет объект
2) Операторы манипуляции данными (Data Manipulation Language, DML)
- INSERT добавляет новые данные:
INSERT INTO <название таблицы> ([<Имя столбца>,... ]) VALUES (<Значение>,...)
- UPDATE изменяет существующие данные
top(x) — команда выполнится только х раз
<объект> — объект, над которым выполняется действие (таблица или представление)
<присваивание> — присваивание, которое будет выполняться при каждом выполнении условия <условие>, или для каждой записи, если отсутствует раздел where
<условие> — условие выполнения команды
SET — после ключевого слова должен идти список полей таблицы, которые будут обновлены и непосредственно сами новые значения в виде
имя поля="значение"
- DELETE удаляет данные
DELETE FROM <Имя Таблицы> WHERE <Условие отбора записей>
- SELECT считывает данные, удовлетворяющие заданным условиям
Общий формат оператора SELECT имеет следующий вид, где в угловых скобках заданы определяемые пользователем слова-параметры:
SELECT [ALL | DISTINCT] [{<таблица>|<псевдоним>}.]{* | <выражение> [AS <другое имя столбца>]} [,…]
FROM <таблица> [<псевдоним>] [,…]
[WHERE <условие отбора записей>]
[GROUP BY <группируемый столбец>, [,…]]
[HAVING <условие отбора групп>]
[ORDER BY <сортируемый столбец> [ASC | DESC] [,…]]
Обязательными в операторе являются только конструкции SELECT и FROM. Ключевое слово ALL указывает на необходимость включения в результирующую выборку всех записей, удовлетворяющих запросу, в том числе повторяющихся, если они есть. Ключевое слово DISTINCT используется для удаления дублирующих строк, то есть в результирующую выборку не будут включаться записи, совпадающие по значениям всех полей с одной из ранее отобранных. Параметр <таблица> представляет собой имя таблицы БД, из которой осуществляется выборка. <выражение> задает имя столбца таблицы или выражение из нескольких имен, определяющее вычисляемое поле, содержимое которого включается в результирующую выборку. Выражение помимо имен столбцов, арифметических операций сложения, вычитания, умножения и деления, а также круглых скобок, используемых в сложных выражениях, может содержать в зависимости от диалекта языка те или иные функции от значений полей. Звездочка (*) вместо имени столбца указывает на необходимость включения всех полей. Название любого столбца в результирующей таблице может быть изменено с помощью параметра <другое имя столбца>, что обычно используется для именования вычисляемых полей. Если данные извлекаются из нескольких таблиц, которые имеют совпадающие по названию столбцы, то имя каждого поля должно предваряться именем или псевдонимом таблицы. Псевдоним задает сокращенное имя для таблицы, используемое в пределах данного оператора. Параметр <условие отбора записей> описывает фильтр, определяющий какие строки должны быть включены в результат. <группируемый столбец> задает имя поля, по значениям которого производится группировка записей. Параметр <условие отбора групп> представляет фильтр, накладываемый на сформированные группы. Наконец, <сортируемый столбец> указывает название поля, в соответствии со значениями которого должна быть упорядочена формируемая выборка. Результат выполнения оператора представляет собой таблицу, в которой находятся извлеченные из БД сведения.
Обработка элементов оператора SELECT осуществляется в следующей последовательности:
FROM. Определяются имена используемых таблиц и условия их объединения, и формируется исходный набор строк результата.
WHERE. В соответствии с заданным условием выполняется фильтрация полученного набора и исключаются ненужные записи.
GROUP BY. Образуются группы строк, имеющих одни и те же значении в указанных столбцах.
HAVING. Выполняется фильтрация полученных на предыдущем шаге групп в соответствии с заданным условием.
SELECT. Устанавливается, какие столбцы необходимо включить в результирующую таблицу.
ORDER BY. Определяется порядок сортировки и набор столбцов, по значениям которых она выполняется для получения конечного результата.
7) JOIN – внутреннее соединение таблиц.
SELECT FIELD [,... n] FROM Table1