 2014-02-24
2014-02-24 45100
45100Учебное заведение: Направление подготовки – 080100 Экономика, Профиль подготовки – Финансы и кредит. Тип материала: Конспект
Под архитектурой ЭВМ понимается совокупность общих принципов организации аппаратно-программных средств и их характеристик, определяющая функциональные возможности ЭВМ при решении соответствующих классов задач.
Открытая архитектура - предполагает наличие единого стандарта при разработке устройств, располагающихся на материнской плате и плате расширения.
Структура компьютера — это некоторая модель, устанавливающая состав, порядок и принципы взаимодействия входящих в нее компонентов
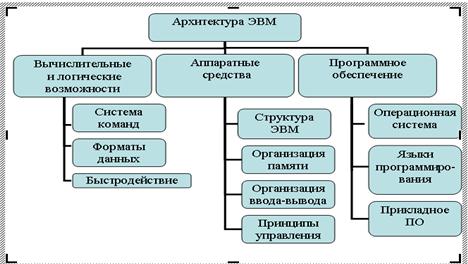
Рисунок 3 – архитектура ЭВМ.
В настоящее время наибольшее распространение в ЭВМ получили 2 типа архитектуры: Принстонская (фон Неймана) и Гарвардская. Обе они выделяют 2 основных узла ЭВМ: центральный процессор и память компьютера. Различие заключается в структуре памяти: в принстонской архитектуре программы и данные хранятся в одном массиве памяти и передаются в процессор по одному каналу, тогда как гарвардская архитектура предусматривает отдельные хранилища и потоки передачи для команд и данных.
Согласно Джону фон Нейману, любая ЭВМ должна включать четыре основных блока - процессор, оперативную память, внешнюю память и комплекс устройств ввода-вывода
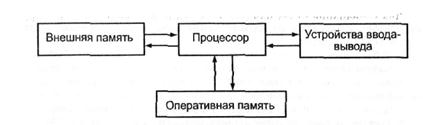
Рисунок 4 – Структурная схема ЭВМ
Эта схема, широко использовавшаяся в первых вычислительных машинах, имела один существенный недостаток: управление вводом-выводом и выполнение команд осуществлялось одним устройством управления. При такой структуре ЭВМ все виды программной обработки на время выполнения операций ввода-вывода прекращались из-за занятости процессора, что существенно снижало быстродействие машины.
Для устранения этого недостатка в схему был включен дополнительный компонент - канал ввода-вывода (устройство, обеспечивающее прямое взаимодействие процессора и периферийных устройств).
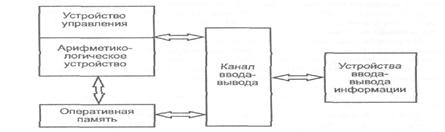
Гарвардская архитектура — архитектура ЭВМ, отличительным признаком которой является раздельное хранение и обработка команд и данных. Архитектура была разработана Говардом Эйкеном в конце 1930-х годов в Гарвардском университете
Типичные операции (сложение и умножение) требуют от любого вычислительного устройства нескольких действий: выборку двух операндов, выбор инструкции и её выполнение, и, наконец, сохранение результата.
Идея, реализованная Эйкеном, заключалась в физическом разделении линий передачи команд и данных. В первом компьютере Эйкена «Марк I» для хранения инструкций использовалась перфорированная лента, а для работы с данными — электромеханические регистры. Это позволяло одновременно пересылать и обрабатывать команды и данные, благодаря чему значительно повышалось общее быстродействие.
В более подробное описание, определяющее конкретную архитектуру, также входят: структурная схема ЭВМ, средства и способы доступа к элементам этой структурной схемы, организация и разрядность интерфейсов ЭВМ, набор и доступность регистров, организация памяти и способы её адресации, набор и формат машинных команд процессора, способы представления и форматы данных, правила обработки прерываний.
По перечисленным признакам и их сочетаниям среди архитектур выделяют:
1. По разрядности интерфейсов и машинных слов: 8-, 16-, 32-, 64-, 128- разрядные (ряд ЭВМ имеет и иные разрядности);
2. По особенностям набора регистров, формата команд и данных: CISC, RISC, VLIW;
3. По количеству центральных процессоров: однопроцессорные, многопроцессорные, суперскалярные; многопроцессорные по принципу взаимодействия с памятью: симметричные многопроцессорные (SMP), масcивно-параллельные (MPP), распределенные.
Большинство многопроцессорных систем сегодня используют архитектуру SMP.
SMP системы позволяют любому процессору работать над любой задачей независимо от того, где в памяти хранятся данные для этой задачи; с должной поддержкой операционной системы, SMP системы могут легко перемещать задачи между процессорами эффективно распределяя нагрузку. С другой стороны, память гораздо медленнее процессоров, которые к ней обращаются, даже однопроцессорным машинам приходится тратить значительное время на получение данных из памяти. В SMP только один процессор может обращаться к памяти в данный момент времени.
Массивно-параллельная архитектура (англ. Massive Parallel Processing, MPP) — класс архитектур параллельных вычислительных систем Особенность архитектуры состоит в том, что память физически разделена. Система строится из отдельных модулей, содержащих процессор, локальный банк операционной памяти, коммуникационные процессоры или сетевые адаптеры, иногда — жесткие диски и/или другие устройства ввода/вывода. Доступ к банку операционной памяти из данного модуля имеют только процессоры из этого же модуля. Модули соединяются специальными коммуникационными каналами. в отличие от SMP-систем, в машинах с раздельной памятью каждый процессор имеет доступ только к своей локальной памяти, в связи с чем не возникает необходимости в потактовой синхронизации процессоров.
Распределённые вычисления, метакомпьютинг (англ. grid — сеть) - способ решения трудоёмких вычислительных задач с использованием нескольких компьютеров, объединённых в параллельную вычислительную систему (одновременное решения различных частей одной вычислительной задачи несколькими процессорами (или ядрами одного процессора) одного или нескольких компьютеров)
В суперскалярных процессорах также есть несколько вычислительных модулей, но задача распределения между ними работы решается аппаратно. Это сильно усложняет дизайн процессора, и может быть чревато ошибками. В процессорах VLIW задача распределения решается во время компиляции и в инструкциях явно указано, какое вычислительное устройство должно выполнять какую команду.
Суперскалярность — архитектура вычислительного ядра, использующая несколько декодеров команд, которые могут нагружать работой множество исполнительных блоков. Планирование исполнения потока команд является динамическим и осуществляется самим вычислительным ядром. Если в процессе работы команды, обрабатываемые конвейером, не противоречат друг другу, и одна не зависит от результата другой, то такое устройство может осуществить параллельное выполнение команд. В суперскалярных системах решение о запуске инструкции на исполнение принимает сам вычислительный модуль, что требует много ресурсов








