 2014-02-24
2014-02-24 2716
2716Кодирование текста
Кодирование текста-это установление таблицы соответствия между кодируемым символом и комбинацией состояния битов, то есть процесс кодирования заключается в том, что каждому символу ставится в соответствие уникальный код. В настоящее время существуют различные системы кодирования, основное различие между ними заключается в количестве бит, необходимых для кодирования одного символа.
· ASCII (American Standard Code for Information Interchange): для кодирования одного символа используется количество информации=7 бит. Если рассматривать символы как возможные события (см. лекцию 1), то можно вычислить количество символов, которые можно закодировать:
27=128
2*26-латинские буквы
10-цифры
32-различные знаки
34-служебные символы
128-символов
Таким образом, количество кодируемых символов ограничено, поэтому в семибитной системе кодировки невозможно закодировать буквы русского алфавита. Возникла задача одновременно изображать и русские, и латинские символы. Способами решения этой задачи являются транслитерация и расширение кодировки.
· Восьмибитные системы кодировки:
28=256
Если старший бит кода-0, то система кодировки совпадает с ASCII, если старший бит –1, то вводятся дополнительные кодов-ые страницы.
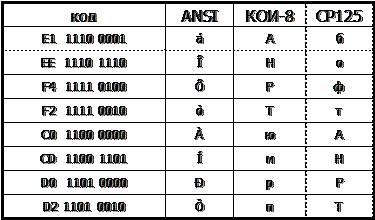
В России была создана одна из таких систем КОИ-8, ее недостаток в том, что русские буквы расположены не по алфавиту.Кроме того существуют СР-866, СР-1251, ANSI, использующиеся в операционной системе Windows.
· Большие кодовые страницы:
- UNICODE
На кодирование одного символа необходимо 16 бит
216=65535
естественно с такой системой кодирования не возникает проблемы невозможности кодировки того или иного символа, так как 65535 с избытком покрывает многообразие используемых символов, но UNICODE имеет другой недостаток: при переводе текстов из ASCII в UNICODE существенно увеличивается размер компьютерного текста. В связи с этим разработан еще один класс систем кодировки, использующих переменное число бит для кодирования символов.
- UTF-8
Если старший бит кода равен нулю (бит8=0), то система кодировки совпадает с ASCII, причем каждый из первых 128 символов кодируется одним байтом.
Если старший равен единице (бит8=1, бит7=0), то следующие 16384 символа кодируются аналогично UNICODE, то есть для кодировки каждого символа используется два байта. Оставшиеся символы (65535-128-16384=49023) кодируются тремя байтами.
Пример: рассмотрим, сколько информации несет цепочка символов "Information×-×Информация"
в различных системах кодировки. В случае СР1251 каждый символ кодируется одним байтом Þ количество информации: 24*1=24 байт. В UNICODE каждый символ кодируется двумя байтами Þ количество информации: 24*2=48 байт. В UTF-8 на кодировку латинских букв, знаков пробела и тире необходимо один байт на каждый символ, а каждый символ слова "Информация" кодируется двумя байтами Þ количество информации: 14*1+10*2=34 байт.
С одной стороны, компьютерный текст – это алфавитный, по которому текст представляется как цепочка символов (алфавитный подход). Другой подход заключается в том, что компьютерный текст рассматривается уже как сложная структура, состоящая из множества всех цепочек символов.
t:{1, 2, 3...k} - одна из таких цепочек длиной k.
Такой подход дает возможность понять алгоритм преобразования текста, который осуществляется по принципу функционального отображения, то есть одной текстовой цепочке, входящей в область определения этого алгоритма, ставится в соответствие другая цепочка, являющаяся результатом преобразования: t1®t2. В таком случае областью определения функции (алгоритма) будет являться язык.
Грамматика языка – это правила, порождающие все входящие в язык цепочки. Отдельный символ алфавита – это регулярное выражение. Грамматики, построенные на регулярных выражениях, записываются в виде программы, которая порождает цепочку символов. Назначение регулярных выражений – задать множество цепочек, составляющих язык.

