 2014-02-09
2014-02-09 1173
1173I j
a – нижняя цена игры;
b – верхняя цена игры;
a = b – решение находится в области чистых стратегий;
a ≠ b – стратегии смешанные;
c 33 – седловая точка (отклонение уменьшает выигрыш).
Если стратегии известны, то они называются числовыми стратегиями.
Суть принципа:
Если стратегия В не известна для А, то А выбирает стратегию, обеспечивающую из минимально возможных выигрышей максимальное значение.
Если стратегия А не известна для В, то В применяет стратегию, обеспечивающую минимальный из максимально возможных проигрышей.
Если А стала известна стратегия В, то А выбирает ту стратегию, которая приведет В к максимальному проигрышу.
Если В известна стратегия А, то В выбирает стратегию, обеспечивающую минимальный выигрыш А.
Математические модели теории игр с неполной информацией
Если седловой точки нет, то для А стратегии смешанные. Выбор стратегии ограничен с вероятностями или частотами при многократной игре:
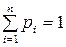 ;
; 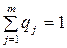 ,
,
где pi, qi - вероятности применения стратегий А и В.
Математическая модель задачи со смешанной стратегией для А имеет вид:
│ A1 A2 A3 │ │B1 B2 B3 B4 │
SA = │ │; SB = │ │
│ p1 p2 p3 │ │q1 q2 q3 q4 │
Σpi = 1; Σqi = 1.
Смешанная стратегия, которая гарантирует данной стороне наибольший возможный выигрыш (или наименьший проигрыш) независимо от действия другой стороны, называется оптимальной.
Средний выигрыш стороны А:
Y = Σ Σ cij pi qj; Σ pi = 1; Σ qi = 1.
Для получения оптимальных вероятностей использования стратегий Ai(Bj) необходимо учитывать, что
∂ Y /∂ p 1 = 0, i =1, 2, 3, …, n;
∂ Y /∂ q 1, j =1, 2, 3, …, m
Например:
| B 1 | B 2 | |
| A 1 | C 11 | C 12 |
| A 2 | C 21 | C 22 |
SA = 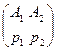 ; SB =
; SB = 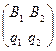
Y = C 11 p 1 q 1 + C 12 p 1 q 2 + C21p2q 1 + C 22 p 2 q 2;
p 1 + p 2 = 1 → p 1 = p p 2 = 1– p;
q 1 + q 2 = 1 → q 1 = q q 2 = 1 – q;
Y = C 11 pq + C 12 p (1– q) – C 21(1– p) q + C 22(1– p)(1– q);
∂Y/∂p = C 11 q+C 12(1– q)– C 21 q – C 22(1– q) = (C 11– C 12– C 21 +C 22) q+C 12– C 22 = 0;
∂Y/∂ q = C 11 p – C 12 p+C 21(1– p)– C 22(1– p) = (C 11– C 12– C 21 +C 22) p+C 21– C 22= 0;
q = (C 22– C 12)/(C 11 – C 12 – C 21 + C 22); 0 < p < 1;
p = (C 22– C 21)/(C 11 – C 12 – C 21 + C 22); 0 < q < 1.
Максимальный средний выигрыш:
Y max = (C 11 C 22 – C 12 C 21)/ (C 11 – C 12 – C 21 + C 22).
Числовой пример:
р = (0–16)/(23–16+8+0) = –16/15 = –1,06
р 1 = 0; р 2 = 1;
q = (0+8)/15 = 0,53;
q 1 = 0,53; q 2 = 0,47.
Математические модели теории игр в условиях неопределенности. Принцип Гурвица
Когда нет вероятностной информации об игре, вводится коэффициент φ, учитывающий возможность предполагаемого выигрыша(коэффициент оптимизма).
Максимально возможный выигрыш определяется по формуле:
Z 1 = φ А 2 + (1 – φ) A 1
| Суммарная платежная матрица | Наименьший выигрыш A 1 | Наибольший выигрыш А 2 | φ 1=0,4 | φ2=0,2 | |||
| 15,8 | 9,4 | ||||||
| 36,6 | 18,8 | ||||||
Большинство инженерных задач связано с распознаванием образов. При их решении существует проблема эффективного распознавания объектов и отнесение их к существующим классам.
Создание устройств, выполняющих функции распознавания различных объектов, в большинстве случаев обеспечивает возможность замены человека специализированным автоматом. Благодаря этому, значительно расширяются возможности сложных систем, выполняющих различные информационные, логические, аналитические задачи. Следует отметить, что качество работ, выполняемых человеком на рабочем месте, зависит от многих факторов (квалификации, опыта, добросовестности и т. д.). В то же время исправный автомат действует однообразно и обеспечивает всегда одинаковое качество. Автоматический контроль сложных систем позволяет вести мониторинг и обеспечивать своевременное обслуживание, идентификацию помех и автоматическое применение соответствующих методов шумоподавления, позволяет повысить качество передачи информации. Также понятно, что использование автоматических систем в ряде задач может обеспечить невозможное для человека быстродействие.
Распознавание образов (объектов, сигналов, ситуаций, явлений или процессов) – задача идентификации объекта или определения каких-либо его свойств по его изображению (оптическое распознавание) или аудиозаписи (акустическое распознавание) и другим характеристикам.
Одним из базовых является не имеющее конкретной формулировки понятие множества. В компьютере множество представляется набором неповторяющихся однотипных элементов. Слово «неповторяющихся» означает, что какой-то элемент в множестве либо есть, либо его там нет. Универсальное множество включает все возможные для решаемой задачи элементы, пустое не содержит ни одного.
Образ – это классификационная группировка в системе классификации, объединяющая (выделяющая) определенную группу объектов по некоторому признаку. Образы обладают характерным свойством, проявляющимся в том, что ознакомление с конечным числом явлений из одного и того же множества дает возможность узнавать сколь угодно большое число его представителей. Образы обладают характерными объективными свойствами в том смысле, что разные люди, обучающиеся на различном материале наблюдений, большей частью одинаково и независимо друг от друга классифицируют одни и те же объекты. В классической постановке задачи распознавания универсальное множество разбивается на части-образы. Каждое отображение какого-либо объекта на воспринимающие органы распознающей системы, независимо от его положения относительно этих органов, принято называть изображением объекта, а множества таких изображений, объединенные какими-либо общими свойствами, представляют собой образы.
Методика отнесения элемента к какому-либо образу называется решающим правилом. Еще одно важное понятие – метрика, способ определения расстояния между элементами универсального множества. Чем меньше это расстояние, тем более похожими являются объекты (символы, звуки и др.), т.е. то, что мы распознаем. Обычно элементы задаются в виде набора чисел, а метрика – в виде функции. От выбора представления образов и реализации метрики зависит эффективность программы, один алгоритм распознавания с разными метриками будет ошибаться с разной частотой.
Вводя понятие сходства между образами можно поставить задачу распознавания. Конкретный вид такой постановки сильно зависит от последующих этапов при распознавании в соответствии с тем или иным подходом.
Задача классификации – формализованная задача, в которой имеется множество объектов (ситуаций), разделенных некоторым образом на классы. Задано конечное множество объектов, для которых известно, к каким классам они относятся. Это множество называется выборкой. Классовая принадлежность остальных объектов неизвестна. Требуется классифицировать произвольный объект из исходного множества, т.е. указать номер (или наименование) класса, которому относится данный объект.
Объект представляет собой отдельные предметы и явления, которые необходимо распознать. Объекты обладают общими свойствами и имеют некоторые отличительные свойства. Например, к классу карандаш относятся карандаши всех размеров и цветов, к классу красный карандаш относятся карандаши с красными грифелями, а к классу пишущие устройства – карандаши, ручки и т.д.
Класс представляет собой множество предметов или объектов, обладающих некоторыми общими свойствами. Как правило, имеется набор классов, каждый из которых может быть представлен некоторым количеством объектов. Например, имеется по 100 штук красных, желтых, синих карандашей разных оттенков и размеров.
Совокупность различных объектов для всех классов образует множество возможных реализаций:
А = { A 1, A 2, …, Ai, …, Am },
где: Аi = { a 1, a 2, …, aj, …, an } – отдельный i -й класс; aj – отдельный объект; m – общее число классов; n – общее число объектов.
В большинстве практических задач m является величиной конечной и значительно меньшей n (m << n). Однако если значения признака изменяются непрерывно, то m = ¥.
Обучением обычно называют процесс выработки в некоторой системе той или иной реакции на группы внешних идентичных сигналов путем многократного воздействия на систему внешней корректировки. Такую внешнюю корректировку в обучении принято называть «поощрениями» и «наказаниями». Механизм генерации этой корректировки практически полностью определяет алгоритм обучения. Самообучение отличается от обучения тем, что здесь дополнительная информация о верности реакции системе не сообщается.
Адаптация – это процесс изменения параметров и структуры системы, а возможно - и управляющих воздействий, на основе текущей информации с целью достижения определенного состояния системы при начальной неопределенности и изменяющихся условиях работы.
Методы распознавания образов
В целом, можно выделить три метода распознавания образов:
1. Метод перебора. В этом случае производится сравнение с базой данных, где для каждого вида объектов представлены всевозможные модификации отображения. Например, для оптического распознавания образов можно применить метод перебора вида объекта под различными углами, масштабами, смещениями, деформациями и т. д. Для букв нужно перебирать шрифт, свойства шрифта и т. д. В случае распознавания звуковых образов, соответственно, происходит сравнение с некоторыми известными шаблонами (например, слово, произнесенное несколькими людьми).
2. Более глубокий анализ характеристик образа. В случае оптического распознавания это может быть определение различных геометрических характеристик (связность контура, наличие углов и т.д.). Звуковой образец в этом случае подвергается частотному, амплитудному анализу и т. д.
3. Использование искусственных нейронных сетей. Этот метод требует либо большого количества примеров задачи распознавания при обучении, либо специальной структуры нейронной сети, учитывающей специфику данной задачи. Тем не менее, его отличает более высокая эффективность и производительность.
Математическая постановка задачи
Пусть Х – множество описаний объектов, Y – множество номеров (или наименований) классов. Существует неизвестная целевая зависимость – отображение y*: Х → Y, значения которой известны только на объектах конечной обучающей выборки Xm = {[x1, y1),…,(xm, ym)}.
Требуется построить алгоритм а: Х → Y, способный классифицировать произвольный объект х 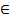 Х.
Х.

