 2014-02-09
2014-02-09 1190
1190Текст лекции
Ключевые вопросы
Лекция № 5. Управление индексами
Продолжительность: 2 часа (90 мин.)
· Создание индексов.
· Перестроение индексов.
· Обновление статистики.
· Использование индексов.
· Формирование эффективных индексов.
Создание индекса не представляет особых сложностей. Кластеризованные и некластеризованные индексы создаются аналогичным образом с помощью мастеров в Enterprise Manager или с помощью команды SQL CREATE INDEX.
Используя T-SQL для создания индекса, вы можете генерировать сценарий для соответствующей команды и запускать его многократно. Вы можете также модифицировать сценарий создания индекса для создания других индексов. Кроме того, этот метод создания индекса дает вам больше гибкости, поскольку вы имеете доступ к большему числу параметров. Чтобы использовать этот метод создания индекса, просто поместите команды T-SQL в файл и считывайте этот файл в OSQL, используя следующий синтаксис:
Osql -Uимя_пользователя -Pпароль < create_index.sql
В этой команде предполагается, что создаваемый вами файл имеет имя create_index.sql. Вы можете также выполнять этот сценарий с помощью анализатора запросов Query Аnalyzer.
Для создания индекса с помощью T-SQL вы должны использовать оператор CREATE INDEX. Эта команда имеет следующий синтаксис:
CREATE [UNIQUE] [CLUSTERED | NONCLUSTERED]
INDEX имя_индекса ON имя_таблицы
(
имя_колонки [, имя_колонки, имя_колонки,... ]
)
[ WITH параметры ]
[ ON имя_группы_файлов ]
Значения в прямоугольных скобках не являются обязательными. Вы можете создать уникальный или неуникальный индекс, кластеризованный или некластеризованный индекс, с одной или несколькими колонками и с необязательными параметрами, перечисленными в таблице 6.1. Вы можете также дополнительно указать группу файлов, куда нужно поместить данный индекс.
Таблица 6.1 — Необязательные параметры CREATE INDEX
| Параметр | Описание |
| PAD_INDEX | В сочетании с параметром FILL_FАСTOR указывает, что свободное место должно быть оставлено не только в узлах-листьях, но и в узлах-ветвях |
| FILL_FАСTOR? число | Указывает, в какой степени будет заполнен каждый узел-лист; значение в процентах задается в диапазоне от 0 до 100 |
| IGNORE_DUP_KEY | Указывает, что вставка дублированного значения в уникальный индекс будет игнорироваться и сопровождаться предупреждающим сообщением. Если параметр IGNORE_DUP_KEY не указан, то будет выполнен откат всей вставки |
| DROP_EXISTING | Указывает, что следует удалить существующий индекс с тем же именем и создать индекс снова. Этот параметр повышает производительность, если вы снова создаете кластеризованный индекс по таблице, имеющей некластеризованные индексы, поскольку для удаления и повторного создания некластеризованных индексов не требуется выполнять отдельные шаги |
| STATISTICS_NORECOMPUTE | Указывает, что не следует выполнять пересчет данных статистики. Этот параметр не рекомендуется использовать, поскольку планы исполнения будут основываться на старых данных и, вероятно, не будут оптимальными. Используйте этот параметр, только если планируете обновлять статистику вручную |
При обновлениях и вставках в таблице, имеющей индексы, страницы индекса тоже должны обновляться. Страницы индекса связаны друг с другом в цепочку указателями из одной страницы в другую. Имеется два указателя: один на следующую страницу и один на предыдущую. Если страница индекса заполнена до конца, то изменение в индексе приводит к изменению в цепочке указателей, поскольку между двумя страницами должна быть вставлена новая страница (в форме процесса, который называется расщеплением страницы индекса, чтобы новую информацию можно было поместить в нужном месте цепочки индекса. SQL Server перемещает приблизительно половину строк существующей страницы (где должны следовать новые данные) в эту новую страницу индекса. Две страницы, которые указывали друг на друга, теперь будут указывать на новую страницу, а новая страница – на эти две страницы (как на следующую и предыдущую). Теперь ссылка на новую страницу индекса указывает в нужное место цепочки, но страницы индекса физически уже не следуют друг за другом в базе данных (см. рисунок 6.1). В конце концов, из-за того, что в индекс постоянно добавляются новые строки индекса (в предположении, что происходят обновления и вставки), а страница индекса имеет конечный размер, заполняется все больше и больше страниц. При этом требуется находить дополнительное пространство для новых страниц индекса. Для этого SQL Server продолжает выполнять расщепление страниц индекса, что приводит к дополнительной нагрузке на систему из-за более активного использования ЦП (CPU) и большего числа операций ввода-вывода. Кроме того, это приводит к фрагментированию индекса. Данные индекса "разбрасываются" в базе данных, вызывая снижение производительности.
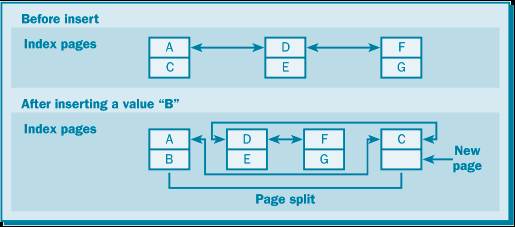
Рисунок 6.1 — Расщепление страницы индекса
Одним из способов снижения степени расщепления и фрагментации страниц является настройка коэффициента заполнения узлов индекса. Коэффициент заполнения указывает процент заполнения узла при создании индекса, что позволяет оставить место для дополнительных строк индекса. Вы можете задать коэффициент заполнения для индекса с помощью параметра FILL_FАСTOR оператора T-SQL CREATE INDEX, как это описано выше. Если коэффициент заполнения не указан в команде CREATE INDEX, то используется значение по умолчанию данной системы. Значение по умолчанию равно значению параметра fill fАсtor, заданному в процедуре sp_configure. Это значение было задано равным 0, когда вы инсталлировали SQL Server.
Параметр fill faсtor влияет только при создании индекса; его изменение не оказывает влияния после того, как произошло построение индекса. Значение коэффициента заполнения изменяется в диапазоне от 0 до 100, указывая процент заполнения страницы индекса. Значение 0 соответствует особому случаю. В этом случае узлы-листья заполняются полностью, но в узлах-ветвях и корневом узле остается свободное место. Это значение задается по умолчанию при инсталляции SQL Server и обычно дает хорошие результаты.
Значение коэффициента заполнения 100 указывает, что при создании индекса все узлы индекса будут заполняться полностью. Это оптимальное значение для индексов по таблицам, в которые никогда не будут заноситься новые данные и которые не будут обновляться. Как узлы-листья, так и узлы более высоких уровней будут заполняться до конца, и любая вставка будет приводить к расщеплению страниц. Таблицы, используемые только по чтению, идеально подходят для этого значения, хотя удаление данных допустимо, поскольку не вызывает расщепления страниц.
Низкое значение коэффициента заполнения оставляет много места для вставок, но требует много дополнительного пространства для создания индекса. Если вам не требуются постоянные вставки в базу данных, то низкое значение коэффициента заполнения обычно не рекомендуется. Если происходит слишком много расщеплений страниц, попытайтесь снизить значение коэффициента заполнения и повторно генерировать индекс, чтобы посмотреть, снизится ли при этом количество расщеплений страниц.
Вы можете определять количество расщеплений страниц в секунду, происходящих в вашей системе, с помощью счетчика Page Splits/Sec окна PerformАnce Monitor. Этот счетчик можно найти в объекте SQL Server: Асcess Methods.
Если по прошествии времени расщепления страниц все же происходят и ваши индексы становятся излишне фрагментированными, то решением является перестроение ваших индексов. Фрагментация может происходить, даже если вы используете коэффициент заполнения, оставляющий свободное пространство на страницах индекса. В конце концов, это пространство тоже может быть исчерпано. Более подробную информацию см. в разделе "Перестроение индексов" далее.








