2015-01-21
2015-01-21 360
360Пользователь изначально указал некоторое множество релевантных документов.
Шаг 1. Построение словника терминов по множеству релевантных документов. Т.е. строится матрица LRel.
Шаг 2. Оценка терминов словника и построение Поискового Образа Темы (ПОТ).
Результатом оценивания должно быть выделение тех терминов, которые могут быть включены в ПОТ. Рекомендованный способ отбора терминов: точность термина (=частота термина в множестве релевантных документов/частота термина в информационном массиве) должна превышать параметр, вычисляемый как 1/ nS. Эвристический параметр nS характеризует число ожидаемых документов.
Шаг 3. Построение матрицы «термин-документ» (получается вычеркиванием строк терминов, которые не попали в ПОТ). 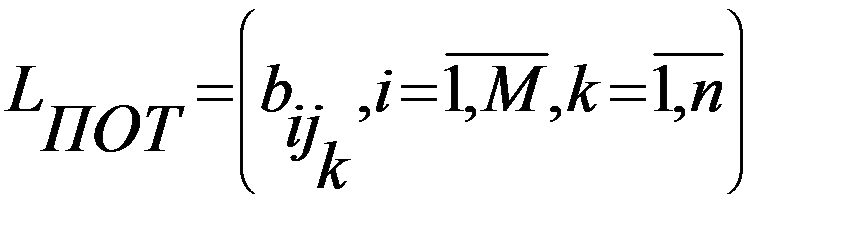 , где M – количество терминов в ПОТ, определяющее порог «близости» для следующего шага, n – число релевантных документов. //Столбец-термин, строка-документ
, где M – количество терминов в ПОТ, определяющее порог «близости» для следующего шага, n – число релевантных документов. //Столбец-термин, строка-документ
Шаг 4. Поиск аналогов с пороговым значением M. По матрице «термин-документ» формируется поисковый результат с учетом порога близости M. Если число документов полученного результата меньше, чем заданное в системе nS, то пороговое значение M уменьшается на 1, и повторяется процедура поиска аналогов с новым пороговым значением. Таким образом, на каждой i -ой итерации пороговое значение равно M–i.
Цикл заканчивается: либо после выполнения очередной итерации число документов результата стало равно или превысило значение nS, либо пороговое значение стало равно 0.