 2015-01-21
2015-01-21 1064
1064Используем понятие универсального словаря D (прообразом которого может быть, например, тезаурус, рубрикатор), содержащего множество лексических единиц всего потока документов (то есть все слова, числа и прочие обозначения, использованные во всех документах системы). Таким образом, li принадлежит D для всех i, где li — совокупность лексических единиц некоторого документа (сообщения), который является элементом некоторого потока L: L={l1,...,li,..., ln}, li 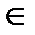 L для всех i
L для всех i
Универсальный массив L0 (ИМЕТЬ В ВИДУ, НО ЛУЧШЕ НЕ ПИСАТЬ: прообразы — поисковый массив ИПС, отраслевой справочно-информационный фонд, массив библиотеки), подмножеством которого являются все документы:
L0 = {l1,...,li,..., l n0 }, li L0 для всех i, причем | L0 | = n0, где n0, — мощность множества L0. Линейное представление теоретико-множественного образа документа:
lk= 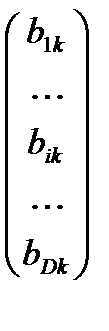 , где bik=
, где bik= 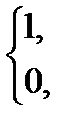 1-если i-й термин входит в k-й документ;0- если не входит.
1-если i-й термин входит в k-й документ;0- если не входит.
Универсальный массив в линейном представлении есть матрица размерности D х n0:
Подобные матрицы известны под названием матрицы « термин—документ ». Каждый столбец матрицы соответствует документу и описывает множество терминов, содержащихся в нем.Таким образом, столбец матрицы характеризует ПОД. Строка матрицы соответствует отдельному термину и является перечнем документов, содержащих данный термин. Сумма элементов строки представляет собой частотную характеристику термина: Fi=∑bik.
Составим матрицу 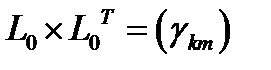 , где
, где 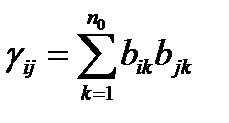 .Матрица
.Матрица 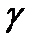 имеет размерность
имеет размерность 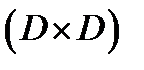 . Внедиагональный элемент
. Внедиагональный элемент 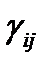 есть количество появлений i-го и j-го терминов в
есть количество появлений i-го и j-го терминов в 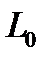 , диагональный – i-го. Матрицы такого типа называют «матрица термин-термин» и характеризуют взаимосвязь терминов в данном массиве.
, диагональный – i-го. Матрицы такого типа называют «матрица термин-термин» и характеризуют взаимосвязь терминов в данном массиве.
Составим матрицу L0T x L0 = (δkm), δkm= 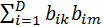 . Размерность n0 x n0, внедиагональные элементы характеризуют степень попарных пересечений сообщений из L0:
. Размерность n0 x n0, внедиагональные элементы характеризуют степень попарных пересечений сообщений из L0: 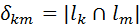
Диагональные элементы задают длины сообщений: 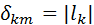
В целом задает распределения пересечений документов и их длин.

