 2015-01-21
2015-01-21 9407
9407Предположение о постоянстве и конечности дисперсии остатков называется свойством гомоскедастичности остатков (рисунок 5.1). В практических исследованиях это свойство случайной ошибки модели регрессии не всегда выполняется и дисперсия остатков не является постоянной величиной (рисунок 5.2). Такое явление называется гетероскедастичностью.
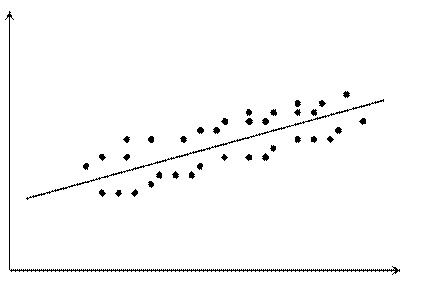
Рис. 5.1. Линейная модель с гомоскедастичностью
Гетероскедастичность часто вызывается ошибками спецификации, когда не учитывается в модели существенная переменная.
Гетероскедастичность приводит к тому, что оценки коэффициентов регрессии не являются эффективными, т.е. их дисперсии не будут наименьшими. Как следствие рассчитанные значения стандартных ошибок коэффициентов регрессии могут быть заниженными, а потому при проверке статистической значимости коэффициентов может быть ошибочно принято решение об их значимом отличии от нуля, тогда как на самом деле это не так.
Проблема гетероскедастичности характерна для пространственных данных, полученных от неоднородных объектов. Например, если исследуется зависимость расходов на питание в семье от ее общего дохода, то можно ожидать, что разброс данных будет выше для семей с более высоким доходом. Если исследуется зависимость оплаты труда сотрудников предприятий в зависимости от размера основных фондов предприятий и разряда работника, то понятно, что вариация оплаты труда на крупных предприятиях у сотрудников высокого разряда будет значительно превосходить его вариацию для сотрудников низких уровней на малых и средних предприятиях.
Гетероскедастичность иногда возникает и во временных рядах. Это происходит в тех случаях, когда зависимая переменная имеет большой интервал качественно неоднородных значений или высокий темп изменения (инфляция, технологические сдвиги, изменения в законодательстве, потребительские предпочтения и т.д.).
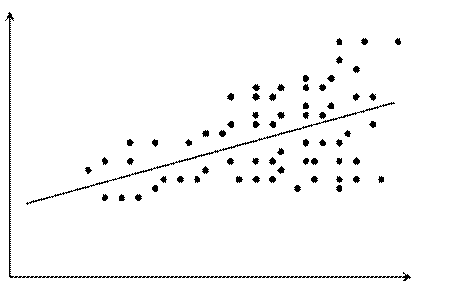
Рис. 5.2. Линейная модель с гетероскедастичностью
В настоящее время для оценки нарушения гомоскедастичности предложено большое число тестов. Чаще всего используются графический анализ отклонений, тест ранговой корреляции Спирмена и тест Голдфелда-Квандта.
Графический анализ отклонений заключается в визуальной оценке разброса точек корреляционного поля около линии регрессии: считается, что условие 2 выполняется, если точки наблюдений расположены внутри полосы постоянной ширины, окаймляющей линию регрессии (например, как на рисунке 5.1). Для множественной регрессии осуществляется графический анализ корреляционных полей объясняемой переменной 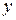 в зависимости от каждого из факторов
в зависимости от каждого из факторов 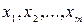 .
.
Наиболее популярным тестом обнаружения гетероскедастичности является тест Голдфелда-Квандта. Тест применяется в том случае, если ошибки регрессии можно считать нормально распределенными случайными величинами. Кроме того, в основе его лежит предположение о пропорциональности дисперсий случайного члена значению выбранной объясняющей переменной. Тест проводится по следующей схеме.
1. На основе выборочных данных строится линейная модель множественной регрессии с 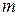 объясняющими переменными .
объясняющими переменными .
2. В модели множественной регрессии (например, на основе графического анализа) выбирается факторная переменная, от которой предположительно могут зависеть остатки. Значения этой переменной ранжируются, располагаются по возрастанию и делятся на три части объемами 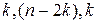 (обычно принимают
(обычно принимают 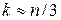 ).
).
3. Для первой и третьей частей строятся две независимые модели регрессии.
4. По каждой из построенных моделей рассчитывают суммы квадратов остатков S 1 и S 3.
5. Осуществляется проверка основной гипотезы об отсутствии гетероскедастичности с помощью 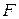 -критерия Фишера. Наблюдаемое значение -критерия рассчитывается следующим образом:
-критерия Фишера. Наблюдаемое значение -критерия рассчитывается следующим образом:
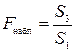 , если
, если 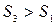 ,
,
или
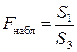 , если
, если 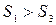 .
.
Если 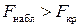 , то в основной модели присутствует гетероскедастичность, зависящая от выбранной объясняющей переменной (число степеней свободы определяется значениями
, то в основной модели присутствует гетероскедастичность, зависящая от выбранной объясняющей переменной (число степеней свободы определяется значениями 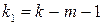 и
и 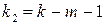 ).
).
Если нет уверенности относительно выбора объясняющей переменной, вызывающей гетероскедастичность, то тест осуществляется для каждой из объясняющих переменных .
Наличие гетероскедастичности в остатках регрессии можно проверить и с помощью теста ранговой корреляции Спирмена. При выполнении теста предполагается, что абсолютные величины остатков и значения объясняющей переменной коррелированны. Эту корреляцию можно измерять с помощью коэффициента ранговой корреляции Спирмена:
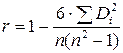 ,
,
где 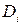 – разность между рангом
– разность между рангом 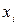 и рангом модуля остатка
и рангом модуля остатка 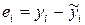 .
.
Тест проводится по следующей схеме.
1. Строится линейная модель регрессии.
2. Данные по 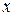 и модули остатков
и модули остатков 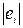 ранжируются по переменной , определяются их ранги (ранг – это порядковый номер значений переменной в ранжированном ряду).
ранжируются по переменной , определяются их ранги (ранг – это порядковый номер значений переменной в ранжированном ряду).
3. Осуществляется проверка основной гипотезы об отсутствии гетероскедастичности с помощью 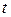 -статистики с
-статистики с 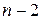 степенями свободы, где n – объем выборки. При этом наблюдаемое значение -критерия определяется равенством
степенями свободы, где n – объем выборки. При этом наблюдаемое значение -критерия определяется равенством 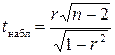 . Если
. Если 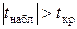 , то нулевая гипотеза об отсутствии гетероскедастичности отклоняется и имеет место гетероскедастичность в остатках регрессии, т.е. условие 2 не выполняется.
, то нулевая гипотеза об отсутствии гетероскедастичности отклоняется и имеет место гетероскедастичность в остатках регрессии, т.е. условие 2 не выполняется.
После установления в модели наличия гетероскедастичности возникает вопрос о том, в какой мере существенно она влияет на качество модели и следует ли вообще с гетероскедастичностью бороться. Ведь при гетероскедастичности оценки коэффициентов регрессии все равно остаются несмещенными и состоятельными, правда, не будут эффективными.
Если исследователь решил вступить в борьбу с гетероскедастичностью, то первый шаг на этом пути заключается в определении ее типа. Если гетероскедастичность вызвана ошибками спецификации, то для ее устранения необходимо включить в уравнение пропущенные существенные переменные и подобрать правильную функциональную форму. Если гетероскедастичность наблюдается в правильно специфицированных моделях (чистая гетероскедастичность), то можно воспользоваться взвешенным методом наименьших квадратов (ВМНК).
Данный метод применяется при известных для каждого наблюдения значениях дисперсиях 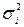 . В этом случае можно устранить гетероскедастичность, разделив каждое наблюдаемое значение на соответствующее ему среднеквадратическое отклонение. Тем самым обеспечивается равномерный вклад остатков в общую сумму.
. В этом случае можно устранить гетероскедастичность, разделив каждое наблюдаемое значение на соответствующее ему среднеквадратическое отклонение. Тем самым обеспечивается равномерный вклад остатков в общую сумму.
Таким образом, если при обычном МНК в случае парной линейной модели 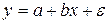 для нахождения ее параметров
для нахождения ее параметров 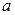 и
и 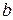 минимизируется сумма
минимизируется сумма 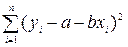 , то при ВМНК минимизируется сумма
, то при ВМНК минимизируется сумма
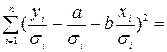
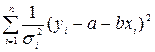 .
.
Применение ВМНК включает следующие этапы.
1. С помощью обычного МНК строится линейная регрессионная модель и
доказывается наличие гетероскедастичности остатков.
2. Для каждого наблюдения устанавливаются фактические значения дисперсий 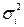 отклонений.
отклонений.
3. Значения каждой пары наблюдений 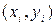 делятся на известную величину
делятся на известную величину 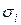 . Тем самым наблюдениям с наименьшими дисперсиями придаются наибольшие веса, а наблюдениям с наибольшими дисперсиями – наименьшие веса.
. Тем самым наблюдениям с наименьшими дисперсиями придаются наибольшие веса, а наблюдениям с наибольшими дисперсиями – наименьшие веса.
4. С помощью обычного МНК по преобразованным значениям 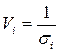 ,
, 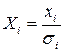 ,
, 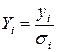 (такое преобразование называется масштабированием исходных данных) оценивается двухфакторное уравнение регрессии
(такое преобразование называется масштабированием исходных данных) оценивается двухфакторное уравнение регрессии 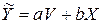 с нулевым свободным членом. Построенная модель гомоскедастична.
с нулевым свободным членом. Построенная модель гомоскедастична.
Описанный подход возможен и для уравнения множественной регрессии.
Главная проблема взвешенного метода наименьших квадратов состоит в необходимости знания среднеквадратических отклонений 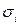 случайных ошибок регрессии. На практике дисперсии неизвестны. В таком случае делаются реалистические предположения об их величине. В частности, принимаются предположения о том, что либо дисперсии отклонений, либо сами среднеквадратичные отклонения
случайных ошибок регрессии. На практике дисперсии неизвестны. В таком случае делаются реалистические предположения об их величине. В частности, принимаются предположения о том, что либо дисперсии отклонений, либо сами среднеквадратичные отклонения 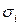 пропорциональны значениям переменной .
пропорциональны значениям переменной .
Следует иметь в виду, что коэффициенты и модели оценены по преобразованным данным, а потому изменяют свой первоначальный экономический смысл. В частности, если среднеквадратичные отклонения пропорциональны значениям , то обычным МНК оценивается преобразованная модель 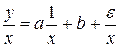 , в которой по сравнению с исходной моделью свободный член и угловой коэффициент как бы поменялись местами. Поэтому оценка свободного члена преобразованной модели характеризует изменение показателя при изменении фактора на одну единицу.
, в которой по сравнению с исходной моделью свободный член и угловой коэффициент как бы поменялись местами. Поэтому оценка свободного члена преобразованной модели характеризует изменение показателя при изменении фактора на одну единицу.

