 2015-03-22
2015-03-22 1112
1112Пользуясь средствами MS Excel построить имитационную модель простейшего потока событий, представленного вызовами автоматической телефонной станции.Интенсивность потока определена параметрами, которые определены в задаче 1. Время моделирования взять равным двум часам. Для первых 10-15 минут на числовой оси времени отметить моменты времени, соответствующие событиям в потоке. Вычислить количество минут (эмпирическую частоту) в течение этого часа, во время которых произошло ровно 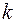 событий, где
событий, где 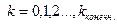 . Величину
. Величину 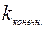 взять равной наибольшему значению, для которого частота больше нуля. Пользуясь критерием согласия Пирсона с уровнем значимости α=0.05, сравнить полученное эмпирическое распределение количества вызовов в единицу времени и теоретическое распределение Пуассона для заданной интенсивности. Убедиться в постоянстве среднего количества событий в минуту N / T н за достаточно продолжительные интервалы времени T н. Для этого провестивычисления, взяв T нравное 60 мин. (1 час), а начало интервала последовательно полагать равным 0, 10, 20, …, 60 мин. Сравнить полученные значения с интенсивностью потока l.
взять равной наибольшему значению, для которого частота больше нуля. Пользуясь критерием согласия Пирсона с уровнем значимости α=0.05, сравнить полученное эмпирическое распределение количества вызовов в единицу времени и теоретическое распределение Пуассона для заданной интенсивности. Убедиться в постоянстве среднего количества событий в минуту N / T н за достаточно продолжительные интервалы времени T н. Для этого провестивычисления, взяв T нравное 60 мин. (1 час), а начало интервала последовательно полагать равным 0, 10, 20, …, 60 мин. Сравнить полученные значения с интенсивностью потока l.
Указание. Подробное описание критерия согласия Пирсона для проверки совпадения двух распределений приведено в [2].
Р е ш е н и е. Проведем расчеты для потока событий, имеющего интенсивность l = 5 (мин -1). Чтобы построить поток событий, необходимо вычислить интервалы времени между соседними событиями в потоке. Поскольку длины этих интервалов распределены по экспоненциальному закону, необходимо построить генератор случайных чисел, который реализует такое распределение. Именно такой функции в MS Excel нет. С другой стороны в MS Excel есть функция СЛЧИС(), которая возвращает число, большее либо равное 0 и меньшее 1. При многократном вызове этой функции получаем последовательность чисел, которую можно рассматривать как реализацию равномерно распределенной случайной величины U в интервале [0,1] (U~U[0,1]). Новое случайное число возвращается при каждом вычислении на рабочем листе.
Как известно, если случайная величина распределена по равномерному закону распределению (U~U[0,1]), то случайная величина
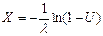 (3.21)
(3.21)
распределена по экспоненциальному закону с интенсивностью l.
Используя эти свойства, проведем все расчеты на рабочем листе рис.3.18-3.19. для изображения потока событий. Количество строк в таблице подбирается так, чтобы время события превысило 120 мин (2 час). В колонке А содержатся значения равномерно распределенной случайной величины, которые получены с помощью функции СЛЧИС().
В колонке В содержатся значения случайной величины распределенной по экспоненциальному закону, которые получены из значений колонки А путем преобразования (3.21), т.е. это интервал времени между соседними событиями.
В колонке С содержатся абсолютные значения моментов времени, в которые реализовались события данного потока.
Далее скопируем полученные значения на другой лист рабочей книги. Это необходимо сделать для обеспечения неизменности полученных результатов, поскольку функция СЛЧИС(), возвращает новое значение при каждом изменении рабочего листа.

Рис.3.18. Решение задачи 3 в MS Excel в режиме отображения данных (начало).
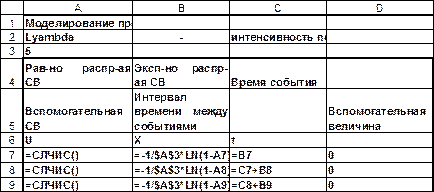
Рис.3.19. Решение задачи 3 в MS Excel в режиме отображения формул (начало).
С помощью графических средств MS Excel на числовой оси построим моменты времени соответствующие событиям в потоке, для этого используем часть данных из колонок C и D (рис.3.20). Количество строк берем таким образом, чтобы длина интервала была в интервале 10-15 мин.
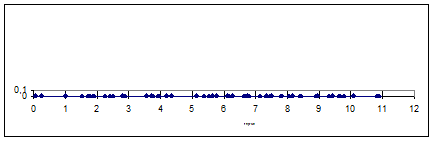
Рис.3.20. Решение задачи 3 в MS Excel (продолжение). На числовой оси отмечены моменты времени, соответствующие событиям в потоке
Вычислим количество событий в течение каждой минуты. Это можно сделать как вручную, так и с помощью надстройки «Пакет анализа» «Гистограмма». Диалоговое окно этой надстройки показано на рис.3.21, а результат её работы находится в интервале G6:H137 (рис.3.22).
Содержимое столбца Н в этом интервале будет реализацией случайной величиной - количеством событий в течение каждой минуты, полученной в результате моделирования. Числовые характеристики этой случайной величины могут быть получены с помощью инструмента «Описательная статистика» надстройки «Анализ данных», диалоговое окно которого показано на рис.3.23. Результат работы приведен на рис.3.24.
Среднее значение полученной случайной величины равно 3.80, дисперсия 5.25. Можно было ожидать, что эти значения будут равны первоначально заданной интенсивности, т.е. 5.
В результате моделирования всегда будут получаться значения, несколько отличающиеся от первоначально заданной интенсивности. Величина 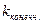 будет равна 12, поскольку существует одна минута, в течение которой произошло 12 событий, и не существует ни одной минуты, в течение которой произошло более 12 событий.
будет равна 12, поскольку существует одна минута, в течение которой произошло 12 событий, и не существует ни одной минуты, в течение которой произошло более 12 событий.
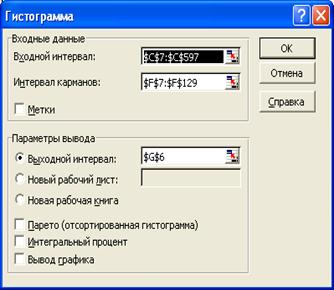
Рис.3.21 Решение задачи 3 в MS Excel (продолжение). Диалоговое окно надстройки «Пакет анализа», «Гистограмма».
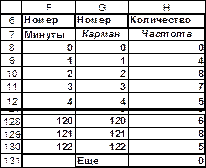
Рис.3.22. Решение задачи 3 в MS Excel в режиме отображения данных (продолжение).
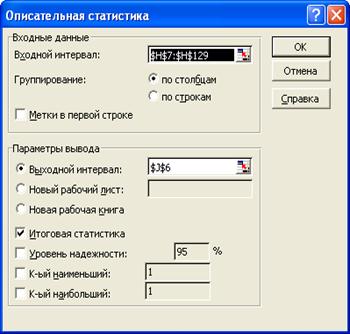
Рис.3.23 Решение задачи 3 в MS Excel. Диалоговое окно надстройки «Пакет анализа», «Описательная статистика»

Рис.3.24. Решение примера 1 в MS Excel в режиме отображения данных (продолжение).
Далее строим итоговую таблицу с искомыми экспериментальными и теоретическими частотами. (рис. 3.25-3.26). Для этого последовательно вычислим количество минут, в течение которых не было ни одного события (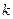 =0); затем вычислим количество минут, в течение которых было ровно одно событие ( =1) и т.д. Эти вычисления приведены в интервале ячеек N7:N19 на рис. 3.25-3.26. В интервале ячеек О7:Р19 содержатся теоретические значения вероятности и частот соответственно.
=0); затем вычислим количество минут, в течение которых было ровно одно событие ( =1) и т.д. Эти вычисления приведены в интервале ячеек N7:N19 на рис. 3.25-3.26. В интервале ячеек О7:Р19 содержатся теоретические значения вероятности и частот соответственно.
Соответствующие графики частот приведены на рис.3.28. Визуально анализируя их, можно придти к выводу, что общий характер теоретической и экспериментальной кривых совпадает. Для аналитической проверки совпадения полученного эмпирического распределения количества вызовов в единицу времени и теоретического распределения Пуассона для заданной интенсивности воспользуемся критерием согласия Пирсона.
Все расчеты приведены на (рис. 3.25-3.27). Для этого выдвигаем гипотезу H0: распределения эмпирических и теоретических частот совпадают (т.е. эмпирическое распределение является конкретной реализацией данного теоретического распределения). Альтернативная гипотеза H1: распределения эмпирических и теоретических частот не совпадают. Затем определим меру расхождения между фактическим распределением и предполагаемым теоретическим
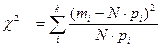 , (3.22)
, (3.22)
где k – количество разрядов, в которые сведены результаты опытов;; mi – количество наблюдений в i -том разряде; рi – теоретическая вероятность (в соответствии с предполагаемым законом распределения) i-го разряда.
Для корректности расчетов величины 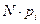 должны быть больше или равны 5. Если в некотором интервале это условие нарушается, то интервал объединяется с соседним, т.е. интервалы укрупняются. После укрупнения число интервалов k стало равно 9 (диапазон Q8:R16), а величина χ2 будет равна 8.95 (ячейка S20).
должны быть больше или равны 5. Если в некотором интервале это условие нарушается, то интервал объединяется с соседним, т.е. интервалы укрупняются. После укрупнения число интервалов k стало равно 9 (диапазон Q8:R16), а величина χ2 будет равна 8.95 (ячейка S20).
Далее определяется число степеней свободы r:
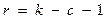 (3.23)
(3.23)
где: с – число параметров теоретического распределения. Для закона распределения Пуассона и показательного закона распределения с =1. Т.о. r=9-1-1=7.
По заданным значениям α=0.05 и r=9 с помощью специальной таблицы находим χ2крит.. Для этого используем встроенную функцию Excel ХИ2ОБР, которая имеет следующий формат:








