 2015-03-22
2015-03-22 714
714Для выбора управления u (t)в общем случае может использоваться любая доступная исследователю к моменту t информация. Способ формирования управляющих воздействий будем в дальнейшем обозначать U и называть стратегией, а его реализацию − законом управления.
В зависимости от того, какая информация используется для формирования управляющих воздействий, можно выделить три существенно различных типа стратегий.
I. Начнем с простейшего случая, когда управление u выбирается заранее сразу на весь отрезок времени Т и в процессе движения не корректируется. Такое управление называется программным, а соответствующие программные стратегии U = u представляют собой функции времени, которые в дальнейшем будем полагать кусочно-непрерывными. Совокупность таких функций, определенных на отрезке 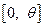 и удовлетворяющих ограничению (9.3), назовем множеством программных стратегий и обозначим Ut.
и удовлетворяющих ограничению (9.3), назовем множеством программных стратегий и обозначим Ut.
Необходимо отметить, что возможности использования программных управлений в рассматриваемых задачах весьма ограничены. В детерминированном случае движение объекта однозначно определяется начальной позицией (t 0, x 0) и выбранным управлением u, поэтому получение какой-либо дополнительной информации в процессе движения, в принципе не дает никакого выигрыша.
Присутствие факторов неопределенности или управление z резко уменьшает эффективность программных стратегий, так как управлять приходится уже не одной траекторией, исходящей из начальной точки (t 0, x 0), а расходящимся пучком траекторий Х (u) (рис. 9.3). Множество состояний x (t *), достигаемых в момент времени t *движениями х, исходящими из начальной точки х 0 при фиксированном управлении u и переборе всех допустимых возмущений z 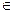 Z, называется областью достижимости системы и обозначается
Z, называется областью достижимости системы и обозначается
G (t *, t 0, x 0, u) = [ x (t*, t 0, x 0, u, z |z Z ].
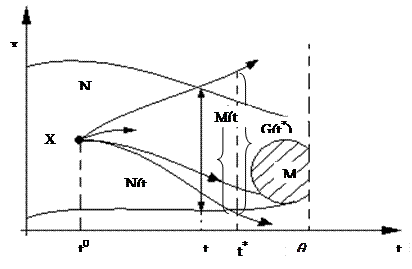
Рис. 9.3. Область допустимых отклонений
Область достижимости для множества возможных начальных позиций G 0 определяется как
G (t *, G 0, u) = [  G (t*, t 0, x 0, u |(t 0, x 0) G 0].
G (t*, t 0, x 0, u |(t 0, x 0) G 0].
При интенсивных возмущениях размеры области достижимости быстро увеличиваются со временем и через некоторое время могут стать больше «диаметра» области допустимых отклонений N (t) (рис. 9.3). Ясно, что при этом никакой выбор программного управления u не сможет обеспечить справедливость условия (9.4). Тем не менее, программные стратегии могут оказаться полезными для построения некоторых вспомогательных конструкций, поскольку работать с ними проще, чем с другими типами стратегий.
II. Рассмотрим теперь второй случай, когда в процессе движения непрерывно измеряется состояние объекта, так что в каждый момент времени известна сложившаяся позиция [ t, x (t)]. Позиционная стратегия U выбирает текущее значение управления в зависимости от сложившейся позиции, u (t) = U [ t, x (t)], иначе говоря, позиционное управление формируется по принципу обратной связи в зависимости от состояния объекта. Совокупность всех функций U | u (t) = U [ t, x (t)] P, t T, назовем множеством позиционных стратегий и будем обозначать U x.
III. При использовании позиционных стратегий, не стесненных никакими дополнительными ограничениями, следует иметь в виду одну существенную особенность. Если функция U [ t, x (t)] разрывна по х (именно такие функции чаще всего оказываются самыми эффективными), то в системе управления могут возникнуть так называемые скользящие режимы. При этом решение уравнения (9.2) в классическом смысле не существует.
Указанную трудность обходят следующим образом. Рассматривается дискретная система управления, в которой приближенно реализуется стратегия из класса U x. Измерение состояния объекта x и формирование управления u в такой системе производится лишь в дискретные моменты времени tk, задаваемые тактовым генератором с периодом Δ t = tk - tk- 1. Сформированное в момент tk управляющее воздействие uk сохраняется затем постоянным вплоть до следующего момента измерения tk+ 1:
u (t) = uk = U [ tk, x (tk)] при tk ≤ tk < tk+ 1.
Точность решения зависит от выбора периода дискретности Δ t.
Иногда удается измерять реализовавшееся в текущий момент времени возмущение z (t) (чаще всего лишь некоторые составляющие вектора z). При этом управляющее воздействие u (t) можно выбирать в зависимости от реализовавшегося возмущения. Соответствующую стратегию u (t) = U [ t, z (t)], будем называть контрстратегией или контруправлением, а множество таких стратегий обозначать U z. Такой принцип формирования управляющих воздействий давно используется в системах с компенсацией возмущений.
В зависимости от назначения рабочего механизма могут ставиться самые различные задачи управления. Наиболее распространены следующие режимы управления механизмами:
1) Рабочий механизм должен переместиться из одного положения в другое (позиционное перемещение).
2) Рабочий механизм должен за минимальное время разогнаться до заданной скорости или затормозиться.
3) Совершить заданную работу за минимальное время.
В том случае, когда можно пренебречь ограничением по нагреву, задачу оптимального управления можно сформулировать следующим образом: требуется отработать заданное перемещение (перейти от одной скорости к другой или совершить заданную работу) за минимальное время при наличии ограничений на ток якорной цепи, скорость и управляющие воздействия на цепи возбуждения генератора и двигателя.
При решении задачи оптимального по быстродействию управления с учетом нагрева двигателя можно потребовать, чтобы потери энергии в якорной цепи за время работы привода не превышали допустимых.
В этом случае задача может быть сформулирована следующим образом: требуется отработать заданное перемещение (перейти от одной скорости к другой или совершить заданную работу) за минимальное время при наличии ограничения на ток, скорость и управляющие воздействия при условии, что потери (или среднеквадратичный ток) за время работы привода не будут превышать заданного значения.








