 2015-03-27
2015-03-27 8692
8692По характеру представления и логической организации хранимой информации АИС разделяются на фактографические, документальные и геоинформационные.
Фактографические АИС накапливают и хранят данные в виде множества экземпляров одного или нескольких типов структурных элементов (информационных объектов). Каждый из таких экземпляров структурных элементов или некоторая их совокупность отражают сведения по какому-либо факту, событию и т. д., отделенному (вычлененному) от всех прочих сведений и фактов.
/Отсюда и название—«фактографические системы»/
Структура каждого типа информационного объекта состоит из конечного набора реквизитов, отражающих основные аспекты и характеристики сведений для объектов данной предметной области. К примеру, фактографическая АИС, накапливающая сведения по лицам, каждому конкретному лицу в базе данных ставит в соответствие запись, состоящую из определенного набора таких реквизитов, как фамилия, имя, отчество, год рождения, место работы, образование и т. д. Комплектование информационной базы в фактографических АИС включает, как правило, обязательный процесс структуризации входной информации из документального источника. Структуризация при этом осуществляется через определение (выделение, вычленение) экземпляров информационных объектов определенного типа, информация о которых имеется в документе, и заполнение их реквизитов.
Наиболее часто формализация представлений о предметной области осуществляется в рамках модели «объекты-связи» (так называемая ER-людель — от англ. Entity Relationship). При этом под информационным объектом в общем плане понимается некоторая сущность фрагмента действительности, например организация, документ, сотрудник, место, событие и т. д. В предметной области выделяются различные типы объектов, представляемые в информационной системе в каждый момент времени конечным набором экземпляров данного типа. Каждый тип объекта включает (идентифицируется) присущий ему набор атрибутов (свойств, характерных признаков, параметров). Атрибут представляет логически неделимый элемент структуры информации, характеризующийся множеством атомарных значений. Для примера можно привести атрибут «Имя» объекта типа «Лицо», который характеризуется множеством всех возможных имен, и атрибут «Текст» объекта типа «Документ», который характеризуется множеством средств смыслового выражения в определенном национальном языке.
Экземпляр объекта образуется совокупностью конкретных значений атрибутов данного типа объекта. Один или некоторая группа атрибутов объекта данного типа могут исполнять роль ключевого атрибута, по которому идентифицируются (различаются) конкретные экземпляры объектов. К примеру, для объектов типа «Лицо» ключом может являться совокупность атрибутов «Фамилия», «Имя», «Отчество» или один атрибут, выражающий номер паспорта (удостоверения личности).Различные типы объектов и различные экземпляры одного типа объекта могут быть охвачены определенными отношениями, которые в рамках ER-модели выражаются т. н. связями.
Так, например, объекты «Сотрудник» и «Организация» могут быть охвачены отношением «Работа», т. е. связаны этим отношением. При этом связи могут быть двух типов — иерархические, или, иначе говоря, структурные (владелец-подчиненный) и одноуровневые, например, родственная связь «Брат-сестра» между двумя экземплярами объекта типа «Лицо» (в отличие от иерархической родственной связи—«Отец-сын»). Объекты-владельцы иерархических связей-отношений иногда называют структурными объектами, в противовес простым объектам, которые таковыми не являются (не являются владельцами).
Структурные и одноуровневые связи (отношения), в свою очередь, по признаку множественности могут быть трех типов
— «один-к-одному» (например, отношение «Лицо-Паспорт», имея в виду под «Паспортом» не атрибут объекта Лицо, а самостоятельный объект, состоящий из атрибутов «Номер», «Вид паспорта», «Владелец», «Место выдачи», «Дата выдачи» и т. д.),
«один-ко-многим» (например, отношение «Подразделение-Сотрудник», имея в виду, что в одном подразделении может работать много сотрудников, но каждый сотрудник работает только в одном подразделении)
«многие-ко-многим» (например, отношение «Лицо-Документ», имея в виду, что один человек может быть автором, или иметь какое-либо другое отношение ко многим документам, и, в свою очередь, один документ может иметь много авторов.
Помимо этого информационные потребности абонентов информационной системы могут включать также и оперирование опосредованными (т. е. косвенными, непрямыми, ассоциативными) связями.
Примерами таких непрямых связей является совместная работа нескольких человек на одном предприятии (подразделении). Прямая непосредственная связь в данном случае, как правило, устанавливается только между объектами «Лицо» и «Организация», но не между различными экземплярами объекта «Лицо».Одним из способов представления формализованного описания предметной области информационной системы в рамках модели «объекты-связи» является использование техники специальных диаграмм, которая была предложена известным американским специалистом в области баз данных Ч. Бахманом. В диаграммах Бахмана объекты (сущности) представляются вершинами некоторого математического графа, а связи —дугами графа. Виды и свойства связей-отношений объектов отображаются направленностью, специальным оформлением дуг и расположением вершин графа.В качестве примера можно привести инфологическую схему предметной области сведений информационной системы, предназначенной для накопления данных о научной работе в каком-либо учебном или исследовательском учреждении (см. рис. 1.5).
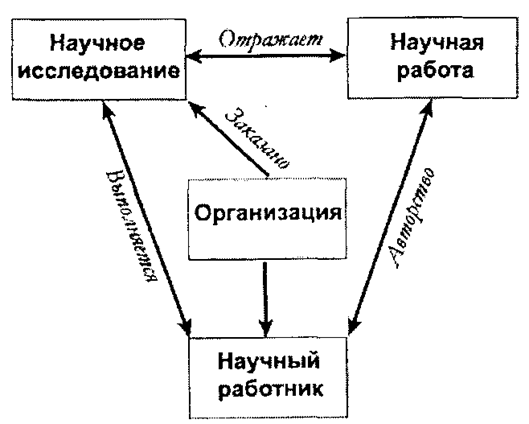
Рис. 1.5. Мифологическая схема предметной области информационной системы со сведениями о научной работе
На приведенном рисунке однонаправленность дуг означает структурность связи «владелец-подчиненный», двунаправленность дуг означает одноуровневые связи, двойные стрелки означают множественность отношения «один-ко-многим», двунаправленность двойных стрелок означает одноуровневые отношения «многие-ко-многим».
Одним из недостатков использования ER-диаграмм Бахмана для описания формализованных схем (моделей) предметных областей информационных систем является их статичность, не позволяющая наглядно и непосредственно отображать процессы, в которые вовлечены сущности и которым подвержены отношения (связи). Отчасти подобные проблемы преодолеваются введением дополнительных сущностей, выражающих собственно процессы и ситуации — событие, действие, момент времени. Аналогичным образом в некоторых случаях вводятся пространственные сущности для адекватного представления сущностей и отношений предметной области—маршрут, место, населенный пункт, здание, элемент здания, зона и т. д.
Вторым уровном представления информации в информационной системе (см. рис. 1.4) является схема базы дачных, (называемая еще логической структурой данных), представляющая описание средствами конкретной СУБД инфологической схемы предметной области (информационные объекты, реквизиты, связи).
Совокупность средств и способов реализации схемы базы данных в конкретной СУБД составляет модель организации данных.Схема базы данных содержит также ограничения целостности данных. Ограничения целостности представляют собой набор установок и правил по типам, диапазонам, соотношениям (и т. д.) значений атрибутов объектов, характеристик и особенностей связей между объектами. К примеру, диапазон значения атрибута «Дата рождения» объекта лицо не может выходить за рамки текущей даты, значение атрибута «Дата приобретения» объекта «Имущество» не может быть позднее значения атрибута «Дата продажи», значение атрибута «Количество» объекта «Материал» не должно быть меньше минимально необходимого на складе и т. п. Ограничения целостности данных лежат в основе контроля корректности информации при ее вводе в систему и периодического контроля наличия смысловых и других ошибок в базе данных после проведения операций добавления, удаления и изменения данных.Третий и самый «низкий» уровень представления информации в фактографических информационных системах выражается внутренней схемой базы данных, определяющей структуру организации и особенности хранения информационных массивов, в которых и находятся собственно сами данные (см. рис. 1.4).Более конкретные особенности представления и организации данных определяются конкретным типом и особенностями СУБД, используемой для создания фактографической информационной системы.Используемая литература: Н.А. Гайдамакин. Автоматизированные информационные системы, базы и банки данных.
Документальные информационные системы
Классические модели в теории БД изначально ориентированы на организацию хорошо структурированных данных, но чаще всего пользователь ИС работает со слабо структурированными данными, которые называют документами.
В отличие от фактографических информационно- поисковых систем для ДИПС необходимы свои системы управления, которые называют Системами Управления Документами. Основной функцией любой ДИПС является информационное обеспечение потребителей, на основе выдачи ответов на их запросы.
В развитии программного обеспечения СУБД в 70-е—80-е годы превалировало направление, связанное с фактографическими информационными системами, т. е. с системами, ориентированными на работу со структурированными данными. Были разработаны основы и модели организации фактографических данных, отработаны программно-технические решения по накоплению и физическому хранению таких данных, реализованы специальные языки запросов к базам данных и решен целый ряд других задач по эффективному управлению большими объемами структурированной информации. В результате основу информационного обеспечения деятельности предприятий и организаций к началу 90-х годов составили фактографические информационные системы, вобравшие в себя в совокупности колоссальный объем структурированных данных.
** В этом смысле очень характерным является рекламный девиз корпорации Oracle: «Мы храним триллионы бийт».
Вместе с тем создание и эксплуатация фактографических информационных систем требует либо изначально структурированных данных, таких, например, как отчеты датчиков в АСУ ТП, финансовые массивы бухгалтерских АИС и т. д., либо предварительной структуризации данных, как, например, в информационной системе кадрового подразделения, где все данные по сотрудникам структуризируются по ряду формализованных позиций. При этом зачастую структуризация данных требует больших накладных, в том числе и организационных расходов, что, в конечном счете, приводит к материальным издержкам информатизации. Кроме того, входные информационные потоки в целом ряде организационно-технологических и управленческих сфер представлены неструктурированными данными в виде служебных документов и иных текстовых источников. Извлечение из текстов данных по формализованным позициям для ввода в фактографические системы может приводить к ошибкам и потере части информации, которая в исходных источниках имеется, но в силу отсутствия в схеме базы данных адекватных элементов не может быть отражена в банке данных фактографических АИС. В результате, несмотря на интенсивное развитие и распространение фактографических информационных систем, огромная часть неструктурированных данных, необходимых для информационного обеспечения деятельности различных предприятий и организаций, остается в неавтоматизированном или слабо автоматизированном* виде.
К таким данным относятся огромные массивы различной периодики, нормативно-правовая база, массивы служебных документов делопроизводства и документооборота. * Представлена в электронном виде в текстовых файлах, но без средств систематизации, обработки, анализа и эффективного поиска
Потребности в системах, ориентированных на накопление и эффективную обработку неструктурированной или слабоструктурированной информации привели к возникновению еще в 70-х годах отдельной ветви программного обеспечения систем управления базами данных, на основе которых создаются документальные информационные системы. Однако теоретические исследования вопросов автоматизированного информационного поиска документов, начавшись еще в 50-х—60-х годах, к сожалению, не получили такой строгой, полной и в то же время технически реализуемой модели представления и обработки данных, как реляционная модель в фактографических системах. Не получили также стандартизации (как язык SQL) и многочисленные попытки создания универсальных так называемых информационно-поисковых языков, предназначенных для формализованного описания смыслового содержания документов и запросов по ним.
В итоге, несмотря на то, что первые системы автоматизированного информационного поиска документов появились еще в 60-х годах, развитые коммерческие информационно-поисковые системы, ориентированные на накопление и обработку текстовых документов, получили распространение лишь в конце 80-х — начале 90-х годов.
Напомним, что в фактографических информационных системах единичным элементом данных, имеющим отдельное смысловое значение, является запись, образуемая конечной совокупностью полей-атрибутов. Иначе говоря, информация о предметной области представлена набором одного или нескольких типов структурированных на отдельные поля записей. В отличие от фактографических информационных систем, единичным элементом данных в документальных информационных системах является неструктурированный на более мелкие элементы документ.
В качестве неструктурированных документов в подавляющем большинстве случаев выступают, прежде всего, текстовые документы, представленные в виде текстовых файлов, хотя к классу неструктурированных документированных данных могут также относиться звуковые и графические файлы. Основной задачей документальных информационных систем является накопление и предоставление пользователю документов, содержание, тематика, реквизиты и т. п. которых адекватны его информационным потребностям. Поэтому можно дать следующее определение документальной информационной системы — единое хранилище документов с инструментарием поиска и отбора необходимых документов.
Поисковый характер документальных информационных систем исторически определил еще одно их название — информационно-поисковые системы (ИПС), хотя этот термин не совсем полно отражает специфику документальных ИС. /Поиск информации (данных) осуществляется и в фактографических ИС./ Соответствие найденных документов информационным потребностям пользователя называется пертинентностью. В силу теоретических и практических сложностей с формализацией смыслового содержания документов пертинентность относится скорее к качественным понятиям, хотя может выражаться определенными количественными показателями. Таким образом термин ИПС определяет функциональное назначение ИС, но не отражает специфики представления и обработки данных.
Специфика документальных ИПС заключается в том, что они удовлетворяют информационные потребности пользователя, предоставляя ему документы, в которых содержится интересующая пользователя информация. В зависимости от особенностей реализации хранилища документов и механизмов поиска документальные ИПС можно разделить на две группы:
• системы на основе индексирования;
• семантически-навигационные системы.
В семантически-навигационных системах документы, помещаемые в хранилище (в базу) документов, оснащаются специальными навигационными конструкциями, соответствующими смысловым связям (отсылкам) между различными документами или отдельными фрагментами одного документа. Такие конструкции реализуют некоторую семантическую (смысловую) сеть в базе документов /Семантика (от греч. «semantikos»—обозначающий)—смысловая сторона языка, отдельных слов и частей слова, а также— раздел языкознания, изучающий значения слов. /
Способ и механизм выражения информационных потребностей в подобных системах заключаются в явной навигации пользователя по смысловым отсылкам между документами. В настоящее время такой подход реализуется в гипертекстовых ИПС. В системах на основе индексирования исходные документы помещаются в базу без какого-либо дополнительного преобразования, /За исключением возможного сжатия (архивирования)/ но при этом смысловое содержание каждого документа отображается в некоторое поисковое пространство. Процесс отображения документа в поисковое пространство называется индексированием и заключается в присвоении каждому документу некоторого индекса-координаты в поисковом пространстве. Формализованное представление (описание) индекса документа называется поисковым образом документа (ПОД). Пользователь выражает свои информационные потребности средствами и языком поискового пространства, формируя поисковый образ запроса (ПОЗ) к базе документов. Система на основе определенных критериев и способов ищет документы, поисковые образы которых соответствуют или близки поисковым образам запроса пользователя, и выдает соответствующие документы. Соответствие найденных документов запросу пользователя называется релевантностью. /На практике термин релевантность часто отождествляют с термином пертинентность, хотя в строгом отношении они различны. /
Схематично общий принцип устройства и функционирования документальных ИПС на основе индексирования иллюстрируется на рис. 6. 1.
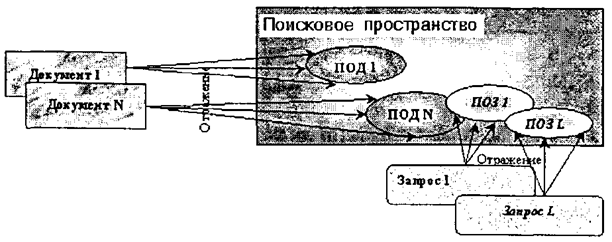
Рис. 6. 1. Общий принцип устройства и функционирования документальных ИПС на основе индексирования
Особенностью документальных ИПС является также то, что в их функции, как правило, включаются и задачи информационного оповещения пользователей по всем новым поступающим в систему документам, соответствующим заранее определенным информационным потребностям пользователя /Задачи информационного оповещения основаны на идеологии т. н. избирательного распространения информации (ИРИ), наработанной в библиотечном деле/
Принцип решения задач информационного оповещения в документальных ИПС на основе индексирования аналогичен принципу решения задач поиска документов по запросам и основан на отображении в поисковое пространство информационных потребностей пользователя в виде так называемых поисковых профилей пользователей (ППП). Информационно-поисковая система по мере поступления и индексирования новых документов сравнивает их образы с поисковыми профилями пользователей и принимает решение о соответствующем оповещении. Принцип решения задач информационного оповещения схематично иллюстрируется на рис. 6. 2.
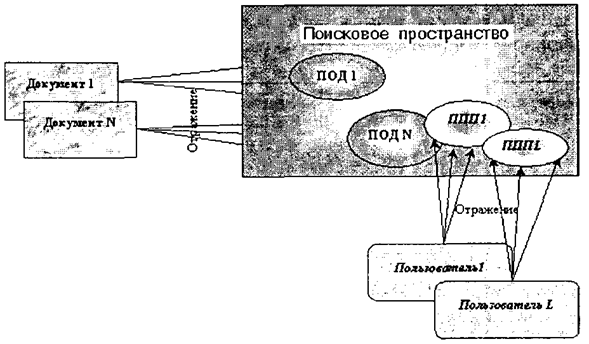
Рис.6.2. Принцип решения задач информационного оповещения в документальных ИПС на основе индексирования
Поисковое пространство, отображающее поисковые образы документов и реализующее механизмы информационного поиска документов так же, как и в СУБД фактографических систем, строится на основе языков документальных баз данных, называемых информационно-поисковыми языками (ИПЯ). Информационно-поисковый язык представляет собой некоторую формализованную семантическую систему, предназначенную для выражения содержания документа и запросов по поиску необходимых документов.
По аналогии с языками баз данных фактографических систем ИПЯ можно разделить на структурную и манипуляционную составляющие. Структурная составляющая ИПЯ (поискового пространства) документальных ИПС на основе индексирования реализуется индексными указателями в форме информационно-поисковых каталогов, тезаурусов и генеральных указателей. Информационно-поисковые каталоги являются традиционными технологиями организации информационного поиска в документальных фондах библиотек, архивов и представляют собой классификационную систему знаний по определенной предметной области.
Смысловое содержание документа в информационно-поисковых каталогах отображается тем или иным классом каталога, а индексирование документов заключается в присвоении каждому документу специального кода (индекса) соответствующего по содержанию класса (классов) каталога и создания на этой основе специального индексного указателя. Тезаурус представляет собой специальным образом организованную совокупность основных лексических единиц (понятий) предметной области (словарь терминов) и описание парадигматических отношений между ними. Парадигматические отношения выражаются семантическими отношениями между элементами словаря, не зависящими от любого контекста.
Независимость от контекста означает обобщенность (абстрагированность) смысловых отношений, например отношения «род-вид», «предмет-целое», «субъект-объект-средство-место-время действия». Так же, как и в информационно-поисковых каталогах, в системах на основе тезаурусов в информационно-поисковое пространство отображается не весь текст документа, а только лишь выраженное средствами тезауруса смысловое содержание документа.
Генеральный указатель* (глобальный словарь-индекс) в общем виде представляет собой перечисление всех слов (словоформ), имеющихся в документах хранилища, с указанием (отсылками) координатного местонахождения каждого слова (№ документа — № абзаца — № предложения — № слова). Индексирование нового документа в таких системах производится через дополнение координатных отсылок тех словоформ генерального указателя, которые присутствуют в новом документе.
Так как поисковое пространство в таких системах отражает полностью весь текст документа (все слова документа), а не только его смысловое содержание, то такие системы получили название полнотекстовых ИПС. В специальной литературе такие системы иногда называют системами без лексического контроля, т. е. без учета возможной синонимичности отдельных групп словоформ, объединения отдельных групп словоформ в общие смысловые группы, семантических отношении между словоформами.
Структурная составляющая ИПЯ семантически-навигационных систем реализуется в виде техники смысловых отсылок в текстах документов и специальном навигационном интерфейсе по ним и в настоящее время представлена гипертекстовыми технологиями. Поисковая (манипуляционная) составляющая ИПЯ реализуется дескрипторными и семантическими языками запросов. В дескрипторных языках документы и запросы представляются наборами некоторых лексических единиц (слов, словосочетаний, терминов) — дескрипторов, не имеющих между собой связей, или, как еще говорят, не имеющих грамматики. Таким образом, каждый документ или запрос ассоциируется или, лучше сказать, представлен некоторым набором дескрипторов. Поиск осуществляется через поиск документов с подходящим набором дескрипторов.
В качестве элементов-дескрипторов выступают либо элементы словаря ключевых терминов, либо элементы генерального указателя (глобального словаря всех словоформ). В силу отсутствия связей между дескрипторами, набор которых для конкретного документа и конкретного запроса выражает, соответственно, поисковый образ документа — ПОД или поисковый образ запроса ПОЗ, такие языки применяются, прежде всего, в полнотекстовых системах. Семантические языки содержат грамматические и семантические конструкции для выражения (описания) смыслового содержания документов и запросов.
Все многообразие семантических языков подразделяется на две большие группы:
• предикатные языки;
• реляционные языки.
В предикатных языках в качестве элементарной осмысленной конструкции высказывания выступает предикат, который представляет собой многоместное отношение некоторой совокупности грамматических элементов. Многоместность отношения означает, что каждый элемент предиката играет определенную роль для группы лексических элементов в целом, но не имеет конкретных отношений с каждым элементом этой группы в отдельности. Аналогом предикатного высказывания в естественном языке выступает предложение, констатирующее определенный факт или описывающее определенное событие. В реляционных языках лексические единицы высказываний могут вступать только в бинарные (друг с другом), но не в совместные, т. е. не многоместные отношения. В качестве лексических единиц семантических языков выступают функциональные классы естественного языка, важнейшими из которых являются:• понятия-классы (общее определение совокупности однородных элементов реального мира, обладающих некоторым характерным набором свойств, позволяющих одни понятия-классы отделять от других);• понятия-действия (лексический элемент, выражающий динамику реального мира, содержит универсальный набор признаков, включающий субъект действия, объект действия, время действия, место действия, инструмент действия, цель и т. д.);• понятия-состояния (лексические элементы, фиксирующие состояния объектов);• имена (лексические элементы, идентифицирующие понятия-классы);• отношения (лексические элементы, служащие для установления связей на множестве понятий и имен);• квантификаторы (всеобщности, существования и т. д.). Семантические языки составляют языково-манипуляционную основу информационно-поисковых каталогов, тезаурусов и семантически-навигационных (гипертекстовых) ИПС, описывая своими средствами собственно сами каталоги, тезаурусы, семантические сети и выражая смысловое содержание документов и запросов. В заключение общей характеристики документальных ИПС приведем основные показатели эффективности их функционирования. Такими показателями являются полнота и точность информационного поиска. Полнота информационного поиска R определяется отношением числа найденных пертинентных документов А к общему числу пертинентных документов С, имеющихся в системе или в исследуемой совокупности документов:R=A/C. Точность информационного поиска Р определяется отношением числа найденных пертинентных документов А к общему числу документов L, выданных на запрос пользователя:P=A/LНаличие среди отобранных на запрос пользователя нерелевантных документов называется информационным шумом системы. Коэффициент информационного шума, соответственно, определяется отношением числа нерелевантных документов (L–A), выданных в ответе пользователю к общему числу документов L, выданных на запрос пользователя: = В идеале полнота информационного поиска и точность информационного поиска должны приближаться к единице, хотя на практике их значения колеблются в пределах от 60 до 90%.
Используемая литература: Н. А. Гайдамакин. Автоматизированные информационные системы, базы и банки данных. Конспект лекций ИС
| Лекция № 3 | Тема 1.3 |

