 2015-04-12
2015-04-12 2583
2583Каждый каталог NTFS представляет собой один вход в таблицу MFT, который содержит атрибут Index Root. Индекс содержит список файлов, входящих в каталог. Индексы позволяют сортировать файлы для ускорения поиска, основанного на значении определенного атрибута. Обычно в файловых системах файлы сортируются по имени. NTFS позволяет использовать для сортировки любой атрибут, если он хранится в резидентной форме.
Имеются две формы хранения списка файлов.
Небольшие каталоги (small indexes). Если количество файлов в каталоге невелико, то список файлов может быть резидентным в записи в MFT, являющейся каталогом (рис. 7.24). Для резидентного хранения списка используется единственный атрибут — Index Root. Список файлов содержит значения атрибутов файла. По умолчанию — это имя файла, а также номер записи MTF, содержащей начальную запись файла.
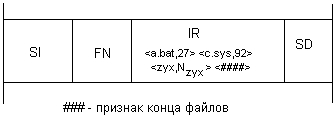
Рис. 7.24. Небольшой каталог
Большие каталоги (large indexes). По мере того как каталог растет, список файлов может потребовать нерезидентной формы хранения. Однако начальная часть списка всегда остается резидентной в корневой записи каталога в таблице MFT (рис. 7.25). Имена файлов резидентной части списка файлов являются узлами так называемого В-дерева (двоичного дерева). Остальные части списка файлов размещаются вне MFT. Для их поиска используется специальный атрибут Index Allocation, представляющий собой адреса отрезков, хранящих остальные части списка файлов каталога. Одни части списков являются листьями дерева, а другие являются промежуточными узлами, то есть содержат наряду с именами файлов атрибут Index Allocation, указывающий на списки файлов более низких уровней.
Узлы двоичного дерева делят весь список файлов на несколько групп. Имя каждого файла-узла является именем последнего файла в соответствующей группе. Считается, что имена файлов сравниваются лексикографически, то есть сначала принимаются во внимание коды первых символов двух сравниваемых имен, при этом имя считается меньшим, если код его первого символа имеет меньшее арифметическое значение, при равенстве кодов первых символов сравниваются коды вторых символов имен и т. д. Например, файл f 1.ехе, являющийся первым узлом двоичного дерева, показанного на рис. 7.25, имеет имя, лексикографически большее имен avia.exe, az.exe,..., emax.exe, образующих первую группу списка имен каталога. Соответственно файл ltr.exe имеет наибольшее имя среди всех имен второй группы, а все файлы с именами, большими ltr.exe, образуют третью и последнюю группу.
Поиск в каталоге уникального имени файла, которым в NTFS является номер основной записи о файле в MFT, по его символьному имени происходит следующим образом. Сначала искомое символьное имя сравнивается с именем первого узла в резидентной части индекса. Если искомое имя меньше, то это означает, что его нужно искать в первой нерезидентной группе, для чего из атрибута Index Allocation извлекается адрес отрезка (VCNj, LCN^ K!), хранящего имена файлов первой группы. Среди имен этой группы поиск осуществляется прямым перебором имен и сравнением до полного совпадения всех символов искомого имени с хранящимся в каталоге именем. При совпадении из каталога извлекается номер основной записи о файле в MFT и остальные характеристики файла берутся уже оттуда.
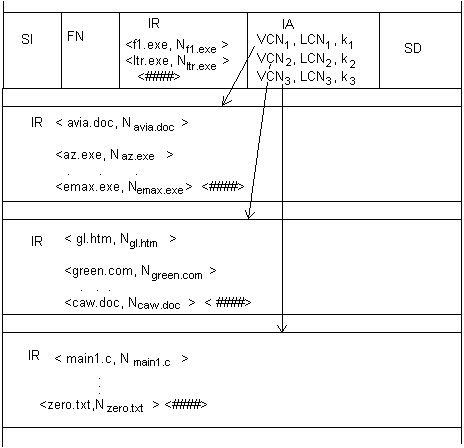
Рис. 7.25. Большой каталог
Если же искомое имя больше имени первого узла резидентной части индекса, то его сравнивают с именем второго узла, и если искомое имя меньше, то описанная процедура применяется ко второй нерезидентной группе имен, и т. д.
В результате вместо перебора большого количества имен (в худшем случае — всех имен каталога) выполняется сравнение с гораздо меньшим количеством имен узлов и имен в одной из групп каталога.
Если одна из групп каталога становится слишком большой, то ее также делят на группы, последние имена каждой новой группы оставляют в исходном нерезидентном атрибуте Index Root, а все остальные имена новых групп переносят в новые нерезидентные атрибуты типа Index Root (на рисунке этот случай не показан). К исходному нерезидентному атрибуту Index Root добавляется атрибут размещения индекса, указывающий на отрезки индекса новых групп. Если теперь при поиске искомого имени в нерезидентной части индекса первого уровня какое-либо сравнение показывает, что искомое имя оказывается меньше, чем одно из хранящихся там имен, то это говорит о том, что в данном атрибуте точного сравнения имени уже быть не может и нужно перейти к подгруппе имен следующего уровня дерева.
Файловые операции
Два способа организации файловых операций
Файловая система ОС должна предоставлять пользователям набор операций работы с файлами, оформленный в виде системных вызовов. Этот набор обычно состоит из таких системных вызовов, как creat (создать файл), read (читать из файла), write (записать в файл) и некоторых других.
Чаще всего с одним и тем же файлом пользователь выполняет не одну операцию, а последовательность операций. Например, при работе текстового редактора с файлом, в котором содержится некоторый документ, пользователь обычно считывает несколько страниц текста, редактирует эти данные и записывает их на место считанных, а затем считывает страницы из другой области файла, и т. п. После большого количества операций чтения и записи пользователь завершает работу с данным файлом и переходит к другому.
Какие бы операции не выполнялись над файлом, ОС необходимо выполнить ряд универсальных для всех операций действий:
1. По символьному имени файла найти его характеристики, которые хранятся в файловой системе на диске.
2. Скопировать характеристики файла в оперативную память, так как только таким образом программный код может их использовать.
3. На основании характеристик файла проверить права пользователя на выполнение запрошенной операции (чтение, запись, удаление, просмотр атрибутов файла).
4. Очистить область памяти, отведенную под временное хранение характеристик файла.
Кроме того, каждая операция включает ряд уникальных для нее действий, например чтение определенного набора кластеров диска, удаление файла и т. п.
Операционная система может выполнять последовательность действий над файлом двумя способами (рис. 7.26):
- Для каждой операции выполняются как универсальные, так и уникальные действия. Такая схема иногда называется схемой без запоминания состояния операций (stateless).
- Все универсальные действия выполняются в начале и конце последовательности операций, а для каждой промежуточной операции выполняются только уникальные действия.
Подавляющее большинство файловых систем поддерживает второй способ организации файловых операций как более экономичный и быстрый. Первый способ обладает одним преимуществом — он более устойчив к сбоям в работе системы, так как каждая операция является самодостаточной и не зависит от результата предыдущей. Поэтому первый способ иногда применяется в распределенных сетевых файловых системах (например, в Network File System, NFS компании Sun), когда сбои из-за потерь пакетов или отказов одного из сетевых узлов более вероятны, чем при локальном доступе к файлам.
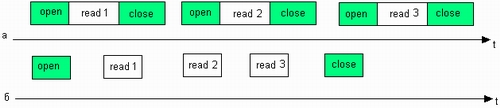
Рис. 7.26. Два способа выполнения файловых операций
При втором способе в файловой системе вводятся два специальных системных вызова: open — открытие файла, и close — закрытие файла.
Системный вызов открытия файла open выполняется перед началом любой последовательности операций с файлом, а вызов закрытия файла close — после окончания работы с файлом. Основной задачей вызова open является преобразование символьного имени файла в его уникальное числовое имя, копирование характеристик файла из дисковой области в буфер оперативной памяти и проверка прав пользователя на выполнение запрошенной операции. Вызов close освобождает буфер с характеристиками файла и делает невозможным продолжение операций с файлом без его повторного открытия.
Операции открытия и закрытия файла в той или иной форме утвердились в операционных системах очень давно. Даже в такой «старой» операционной системе, как OS/360, существовала макрокоманда OPEN, по которой в специальном буфере, называемом DCB (Data Control Block), собирались из различных источников все нужные характеристики набора данных (понятие, близкое к современному понятию файла), используемые затем при выполнении операций чтения и записи.
Далее основные системные вызовы файловых операций рассматриваются более детально на примере их реализации в ОС UNIX, в которой они приобрели тот вид, который сегодня поддерживается практически всеми операционными системами.
Открытие файла
Системный вызов open в ОС UNIX работает с двумя аргументами: символьным именем открываемого файла и режимом открытия файла. Режим открытия говорит системе, какие операции будут выполняться над файлом в последовательности операций до закрытия файла по системному вызову close, например: только чтение, только запись или чтение и запись.
При открытии файла ОС сначала выполняет преобразование первого аргумента системного вызова, то есть символьного имени файла, в его уникальное числовое имя, которым в традиционных файловых системах UNIX является номер индексного дескриптора. Эта процедура была рассмотрена выше при описании файловой системы s5.
По номеру индексного дескриптора inode файловая система находит нужную запись на диске и копирует из нее характеристики файла в оперативную память.
Для хранения копии индексного дескриптора используются буферные области системного виртуального пространства. Характеристики индексного дескриптора, перенесенные в оперативную память, помещаются в структуру так называемого виртуального дескриптора vnode (virtual node). Структура vnode включает поля индексного дескриптора файла inode, а также несколько перечисленных ниже дополнительных полей, полезных при выполнении операций с файлом.
- Состояние индексного дескриптора в памяти, отражающее:
· заблокирован ли файл;
· ждет ли снятия блокировки с файла какой-либо процесс;
· отличается ли представление характеристик файла в памяти от своей дисковой копии в результате изменения содержимого индексного дескриптора;
· отличается ли представление файла в памяти от своей дисковой копии в результате изменения содержимого файла;
· является ли файл точкой монтирования.
- Логический номер устройства файловой системы, содержащей файл.
- Номер индексного дескриптора. В дисковом индексном дескрипторе это поле отсутствует, так как номер определяется положением дескриптора относительно начала области индексных дескрипторов.
- Счетчик ссылок на данную структуру vnode.
С одним и тем же файлом в какой-то период времени могут работать различные процессы, но операционная система не создает для каждого процесса отдельную копию структуры vnode, а для каждого файла, с которым в данный момент работает хотя бы один процесс, хранит ровно одну копию виртуального дескриптора. При очередном открытии файла ОС проверяет, имеется ли в системной памяти структура vnode открываемого файла (по номеру логического устройства и номеру индексного дескриптора, которые определяются при преобразовании символьного имени), и если имеется, то счетчик ссылок на нее увеличивается на единицу. При очередном закрытии этого файла счетчик ссылок уменьшается на единицу, и если он становится равным О, то буфер, хранящий данный vnode, считается свободным.
Использование единственной копии характеристик файла и некоторых характеристик файловых операций (например, признака блокировки), общих для всех работающих с файлом процессов, экономит системную память. Тем не менее существуют характеристики, индивидуальные для каждого процесса, выполняющего некоторую последовательность операций с определенным файлом. Для их хранения в UNIX используется структура типа file, которая так же, как и vnode, хранится в системной области памяти.
При каждом открытии процессом файла ОС проверяет права пользовательского процесса на выполнение запрошенной операции с файлом и, если проверка прошла успешно, создает в системной области памяти новую структуру f i I e, которая описывает как открытый файл, так и операции, которые процесс собирается производить с файлом (например, чтение).
Структура file содержит такие поля, как:
- признак режима открытия (только для чтения, для чтения и записи и т. п.);
- указатель на структуру vnode;
- текущее смещение в файле (переменная offset) при операциях чтения/записи; О счетчик ссылок на данную структуру;
- указатель на структуру, содержащую права процесса, открывшего файл (эта структура находится в дескрипторе процесса);
- указатели на предыдущую и последующую структуры file, связывающие все такие структуры в двойной список.
Переменная offset, хранящаяся в структуре file, позволяет ОС запоминать текущее положение условного указателя в последовательности байт файла. При открытии файла эта переменная указывает на начальный или конечный байт файла в зависимости от заданного режима открытия. После выполнения операций чтения или записи указатель сдвигается на то количество байт, которое было прочитано или записано в результате операции. Следующая операция застает указатель в том состоянии, в котором его оставила предыдущая операция. Прикладной программист может явно управлять положением указателя с помощью системного вызова lseek, который будет рассмотрен ниже.
При каждом новом открытии какого-либо файла ОС создает новую структуру file и помещает ее в дважды связанный список (рис. 7.27). Обычно под хранение структур file в системной области отводится ограниченная область, поэтому общее количество открытых файлов всеми процессами в любой момент ограничено.
После создания структуры file операционная система помещает указатель на нее в таблицу открытых файлов процесса, которая находится в контексте процесса. Если процесс несколько раз открывает один и тот же файл, то структура file создается для каждой операции открытия. Так как контекст процесса-родителя в UNIX наследуется процессом-потомком, то потомок наследует и указатели на все открытые родителем файлы, получая возможность выполнять над ними операции.
Системный вызов open возвращает в пользовательский процесс дескриптор файла, который представляет собой номер записи в таблице открытых файлов процесса. Дескриптор файла имеет локальное значение только для того процесса, который открыл файл, для разных процессов одно и то же значение дескриптора указывает на разные операции, в общем случае над разными файлами.
После открытия файла его дескриптор используется во всех дальнейших операциях с файлом вплоть до явного закрытия файла. Таким образом, дескриптор файла является временным уникальным именем, но не файла, а определенной последовательности операций с этим файлом.
Для открытия файла /bin/prog1.ехе в режиме «только для чтения» прикладной программист может использовать следующее выражение на языке С:
fd =open("'/bin/progl.exe". 0_RDONLY):
Здесь fd — это целочисленная переменная, сохраняющая значение дескриптора открытого файла. Ее значение должно использоваться в операциях обмена данными с файлом /bin/prog1.exe. При неудачной попытке открытия файла (нет прав для выполнения затребованной операции, неверное имя файла) переменной fd присваивается значение -1, которое является индикатором ошибки для всех системных вызовов UNIX.
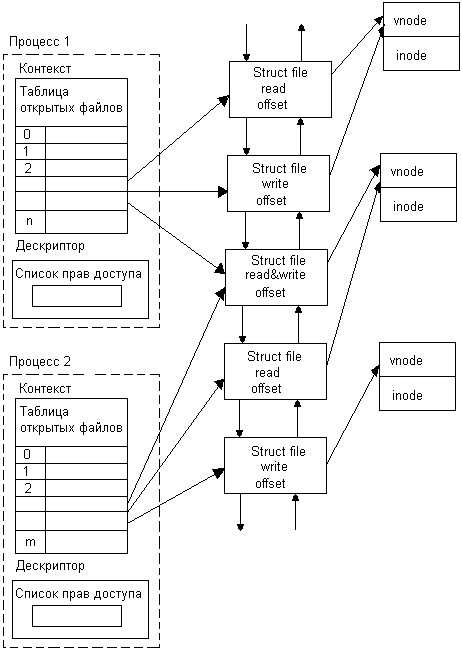
Рис. 7.27. Связь процесса с открытыми файлами
Обмен данными с файлом
Для обмена данными с предварительно открытым файлом в ОС UNIX существуют системные вызовы read и write. В том случае, когда необходимо явным образом указать, с какого байта файла необходимо читать или записывать данные, используется также системный вызов lseek.
Системный вызов чтения данных из файла read имеет три аргумента:
read(fd,buffer,nbytes);
Первый аргумент fd является целочисленной переменной, имеющей значение дескриптора открытого файла. Второй аргумент buffer является указателем на область пользовательской памяти, в которую система должна поместить считанные данные. Количество байт этой области памяти задается третьим целочисленным аргументом nbytes. Функция read возвращает действительное количество считанных байт (оно может отличаться от заданного, если, например, была задана область чтения, выходящая за пределы файла) или же код ошибки -1.
Начало дисковой области, которую нужно прочитать с помощью вызова read, явно в этом системном вызове не указывается. Чтение начинается с того байта, на который указывает смещение offset в структуре file. На это смещение указывает запись с номером fd в таблице открытых файлов процесса. После выполнения вызова read смещение offset наращивается на количество прочитанных байт.
Вид системного вызова записи данных write аналогичен вызову read:
write(fd.buffer.nbytes):
Функция write записывает nbytes из буфера оперативной памяти buffer в файл, описываемый дескриптором fd. Функция write, так же как и read, возвращает вызвавшей ее программе значение реально переданных ею байт или код ошибки.
Рассмотрим пример, в котором прикладная программа работает с файлом, состоящем из записей фиксированной длины в 50 байт:
fd =open("/doc/qwery/basel2.txt". 0_RDWR):
readCfd.bufferl.50):
read(fd.buffer2.2500):
lseekCfd,150.0): write (fd.output. 300):
close(fd):
В приведенном фрагменте программы после открытия файла /doc/query/base12.txt для чтения и записи выполняется чтение первой записи файла, а затем читается область файла, включающая еще 50 записей, начиная со 2 по 51. После обработки считанных записей (эти инструкции опущены) производятся перемещение указателя смещения в файле на начало четвертой записи и запись результатов в шесть последовательных записей, начиная с четвертой. Завершается фрагмент закрытием файла с помощью системного вызова close.
Все описанные системные вызовы являются синхронными, то есть пользовательский процесс переводится в состояние ожидания до тех пор, пока операция ввода-вывода не завершится.
Описанный набор системных вызовов, появившийся в ОС UNIX еще в 70-х годах, стал стандартом де-факто для современных операционных систем. Эти традиционные системные вызовы часто в конкретных ОС дополняются оригинальными системными вызовами ввода-вывода, например операциями асинхронного типа. На основе системных вызовов ввода-вывода обычно строятся более мощные библиотечные функции ввода-вывода, составляющие прикладной интерфейс ОС.
Блокировки файлов
Блокировки файлов и отдельных записей в файлах являются средством синхронизации между работающими в кооперации процессами, пытающимися использовать один и тот же файл одновременно.
Процессы могут иметь соответствующие права доступа к файлу, но одновременное использование этих прав (в особенности права записи) может привести к некорректным результатам. Примером такой ситуации является одновременное редактирование одного и того же документа несколькими пользователями. Если доступ к файлу не управляется блокировками, то каждый пользователь, который имеет право записи в файл, работает со своей копией данных файла. Результат такого редактирования непредсказуем — он зависит от того, в какой последовательности записывали изменения в файл применяемые пользователями приложения-редакторы.
Многопользовательские операционные системы обычно поддерживают специальный системный вызов, позволяющий программисту установить и проверить блокировки на файл и его отдельные области. В UNIX такой системный вызов называется fcntl. В его аргументах указывается дескриптор файла, для которого нужно установить или проверить блокировки, тип операции (блокирование или проверка, блокирование доступа для чтения или для записи), а также область блокирования — смещение от начала файла и размер в байтах.
При проверке наличия блокировок, установленных другими процессами, вызов fcntl немедленно возвращает управление с сообщением результата. При установке блокировки можно задать два режима работы системного вызова: с переходом процесса в состояние ожидания в том случае, если блокировку установить невозможно (синхронный системный вызов), и с немедленным возвратом в такой ситуации с сообщением отрицательного результата (асинхронный вызов).
Запрошенная блокировка записи не может быть установлена в том случае, если другой процесс уже установил свою блокировку записи на тот же файл. То есть блокировка записи является исключительной. Блокировки чтения не являются исключительными и могут устанавливаться на файл в том случае, если их области действия не перекрываются. Если на какую-то область файла установлена блокировка чтения, то на эту область нельзя установить блокировку записи.
В UNIX существуют два режима действия блокировок — консультативный (advisory) и обязательный (mandatory). Основным рекомендуемым для использования режимом является консультативный. При нем операционная система не занимается блокированием операций с файлом, а только устанавливает признаки блокирования областей в структурах file, поддерживающих операции с файлами. Кооперирующиеся процессы обязательно должны проверять наличие блокировок на файл, чтобы синхронизировать свою работу. Если же блокировки установлены, но процесс не проверяет их, то операционная система не запрещает доступ процесса к файлу, когда процесс делает системные вызовы read или write.
В обязательном режиме запрет на выполнение операции с заблокированным файлом поддерживает операционная система, поэтому процесс в любом случае не получит доступа к такому файлу. Однако при работе в этом режиме операционная система тратит много усилий и времени на его поддержание, поэтому обычно он не рекомендуется.
Стандартные файлы ввода и вывода, перенаправление вывода
В ОС UNIX были введены в свое время такие понятия, как «стандартный файл ввода», «стандартный файл вывода» и «стандартный файл ошибок». Эти три уже открытых файла существуют у любого пользовательского процесса с момента его возникновения. Процесс в любое время может организовать ввод данных из стандартного файла ввода, выполнив следующий системный вызов:
read(stdio. bufer. nbytes);
Здесь stdio — предопределенное имя константы, обозначающей дескриптор стандартного файла ввода.
Аналогично, так как stdout — предопределенное имя дескриптора стандартного файла вывода, процесс может вывести данные в стандартный файл вывода, применив следующий системный вызов:
write(stout. buffer, nbytes):
За стандартным файлом ошибок закреплено имя stderr.
Фактически при создании нового процесса ОС помещает в его таблицу открытых файлов три записи: с номером 0 — для стандартного файла ввода (следовательно, stdin всегда имеет значение 0), с номером 1 — для стандартного файла вывода (stdout=l), и с номером 2 — для стандартного файла ошибок (stderr=2). Соответственно создаются и три структуры типа file, на которые указывают первые три записи таблицы открытых файлов процесса.
В начальный период существования процесса эти три структуры file связываются операционной системой с одним файлом. В качестве этого файла выступает специальный файл — терминал, с которого вошел в систему пользователь. Такое назначение стандартных файлов достаточно естественно. Прикладные программы, запускаемые пользователем в ходе сеанса работы, чаще всего выводят результаты и сообщения об ошибках на экран терминала, за которым работает пользователь, и с клавиатуры этого же терминала считывают команды и другие исходные данные.
Модель стандартных файлов ввода-вывода рассчитана в основном на алфавитно-цифровые терминалы, управление которыми хорошо описывается потоком выводимых байт, который отображается в виде строк символов на экране, а также потоком вводимых байт, порождаемым последовательными нажатиями клавиш.
Наиболее известной программой, широко использующей стандартные файлы ввода-вывода, является интерпретатор команд, называемый также оболочкой (shell) операционной системы. Интерпретатор постоянно читает вводимые пользователем с клавиатуры команды (из стандартного файла ввода) и либо выполняет их самостоятельно, с помощью своих внутренних функций (такие команды называются внутренними), либо интерпретирует команду как имя исполняемого файла на диске, который необходимо запустить на выполнение в качестве отдельного процесса (внешние команды). Сообщения интерпретатор выводит на экран терминала — стандартный файл вывода.
Стандартные файлы ввода и ввода широко используются не только интерпретатором команд; но и самими командами. Многие внутренние и внешние команды устроены так, что они либо читают свои исходные данные из стандартного файла ввода, либо выводят результаты в стандартный файл вывода. Если же команда делает то и другое, она называется фильтром.
Рассмотрим несколько примеров команд UNIX, работающих со стандартными файлами ввода и вывода:
- ls dir2 — читает записи каталога dir2 и выводит их в определенном символьном формате в стандартный файл вывода;
- we — фильтр, который читает последовательность байт из стандартного файла ввода, подсчитывает число слов, строк или символов в считанных данных и выводит результат в стандартный файл вывода;
- who — выводит в стандартный файл информацию о пользователях, работающих в системе.
Интерпретатор команд выполняет также такую важную функцию, как перенаправление стандартного ввода и вывода. Под этим понимается замена файла-терминала, используемого по умолчанию в качестве стандартных файлов ввода и вывода, на произвольный файл. Механизм перенаправления основан на том, что приложение не знает, какой именно файл является стандартным, а просто использует определенный дескриптор в качестве указателя на этот файл. Поэтому для перенаправления ввода-вывода достаточно создать процесс выполнения команды с нестандартной связью стандартной записи в таблице открытых файлов.
Перенаправление осуществляется с помощью специальных конструкций командного языка. Для указания интерпретатору о необходимости перенаправить стандартный ввод на файл file используется следующая конструкция:
< file
Для перенаправления стандартного вывода требуется следующая конструкция:
> file
Например, показанная ниже командная строка запишет данные о содержимом каталога dir2 в файл a.txt:
ls dir2 > a.txt
Механизм перенаправления ввода-вывода, введенный ОС UNIX, получил широкое распространение в интерпретаторах команд многих операционных систем, например MS-DOS, Windows, OS/2.
Контроль доступа к файлам
Доступ к файлам как частный случай доступа к разделяемым ресурсам
Файлы — это частный, хотя и самый популярный, вид разделяемых ресурсов, доступ к которым операционная система должна контролировать. Существуют и другие виды ресурсов, с которыми пользователи работают в режиме совместного использования. Прежде всего это различные внешние устройства: принтеры, модемы, графопостроители и т. п. Область памяти, используемая для обмена данными между процессами, также является примером разделяемого ресурса. Да и сами процессы в некоторых случаях выступают в этой роли, например, когда пользователи ОС посылают процессам сигналы, на которые процесс должен реагировать.
Во всех этих случаях действует общая схема: пользователи пытаются выполнить с разделяемым ресурсом определенные операции, а ОС должна решать, имеют ли пользователи на это право. Пользователи являются субъектами доступа, а разделяемые ресурсы — объектами. Пользователь осуществляет доступ к объектам операционной системы не непосредственно, а с помощью прикладных процессов, которые запускаются от его имени. Для каждого типа объектов существует набор операций, которые с ними можно выполнять. Например, для файлов это операции чтения, записи, удаления, выполнения; для принтера — перезапуск, очистка очереди документов, приостановка печати документа и т. д. Система контроля доступа ОС должна предоставлять средства для задания прав пользователей по отношению к объектам дифференцированно по операциям, например, пользователю может быть разрешена операция чтения и выполнения файла, а операция удаления — запрещена.
Во многих операционных системах реализованы механизмы, которые позволяют управлять доступом к объектам различного типа с единых позиций. Так, представление устройств ввода-вывода в виде специальных файлов в операционных системах UNIX является примером такого подхода: в этом случае при доступе к устройствам используются те же атрибуты безопасности и алгоритмы, что и при доступе к обычным файлам и каталогам. Еще дальше продвинулась в этом направлении операционная система Windows NT. В ней используется унифицированная структура — объект безопасности, — которая создается не только для файлов и внешних устройств, но и для любых разделяемых ресурсов: секций памяти, синхронизирующих примитивов типа семафоров и мьютексов и т. п. Это позволяет использовать в Windows NT для контроля доступа к ресурсам любого вида общий модуль ядра — менеджер безопасности.
В качестве субъектов доступа могут выступать как отдельные пользователи, так и группы пользователей. Определение индивидуальных прав доступа для каждого пользователя позволяет максимально гибко задать политику расходования разделяемых ресурсов в вычислительной системе. Однако этот способ приводит в больших системах к чрезмерной загрузке администратора рутинной работой по повторению одних и тех же операций для пользователей с одинаковыми правами. Объединение таких пользователей в группу и задание прав доступа в целом для группы является одним из основных приемов администрирования в больших системах.
У каждого объекта доступа существует владелец. Владельцем может быть как отдельный-' пользователь, так и группа пользователей. Владелец объекта имеет право выполнять с ним любые допустимые для данного объекта операции. Во многих операционных системах существует особый пользователь (superuser, root, administrator), который имеет все права по отношению к любым объектам системы, не обязательно являясь их владельцем. Под таким именем работает администратор системы, которому необходим полный доступ ко всем файлам и устройствам для управления политикой доступа.
Различают два основных подхода к определению прав доступа.
- Избирательный доступ имеет место, когда для каждого объекта сам владелец может определить допустимые операции с объектами. Этот подход называется также произвольным (от discretionary — предоставленный на собственное усмотрение) доступом, так как позволяет администратору и владельцам объектов определить права доступа произвольным образом, по их желанию. Между пользователями и группами пользователей в системах с избирательным доступом нет жестких иерархических взаимоотношений, то есть взаимоотношений, которые определены по умолчанию и которые нельзя изменить. Исключение делается только для администратора, по умолчанию наделяемого всеми правами.
- Мандатный доступ (от mandatory — обязательный, принудительный) — это такой подход к определению прав доступа, при котором система наделяет пользователя определенными правами по отношению к каждому разделяемому ресурсу (в данном случае файлу) в зависимости от того, к какой группе пользователь отнесен. От имени системы выступает администратор, а владельцы объектов лишены возможности управлять доступом к ним по своему усмотрению. Все группы пользователей в такой системе образуют строгую иерархию, причем каждая группа пользуется всеми правами группы более низкого уровня иерархии, к которым добавляются права данного уровня. Членам какой-либо группы не разрешается предоставлять свои права членам групп более низких уровней иерархии. Мандатный способ доступа близок к схемам, применяемым для доступа к секретным документам: пользователь может входить в одну из групп, отличающихся правом на доступ к документам с соответствующим грифом секретности, например «для служебного пользования», «секретно», «совершенно секретно» и «государственная тайна». При этом пользователи группы «совершенно секретно» имеют право работать с документами «секретно» и «для служебного пользования», так как эти виды доступа разрешены для более низких в иерархии групп. Однако сами пользователи не распоряжаются правами доступа — этой возможностью наделен только особый чиновник учреждения.
Мандатные системы доступа считаются более надежными, но менее гибкими, обычно они применяются в специализированных вычислительных системах с повышенными требованиями к защите информации. В универсальных системах используются, как правило, избирательные методы доступа, о которых и будет идти речь ниже.
Для определенности будем далее рассматривать механизмы контроля доступа к таким объектам, как файлы и каталоги, но необходимо понимать, что эти же механизмы могут использоваться в современных операционных системах для контроля доступа к объектам любого типа и отличия заключаются лишь в наборе операций, характерных для того или иного класса объектов.
Механизм контроля доступа
Каждый пользователь и каждая группа пользователей обычно имеют символьное имя, а также уникальный числовой идентификатор. При выполнении процедуры логического входа в систему пользователь сообщает свое символьное имя и пароль, а операционная система определяет соответствующие числовые идентификаторы пользователя и групп, в которые он входит. Вся идентификационные данные, в том числе имена и идентификаторы пользователей и групп, пароли пользователей, а также сведения о вхождении пользователя в группы хранятся в специальном файле (файл /etc/passwd в UNIX) или специальной базе данных (в Windows NT).
Вход пользователя в систему порождает процесс-оболочку, который поддерживает диалог с пользователем и запускает для него другие процессы. Процесс-оболочка получает от пользователя символьное имя и пароль и находит по ним числовые идентификаторы пользователя и его групп. Эти идентификаторы связываются с каждым процессом, запущенным оболочкой для данного пользователя. Говорят, что процесс выступает от имени данного пользователя и данных групп пользователей. В наиболее типичном случае любой порождаемый процесс наследует идентификаторы пользователя и групп от процесса родителя.
Определить права доступа к ресурсу — значит определить для каждого пользователя набор операций, которые ему разрешено применять к данному ресурсу. В разных операционных системах для одних и тех же типов ресурсов может быть определен свой список дифференцируемых операций доступа. Для файловых объектов этот список может включать следующие операции:
- создание файла;
- уничтожение файла;
- открытие файла;
- закрытие файла;
- чтение файла;
- запись в файл;
- дополнение файла;
- поиск в файле;
- получение атрибутов файла;
- установка новых значений атрибутов;
- переименование;
- выполнение файла;
- чтение каталога;
- смена владельца;
- изменение прав доступа.
Набор файловых операций ОС может состоять из большого количества элементарных операций, а может включать всего несколько укрупненных операций. Приведенный выше список является примером первого подхода, который позволяет весьма тонко управлять правами доступа пользователей, но создает значительную нагрузку на администратора. Пример укрупненного подхода демонстрируют операционные системы семейства UNIX, в которых существуют всего три операции с файлами и каталогами: читать (read, г), писать (write, w) и выполнить (execute, x). Хотя в UNIX для операций используется всего три названия, в действительности им соответствует гораздо больше операций. Например, содержание операции выполнить зависит от того, к какому объекту она применяется. Если операция выполнить файл интуитивно понятна, то операция выполнить каталог интерпретируется как поиск в каталоге определенной записи. Поэтому администратор UNIX, по сути, располагает большим списком операций, чем это кажется на первый взгляд.
В ОС Windows NT разработчики применили гибкий подход — они реализовали возможность работы с операциями над файлами на двух уровнях: по умолчанию администратор работает на укрупненном уровне (уровень стандартных операций), а при желании может перейти на элементарный уровень (уровень индивидуальных операций).
В самом общем случае права доступа могут быть описаны матрицей прав доступа, в которой столбцы соответствуют всем файлам системы, строки — всем пользователям, а на пересечении строк и столбцов указываются разрешенные операции (рис. 7.28).
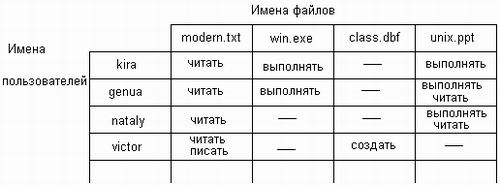
Рис. 7.28. Матрица прав доступа
Практически во всех операционных системах матрица прав доступа хранится «по частям», то есть для каждого файла или каталога создается так называемый список управления доступом (Access Control List, ACL), в котором описываются права на выполнение операций пользователей и групп пользователей по отношению к этому файлу или каталогу. Список управления доступа является частью характеристик файла или каталога и хранится на диске в соответствующей области, например в индексном дескрипторе inode файловой системы ufs. He все файловые системы поддерживают списки управления доступом, например, его не поддерживает файловая система FAT, так как она разрабатывалась для однопользовательской однопрограммной операционной системы MS-DOS, для которой задача защиты от несанкционированного доступа не актуальна.
Обобщенно формат списка управления доступом можно представить в виде набора идентификаторов пользователей и групп пользователей, в котором для каждого идентификатора указывается набор разрешенных операций над объектом (рис. 7.29). Говорят, что список ACL состоит из элементов управления доступом (Access Control Element, АСЕ), при этом каждый элемент соответствует одному идентификатору. Список ACL с добавленным к нему идентификатором владельца называют характеристиками безопасности.
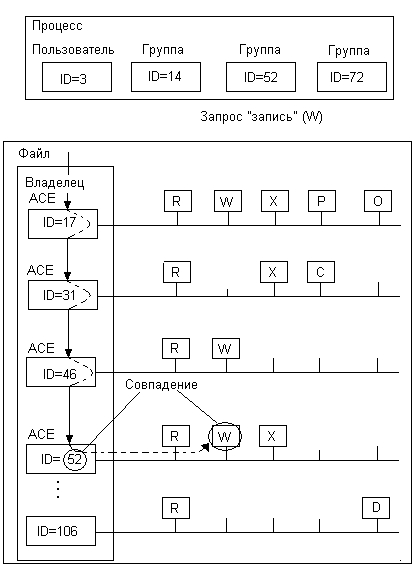
Рис. 7.29. Проверка прав доступа
В приведенном на рисунке примере процесс, который выступает от имени пользователя с идентификатором 3 и групп с идентификаторами 14, 52 и 72, пытается выполнить операцию записи (W) в файл. Файлом владеет пользователь с идентификатором 17. Операционная система, получив запрос на запись, находит характеристики безопасности файла (на диске или в буферной системной области) и последовательно сравнивает все идентификаторы процесса с идентификатором владельца файла и идентификаторами пользователей и групп в элементах АСЕ. В данном примере один из идентификаторов группы, от имени которой выступает процесс, а именно 52, совпадает с идентификатором одного из элементов АСЕ. Так как пользователю с идентификатором 52 разрешена операция чтения (признак W имеется в наборе операций этого элемента), то ОС разрешает процессу выполнение операции.
Описанная обобщенная схема хранения информации о правах доступа и процедуры проверки имеет в каждой операционной системе свои особенности, которые рассматриваются далее на примере операционных систем UNIX и Windows NT.
Организация контроля доступа в ОС UNIX
В ОС UNIX права доступа к файлу или каталогу определяются для трех субъектов:
- владельца файла (идентификатор User ID, UID);
- членов группы, к которой принадлежит владелец (Group ID, GID);
- всех остальных пользователей системы.
С учетом того что в UNIX определены всего три операции над файлами и каталогами (чтение, запись, выполнение), характеристики безопасности файла включают девять признаков, задающих возможность выполнения каждой из трех операций для каждого из трех субъектов доступа. Например, если владелец файла разрешил себе выполнение всех трех операций, для членов группы — чтение и выполнение, а для всех остальных пользователей — только выполнение, то девять характеристик безопасности файла выглядят следующим образом:
rwx r-х r--
Здесь г, w и х обозначают операции чтения, записи и выполнения соответственно. Именно в таком виде выводит информацию о правах доступа к файлам команда просмотра содержимого каталога 1 s. Суперпользователю UNIX все виды доступа позволены всегда, поэтому его идентификатор (он имеет значение 0) не фигурирует в списках управления доступом.
С каждым процессом UNIX связаны два идентификатора: пользователя, от имени которого был создан этот процесс, и группы, к которой принадлежит данный пользователь. Эти идентификаторы носят название реальных идентификаторов пользователя: Real User ID, RUID и реальных идентификаторов группы: Real Group ID, RGID. Однако при проверке прав доступа к файлу используются не эти идентификаторы, а так называемые эффективные идентификаторы пользователя: Effective User ID, EUID и эффективные идентификаторы группы: Effective Group ID, EGID (рис. 7.30).
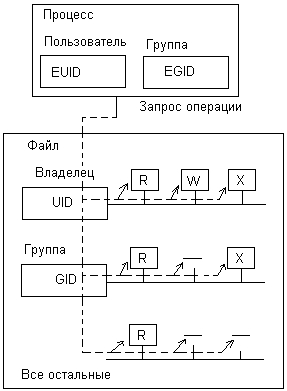
Рис. 7.30. Проверка прав доступа в UNIX
Введение эффективных идентификаторов позволяет процессу выступать в некоторых случаях от имени пользователя и группы, отличных от тех, которые ему достались при рождении. В исходном состоянии эффективные идентификаторы совпадают с реальными.
Случаи, когда процесс выполняет системный вызов ехес запуска приложения, хранящегося в некотором файле, в UNIX связаны со сменой процессом исполняемого кода. В рамках данного процесса начинает выполняться новый код, и если в характеристиках безопасности этого файла указаны признаки разрешения смены идентификаторов пользователя и группы, то происходит смена эффективных идентификаторов процесса. Файл имеет два признака разрешения смены идентификатора — Set User ID on execution (SUID) и Set Group ID on execution (SGID), которые разрешают смену идентификаторов пользователя и группы при выполнении данного файла.
Механизм эффективных идентификаторов позволяет пользователю получать некоторые виды доступа, которые ему явно не разрешены, но только с помощью вполне ограниченного набора приложений, хранящихся в файлах с установленными признаками смены идентификаторов. Пример такой ситуации приведен на рис. 7.31.
Первоначально процесс А имел эффективные идентификаторы пользователя и группы (12 и 23 соответственно), совпадающие с реальными. На каком-то этапе работы процесс запросил выполнение приложения из файла b.ехе. Процесс может выполнить файл b.ехе, хотя его эффективные идентификаторы не совпадают с идентификатором владельца и группы файла, так как выполнение разрешено всем пользователям.
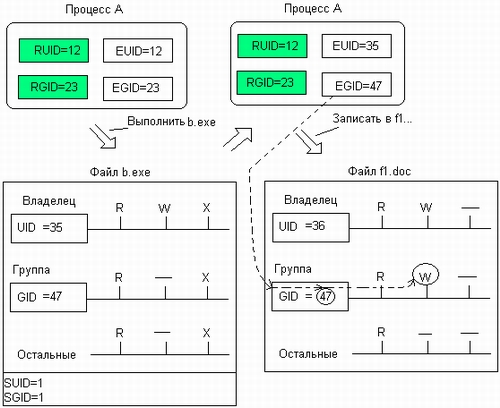
Рис. 7.31. Смена эффективных идентификаторов процесса
Файл Ь.ехе имеет установленные признаки смены идентификаторов SUID и SGID, поэтому одновременно со сменой кода процесс меняет и значения эффективных идентификаторов (35 и 47). Вследствие этого при последующей попытке записать данные в файл f 1.doc процессу А это удается, так как его новый эффективный идентификатор группы совпадает с идентификатором группы файла f1.doc. Без смены идентификаторов эта операция для процесса А была бы запрещена.
Описанный механизм преследует те же цели, что и рассмотренный выше механизм подчиненных сегментов процессора Pentium.
Использование модели файла как универсальной модели разделяемого ресурса позволяет в UNIX применять одни и те же механизмы для контроля доступа к файлам, каталогам, принтерам, терминалам и разделяемым сегментам памяти.
Система управления доступом ОС UNIX была разработана в 70-е годы и с тех пор мало изменилась. Эта достаточно простая система позволяет во многих случаях решить поставленные перед администратором задачи по предотвращению несанкционированного доступа, однако такое решение иногда требует слишком больших ухищрений или же вовсе не может быть реализовано.
Организация контроля доступа в ОС Windows NT

