 2015-04-12
2015-04-12 2178
2178Рассмотрим сначала несерьезный пример. Дана колода из 32 карт. Требуется отсортировать колоду так, чтобы карты лежали по мастям (например, пики, трефы, бубны, черви), а внутри каждой масти – по убыванию: туз, король, дама, валет, 10, 9, 8, 7.
Предлагается такое решение. Сначала просмотрим один раз колоду, раскладывая карты на 8 стопок по старшинству: тузы, короли, дамы и т.п. Затем соберем стопки опять в одну колоду, но в определенном порядке: сначала тузы, затем короли, дамы и т.д. Теперь еще раз просмотрим колоду от начала до конца, раскладывая карты на 4 стопки по мастям.
Нетрудно понять, что внутри каждой масти карты будут правильно отсортированы. Осталось собрать все масти в требуемом порядке. Сортировка закончена, и она потребовала всего двух проходов по массиву (колоде)! Ну, или максимум – четырех, если сбор нескольких стопок в одну колоду тоже считать проходом.
Заметим еще, что при использовании полной колоды (52 карты) число проходов не изменится, а время выполнения каждого прохода возрастет линейно.
Теперь сформулируем задачу в более общем и серьезном виде. Требуется отсортировать таблицу по возрастанию значений ключа, при этом для ключей выполняются следующие условия.
1. Ключ состоит из k компонент: x = (x1, x2, …, xk). Для приведенного выше примера с картами ключ состоит из масти и значения. Более серьезный пример – даты, которые состоят из года, месяца и числа.
2. Сортировка выполняется в лексикографическом порядке, т.е. по возрастанию первой компоненты x1, при равенстве x1 – по возрастанию x2 и т.д. Например, даты сортируются по году, внутри одного года – по месяцам, внутри месяца – по числам.
3. Каждая компонента ключа может принимать небольшое число значений, причем желательно последовательных: li £ xi £ hi. Число этих значений обозначим ui = li - hi + 1.
Что значит «небольшое число значений»? На практике это означает, что в программе может быть описан (или динамически создан) массив из ui элементов (от li до hi для каждого i). То есть речь может идти о десятках, сотнях, в крайнем (нежелательном) случае нескольких тысячах значений. В примере с датами число принимает значения от 1 до 31, месяц – от 1 до 12. Сложнее с годом; однако часто можно ограничиться, скажем, датами из XX и XXI вв., тогда число значений равно 200.
В качестве еще одного примера рассмотрим десятичные числа с ограниченным числом разрядов; например, числа от 0 000 000 до 9 999 999. Первую цифру (число миллионов) будем рассматривать как компоненту x1, вторую цифру – как x2, последнюю цифру (число единиц) – как x7. Именно с этим примером связано само название «поразрядная сортировка».
Алгоритм поразрядной сортировки мы опишем на псевдокоде, чтобы не вдаваться в скучные подробности. Предварительно заметим, что в алгоритме используются линейные списки и операции над ними. Предполагается, что читатель знаком с этой структурой данных.
Для единообразия будем считать, что и сама исходная таблица задана не как массив, а как линейный список записей. Если это не так, то можно предварительно преобразовать массив в список, а после сортировки переписать данные из списка обратно в массив. Предполагается также, что для линейных списков можно легко и быстро выполнить операции добавления элемента в хвост и соединения двух списков в один. Для этого можно воспользоваться, например, списками с указателем на хвост или циклическими списками.
procedure RadixSort(A);
begin
for i:= k downto 1 do begin
Создать массив пустых линейных списков B[li..hi];
for(каждый элемент d списка A, начиная с головы) do
Перенести d в хвост списка B[v], где v = значение
компоненты ключа xi для записи d;
for v:= li to hi do
Подключить список B[v] в хвост списка A;
end;
end;
Как работает этот алгоритм?
Работа начинается с наименее важной компоненты ключа (в примере с датами это число месяца). Все сортируемые элементы разносятся по спискам в зависимости от значения компоненты (для числа месяца это будут списки от B1 до B31). Список A становится пустым. Далее сливаем все списки Bv в общий список A. Теперь в этом списке будут сначала все даты с числом месяца 1, затем с числом 2 и т.д. до 31. Затем все то же самое повторяется для предыдущей (более важной) компоненты ключа (в примере с датами это номер месяца). После очередного слияния общий список A будет содержать сначала январские даты, потом февральские и т.д. Нетрудно видеть, что при этом внутри каждого месяца сохранится сортировка по числам. Наконец, строятся списки по годам, причем внутри каждого года сохраняется сортированность по месяцам и числам. После слияния этих списков сортировка закончена.
Почему в качестве промежуточного хранилища для записей с одинаковыми значениями компоненты ключа используются линейные списки, а не массивы? Прежде всего потому, что значения компоненты могут быть распределены неравномерно. Нельзя исключать даже крайний случай, когда, например, все сортируемые даты относятся к одному месяцу или к одному году. Поэтому массивы пришлось бы создавать по максимуму возможной длины каждого из них, а это привело бы к огромным затратам памяти. Далее, слияние данных из многих массивов в один потребовало бы дополнительных затрат времени порядка O(n) на каждое слияние, а подключение списков в хвост друг другу требует времени, пропорционального всего лишь числу ui (числу возможных значений компоненты).
Оценим трудоемкость алгоритма. Каждый проход по таблице требует времени порядка O(n). Создание списков и их последующее слияние требуют времени O(ui). Число проходов равно числу компонент ключа k. Собирая это воедино, получим оценку: 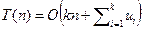 .
.
Заметим, что как k, так и ui не зависят от n. Полагая эти величины константами, получаем удивительную оценку: T(n) = O(n). Линейная оценка для алгоритма сортировки – об этом, казалось бы, можно только мечтать.
Если поразрядная сортировка так хороша, то зачем мы тогда рассматривали все предыдущие алгоритмы, оценка которых в лучшем случае T(n) = O(n·log(n))?
Давайте рассмотрим, при каких условиях поразрядная сортировка работает столь чудесно. Эти условия были приведены выше: ключ должен состоять из нескольких компонент, каждая из которых принимает небольшое число значений. Хотя при получении оценки «O-большое» мы отбросили k и ui как константы, слишком большие значения этих констант могут свести на нет преимущества линейной оценки.
Рассмотрим крайний случай: целочисленный четырехбайтовый ключ, не разлагающийся ни на какие компоненты. Формально можно сказать, что k = 1, но тогда u1 равно мощности множества всех целых чисел выбранной разрядности, т.е. 232. Создать такое количество списков явно нереально.
Более интересен пример с десятичными числами, разбитыми на разряды. В этом случае все ui = 10, но k есть максимальное число цифр, которое примерно равно десятичному логарифму максимального допустимого числа. Таким образом, в оценке времени все-таки появляется логарифм, хотя и не совсем тот, что для QuickSort и HeapSort.
Практика показывает, что алгоритм поразрядной сортировки для числовых или строковых ключей, искусственно разбитых на разряды или на байты, все же несколько уступает ранее описанным алгоритмам. Зато поразрядная сортировка быстрее всех прочих, если ключ распадается на компоненты естественным образом, как это было в примере с датами.








