2015-04-12
2015-04-12 762
762Рассмотрим один важный частный случай задач поиска.
Пускай поиск ведется по строковому ключу не слишком большой длины. Практически имеются в виду ключи, являющиеся словами некоторого естественного или искусственного языка, поэтому рассматриваемая задача называется задачей поиска в словаре. Один из важных примеров применения такого поиска – распознавание команд, введенных пользователем с клавиатуры в диалоге с операционной системой или с прикладной программой.
Применим для хранения словаря совершенно иную структуру данных, чем использовались в предыдущих разделах. Весь словарь будет представлен деревом, вершины которого (кроме корневой) помечены буквами. Используется также специальный символ «конец слова», который мы будем обозначать знаком #.
Подобное представление принято называть нагруженным деревом[6].
На рис. 5.1 показано представление небольшого словаря из 9 слов: «бак», «бок», «бор», «борода», «борт», «к», «кора», «корова», «корт».
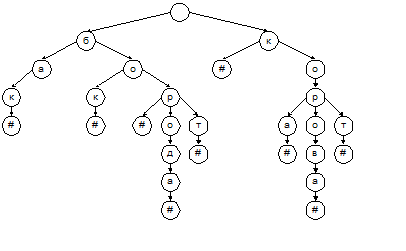
Рис. 5.1. Нагруженное дерево
Выполнение поиска по такому дереву понятно без особых пояснений. Отметим только, что вместо привычных сравнений «меньше/больше» здесь используются сравнения «равно/не равно» для очередной буквы ключа. Вставка и удаление слов также делаются без труда. Следует, однако, выбрать подходящую структуру данных для хранения небинарного дерева. Типовой способ преобразования дерева к бинарному виду предполагает, что для каждой вершины один из указателей направлен к «правому брату» вершины, а другой – к ее «старшему сыну». Результат преобразования показан на рис. 5.2.
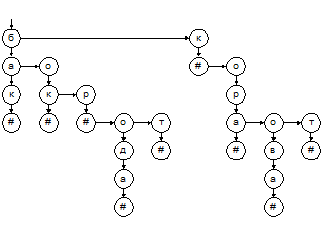
Рис. 5.2. Бинарное представление нагруженного дерева
Довольно трудно провести корректное сравнение поиска по нагруженному дереву с традиционными алгоритмами бинарного поиска по массиву или по дереву. Если время бинарного поиска зависит от числа записей в таблице, то время поиска по нагруженному дереву определяется длиной ключа. С точки зрения расхода памяти нагруженные деревья весьма избыточны (на каждую хранимую букву приходится по два указателя), но, с другой стороны, одинаковые начальные части разных слов хранятся лишь один раз.
Удовлетворимся поэтому экспериментальными оценками, которые показывают, что нагруженные деревья все же заметно уступают традиционным структурам данных по памяти, но по скорости поиска превосходят ранее описанные методы и работают наравне с описанными ниже алгоритмами хеширования или даже быстрее.