 2015-04-12
2015-04-12 933
933Системы управления базами данных (СУБД) представляют собой важный класс программ, предназначенных для обеспечения надежной и эффективной работы с большими объемами данных. Оперативное выполнение запросов к базам данных требует использования структур данных и алгоритмов, обеспечивающих выполнение операций поиска, вставки и удаления записей в таблицах базы данных за минимальное время. Одной из таких структур, весьма широко используемых в современных СУБД, являются B-деревья.
Как правило, СУБД позволяет определять для одной таблицы данных несколько ключевых полей и обеспечивает быстрый поиск по значению любого из этих полей. Примерная структура данных на диске показана на рис. 4.11.
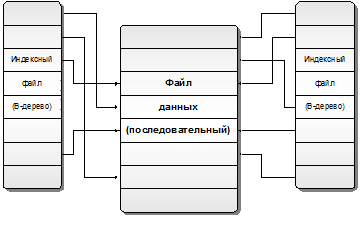
Рис. 4.11.Файловая структура базы данных
На рисунке изображен файл данных, содержащий записи таблицы базы данных. Записи, добавляемые в этот файл, помещаются обычно в конец файла. При удалении записей их просто помечают флажком «Удаленная», а физическое удаление с перезаписью файла данных откладывают «на потом» как отдельную трудоемкую операцию.
При создании таблицы для нее указывается одно или несколько ключевых полей. Для каждого ключа создается отдельный индексный файл, структура которого обычно представляет собой B-дерево. С каждым значением ключа в индексном файле связан указатель на соответствующую запись в файле данных. При добавлении и удалении записей в файл данных, а также при изменении значений ключевых полей, для каждого индексного файла выполняются соответствующие операции над B-деревом. Так обеспечиваются возможности быстрой модификации данных и быстрого поиска по любому из ключей.








