 2015-04-01
2015-04-01 9036
9036Диаграмма классов является основным средством моделирования структуры UML. Класс в UML является основной структурной единицей. Диаграммы классов наиболее информационно насыщены по сравнению с другими типами канонических диаграмм UML, инструменты генерируют код в основном по описанию классов, структура классов точнее всего соответствует окончательной структуре кода приложения.
На диаграммах классов в качестве сущностей применяются, прежде всего, классы, как в своей наиболее общей форме, так и в форме многочисленных стереотипов и частных случаев: интерфейсы, типы данных, процессы и др. Кроме того, в диаграмме классов могут использоваться (как и везде) пакеты и примечания. Сущности на диаграммах классов связываются главным образом отношениями ассоциации (в том числе агрегирования и композиции) и обобщения. Отношения зависимости и реализации на диаграммах классов применяются реже.
Класс — один из самых "богатых" элементов моделирования UML. Описание класса может включать множество различных элементов, и чтобы они не путались, в языке предусмотрено группирование элементов описания класса по разделам.
Стандартных разделов три:
- раздел имени — наряду с обязательным именем может содержать также стереотип, кратность и список свойств;
- раздел атрибутов — содержит список описаний атрибутов класса;
- раздел операций — содержит список описаний операций класса.
Как и все основные сущности UML, класс обязательно имеет имя, а стало быть раздел имени не может быть опущен. Прочие разделы могут быть пустыми. Наряду со стандартными разделами, описание класса может содержать и произвольное количество дополнительных разделов. Семантически дополнительные разделы эквиваленты примечаниям. Если инструмент умеет что-то делать с информацией в дополнительных разделах, пусть делает. В любом случае инструмент обязан сохранить эту информацию в модели.
Нотация классов очень проста — это всегда прямоугольник. Если разделов более одного, то внутренность прямоугольника делится горизонтальными линиями на части, соответствующие разделам. Содержимым раздела в любом случае является текст. Текст внутри стандартных разделов должен иметь определенный синтаксис.
Раздел имени класса в общем случае имеет следующий синтаксис.
«стереотип» ИМЯ {свойства} кратность.
В табл. 2 перечислены стандартные стереотипы классов.
Таблица 2. Стандартные стереотипы классов
| Стереотип | Описание |
| actor | действующее лицо |
| enumeration | перечислимый тип данных |
| exception | сигнал, распространяемый по иерархии обобщений |
| implementation Class | реализация класса |
| interface | нет атрибутов и все операции абстрактные |
| metaclass | экземпляры являются классами |
| powrtype | метакласс,, экземплярами которого являются все наследники данного класса |
| process, thread | активные классы |
| signal | класс, экземплярами которого являются сообщения |
| stereotype | стереотип |
| type (datatype) | тип данных |
| utility | нет экземпляров = служба |
Обязательное имя класса может быть выделено курсивом и в этом случае данный класс является абстрактным, т. е. не могущим иметь непосредственных экземпляров. Если имя подчеркнуто, то это уже не имя класса, а имя объекта.
Класс, а также отдельные элементы его описания могут иметь произвольные заданные пользователем ограничения и именованные значения.
Кратность класса задается по общим правилам. Наиболее распространенный случай неограниченной кратности (т. е. класс может иметь произвольное значение экземпляров) подразумевается по умолчанию и никак не отражается на диаграмме классов. Другой распространенный случай — нулевая кратность — обычно представляется с помощью стандартного стереотипа «utility» (см. табл. 2).
Рассмотрим пример раздела имени класса для нашей информационной системы отдела кадров.
Если мы предполагаем, что проектируемая информационная система отдела кадров будет использоваться на одном предприятии, то целесообразно определить служебный класс Company со стереотипом utility для хранения глобальных атрибутов и операций информационной системы отдела кадров. Раздел имени такого класса показан на рисунке 3.3.

Рисунок 3.3. Раздел имени службы
Атрибут — это именованное место (или, как говорят, слот), в котором может храниться значение.
Атрибуты класса перечисляются в разделе атрибутов. В общем случае описание атрибута имеет следующий синтаксис.
видимость ИМЯ кратность: тип = начальное значение {свойства}
Видимость, как обычно, обозначается знаками +, -, #. Еще раз подчеркнем, что если видимость не указана, то никакого значения видимости по умолчанию не подразумевается.
Если имя атрибута подчеркнуто, то это означает, что областью действия данного атрибута является класс, а не экземпляр класса, как обычно. Другими словами, все объекты — экземпляры этого класса совместно используют одно и тоже значение данного атрибута, общее для всех экземпляров. В обычной ситуации (нет подчеркивания) каждый экземпляр класса хранит свое индивидуальное значение атрибута.
Подчеркивание описания атрибута соответствует описателю static в языке С++. Кратность, если она присутствует, определяет данный атрибут как массив (определенной или неопределенной длины).
Тип атрибута — это либо примитивный (встроенный) тип, либо тип определенный пользователем.
Начальное значение имеет очевидный смысл: при создании экземпляра данного класса атрибут получает указанное значение. Заметим, что если начальное значение не указано, то никакого значения по умолчанию не подразумевается. Если нужно, чтобы атрибут обязательно имел значение, то об этом должен позаботиться конструктор класса.
Как и любой другой элемент модели, атрибут может быть наделен дополнительными свойствами в форме ограничений и именованных значений.
У атрибутов имеется еще одно стандартное свойство: изменяемость. В табл. 3 перечислены возможные значения этого свойства.
Таблица 3. Значения свойства изменяемости атрибута
| Значение | Описание |
| changeable | Никаких ограничений на изменение атрибута не накладывается. Данное значение имеет место по умолчанию, поэтому указывать в модели его излишне |
| addOnly | Это значение применимо только к атрибутам, кратность которых больше единицы. При изменеии значения атрибута новое значение добавляется в массив значений, но старые значения не меняются и не исчезают. Такой атрибут «помнит» историю своего изменения. |
| frozen | Значение атрибута задается при инициализации объекта и не может меняться |
Например, в информационной системе отдела кадров класс Person, скорее всего, должен иметь атрибут, хранящий имя сотрудника. В табл. 4 приведен список примеров описаний такого атрибута. Все описания синтаксически допустимы и могут быть использованы в соответствии с текущим уровнем детализации модели.
Таблица 4. Примеры описаний атрибутов
| Пример | Пояснение |
| name | Минимальное возможное описание – указано только имя атрибута |
| +name | Указаны имя, тип и открытая видимость - предполагается, манипуляции с именем будут проводиться непосредственно |
| -name:String | Указаны имя, тип и закрытая видимость - манипуляции с именем будут проводиться с помощью специальных операций |
| -name[1..3]:String | Указана кратность (для хранения трех составляющих: фамилии, имени, отчества) |
| -name:String = “Novikov” | Указано начальное значение |
| +name:String {frozen} | Атрибут объявлен не меняющим своего значения после начального присваивания и открытым |
Операция — это описание способа выполнить какие-то действия с объектом: изменить значения его атрибутов, вычислить новое значение по информации хранящейся в объекте и т. д.
Выполнение действий, определяемых операцией, инициируется вызовом операции. При выполнении операция может, в свою очередь, вызывать операции этого и других классов.
Описания операций класса перечисляются в разделе операций и имеют следующий синтаксис:
видимость ИМЯ (параметры): тип {свойства}
Здесь слово параметры обозначает последовательность описаний параметров операции, каждое из которых имеет вид следующий формат.
направление ПАРАМЕТР: тип = значение
Видимость, как обычно, обозначается с помощью знаков +, -, #. Подчеркивание имени означает, что область действия операции — класс, а не объект. Например, конструкторы имеют область действия класс. Курсивное написание имени означает, что операция абстрактная, т. е. в данном классе ее реализация не задана и должна быть задана в подклассах данного класса. После имени в скобках может быть указан список описаний параметров. Описания параметров в списке разделяются запятой. Для каждого параметра обязательно указывается имя, а также могут быть указаны направление передачи параметра, его тип и значение аргумента по умолчанию.
Направление передачи параметра в UML описывает семантическое назначение параметров, не конкретизируя конкретный механизм передачи. Как именно следует трактовать указанные в модели направления передачи параметров, зависит от используемой системы программирования. Возможные значения направления передачи приведены в табл. 5.
Таблица 5. Ключевые слова для описания направления передачи параметров
| Ключевое слово | Назначение параметра |
| In | Входной параметр – аргумент должен быть значением, которое используется в операции, но не изменяется |
| Out | Выходной параметр – аргумент должен быть хранилищем, в которое операция помещает значение |
| Inout | Входной и выходной параметр – аргумент должен быть хранилищем, содержащим значение. Операция использует переданное значение аргумента и помещает в хранилище результат |
| Return | Значение, возвращаемое операцией. Никакого аргумента не требуется |
Типом параметра операции, равно как и тип возвращаемого операцией значения может быть любой встроенный тип или определенный в модели класс.
Все вместе (имя операции, параметры и тип результата) обычно называют сигнатурой. Стандарт предлагает считать сигнатурой имя операции плюс количество, порядок и типы параметров (т. е. направление передачи параметров и их имена, а также тип результата не входят в сигнатуру). Но это точка вариации семантики — в конкретном инструменте может быть реализовано другое понятие сигнатуры. Если сигнатуры различны, то и операции различны (даже если совпадают имена).
В одном классе не может быть двух операций с одной сигнатурой — модель считается противоречивой. Если в подклассе определена операция с той же самой сигнатурой, то возможны два случая. Если описание операции в подклассе в точности то же самое или если оно является непротиворечивым расширением (например, в классе не был указан тип результата, а в подклассе он указан), то это повторное описание той же самой операции. Если же описание операции с совпадающей сигнатурой в подклассе противоречит описанию в классе (например, явно указаны различные направления передачи параметров), то модель считается противоречивой.
Операция имеет два важных свойства, которые указываются в списке свойств как именованные значения.
Во-первых, это concurrency — свойство, определяющее семантику одновременного (параллельного) вызова данной операции. В приложениях, где имеется только один поток управления, никаких параллельных вызовов быть не может. Действительно, если операция вызвана, то выполнение программы приостанавливается в точке вызова до тех пор, пока не завершится выполнение вызванной операции. В однопоточных приложениях в каждый момент времени управление находится в одной определенной точке программы и выполняется ровно одна определенная операция.
Рекурсивный вызов (т. е. вызов операции из нее самой) не считается параллельным, поскольку при рекурсивном вызове выполнение операции, как обычно, приостанавливается и, таким образом, всегда выполняется только один экземпляр рекурсивной операции. Не так обстоит дело в приложениях, где имеется несколько потоков управления. В таком случае операция может быть вызвана из одного потока и в то время, пока ее выполнение еще не завершилось, вызвана из другого потока. Значение свойства concurrency определяет, что будет происходить в этом случае. Возможные варианты и их описания даны в табл. 6.
Таблица 6. Значения свойства concurrency
| Ключевое слово | Назначение параметра |
| In | Входной параметр – аргумент должен быть значением, которое используется в операции, но не изменяется |
| Out | Выходной параметр – аргумент должен быть хранилищем, в которое операция помещает значение |
| Inout | Входной и выходной параметр – аргумент должен быть хранилищем, содержащим значение. Операция использует переданное значение аргумента и помещает в хранилище результат |
| Return | Значение, возвращаемое операцией. Никакого аргумента не требуется |
Во-вторых, операция имеет свойство isQuery, значение которого указывает, обладает ли операция побочным эффектом. Если значение данного свойства true, то выполнение операции не меняет состояния системы — операция только вычисляет значения, возвращаемые в точку вызова. В противном случае, т. е. при значение false, операция меняет состояние системы: присваивает новые значения атрибутам, создает или уничтожает объекты и т. п. По умолчанию операция имеет свойство {isQuery=false}. Поэтому, если нужно указать, что данная операция — это функция без побочных эффектов, то достаточно написать {isQuery}. Рассмотрим примеры описания возможных операций класса Person информационной системы отдела кадров (табл. 7).
Таблица 7. Примеры описания операций
| Пример | Пояснение |
| move | Минимально возможное описание – указано только имя операции |
| +move(in from: Dpt, in to) | Указаны видимость операции, направления передачи и имена параметров |
| +move(in from: Dpt, in to: Dpt) | Подробное описание сигнатуры: указаны видимость операции, направления передачи, имена и типы параметров |
| +getName(): String {isQuery} | Функция, возвращающая значение атрибута и не имеющая побочных эффектов |
| +setPwd(in pwd: String = “password”) | Процедура, для которой указано значение аргумента по умолчанию |
Всего в UML определено 17 стандартных стереотипов отношения зависимости, которые можно разделить на 6 групп:
- между классами и объектами на диаграмме классов;
- между пакетами;
- между вариантами использования;
- между объектами на диаграмме взаимодействия;
- между состояниями автомата;
- между подсистемами и моделями.
Здесь рассматриваются зависимости первой группы, которые перечислены в табл. 8.
Повторим еще раз, что зависимости на диаграммах классов используются сравнительно редко, потому что имеют более расплывчатую семантику по сравнению с ассоциациями и обобщением. В нашей (достаточно простой) модели информационной системы отдела кадров не нашлось естественных примеров использования зависимостей на диаграмме классов, поэтому мы ограничимся немногочисленными ссылками на примеры в табл. 8.
Таблица 8. Стандартные стереотипы зависимостей на диаграмме классов
| Стереотип | Применение |
| bind | Подстановка параметров в шаблон. Независимой сущностью является шаблон (класс с параметрами), а зависимой – класс, который получается из шаблона заданием аргументов. |
| derive | Буквально означает «может быть вычислен по». Зависимость с данным стереотипом применяется не только к классам, но и к другим элементам модели: атрибутам, ассоциациям и др. Суть состоит в том, что зависимый элемент может быть восстановлен по информации, содержащейся в независимом элементе. Таким образом, данная зависимость показывает, что зависимый элемент, вообще говоря, излишен и введен в модель из соображения удобства, наглядности и т.д. |
| friend | Назначает специальные права видимости. Зависимый класс имеет доступ к составляющим независимого класса, даже если по общим правилам видимости он не имеет на это прав. |
| instanceOf | Указывает, что зависимый объект (или класс) является экземпляром независимого класса (метакласса) |
| instantiate | Указывает, что операции независимого класса создают экземпляры зависимого класса |
| powertype | Показывает, что экземплярами зависимого класса являются подклассы независимого класса. Таким образом, в данном случае зависимый класс является метаклассом |
| refine | Указывает, что зависимый класс уточняет независимый. Данная зависимость показывает, что связанные классы концептуально совпадают, но находятся на разном уровне абстракции |
| use | Зависимость самого общего вида, показывающая, что зависимый класс каким-либо образом использует независимый класс |
Отношение обобщения часто применяется на диаграмме классов. Действительно, трудно представить себе ситуацию, когда между объектами в одной системе нет ничего общего. Как правило, общее есть и это общее целесообразно выделить в отдельный класс. При этом общие составляющие, собранные в суперклассе, автоматически наследуются подклассами. Таким образом, сокращается общее количество описаний, а значит, уменьшается вероятность допустить ошибку. Использование обобщений не ограничивает свободу проектировщика системы, поскольку унаследованные составляющие можно переопределить в подклассе, если нужно.
При обобщении выполняется принцип подстановочности. Фактически это означает увеличение гибкости и универсальности программного кода при одновременном сохранении надежности, обеспечиваемой контролем типов. Действительно, если, например, в качестве типа параметра некоторой процедуры указать суперкласс, то процедура будет с равным успехом работать в случае, когда в качестве аргумента ей передан объект любого подкласса данного суперкласса. Суперкласс может быть конкретным, а может быть абстрактным, введенным именно для построения отношений обобщения.
Рассмотрим пример. В информационной системе отдела кадров мы выделили классы Position, Department и Person. Резонно предположить, что все эти классы имеют атрибут, содержащий собственное имя объекта, выделяющее его в ряду однородных. Для простоты положим, что такой атрибут имеет тип String. В таком случае можно определить суперкласс, ответственный за хранение данного атрибута и работу с ним, а прочие классы связать с суперклассом отношением обобщения. Однако более пристальный анализ предметной области наводит на мысль, что работа с собственным именем для выделенных классов производится не совсем одинаково.
Действительно, назначение и изменение собственных имен подразделениям и должностям находится в пределах ответственности информационной системы отдела кадров, но назначение (изменение) собственного имени сотрудника явно выходит за эти пределы. Исходя из этих соображений, мы приходим к структуре обобщений, представленной на рисунке 3.4. Обратите внимание, что суперкласс Unit мы определили как абстрактный, т. е. не могущий иметь непосредственных экземпляров, поскольку не предполагаем иметь в системе объекты данного класса. Класс Unit в данном нужен только для того, чтобы свести описания одного атрибута и двух операций в одно место и не повторять их дважды.
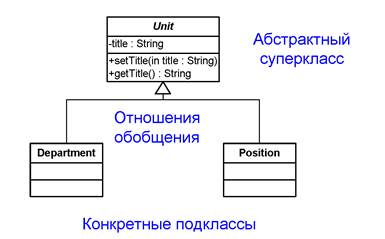
Рисунок 3.4 – Отношение обобщения
Таким образом, в UML допускается, чтобы класс был подклассом нескольких суперклассов (множественное наследование), не требуется, чтобы у базовых классов был общий суперкласс (несколько иерархий обобщения) и вообще не накладывается никаких ограничений, кроме частичной упорядоченности (т. е. отсутствия циклов в цепочках обобщений). Нарушение данного условия является синтаксической ошибкой, однако не все инструменты проверяют это условие — цикл может быть незаметен, потому что отдельные дуги цикла обобщений могут быть показаны на разных диаграммах. При множественном обобщении возможны конфликты: суперклассы содержат составляющие, которые невозможно включить в один подкласс, например, атрибуты с одинаковыми именами, но разными типами. В UML конфликты при множественном обобщении считаются нарушением правил непротиворечивости модели.
Рассмотрим пример с описанием свойств личности. Для информационной системы отдела кадров этот пример несколько искусственен, но в сложных системах встречаются и более изощренные ситуации. Заодно здесь иллюстрируется использование стереотипа metaclass. Допустим, мы моделируем такие свойства личности, как пол и отношение к собственности.
Тогда данную ситуацию можно описать с помощью диаграммы, приведенной на рисунке 3.5. Классы Male и Female являются экземплярами метакласса Gender. Классы Owner и Employe являются экземплярами метакласса Status. Это видно из имен подмножеств обобщений, указанных возле пунктирных линий, выделяющих подмножества. Классификация по полу является завершенной и дизъюнктной. Классификация по отношению собственности, напртив, не является ни завершенной, ни дизъюнктной.
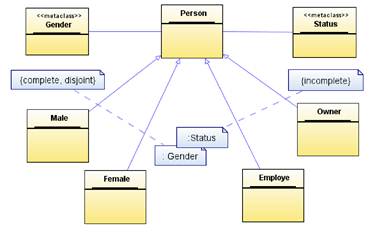
Рисунок 3.5. Подмножества обобщений и метаклассы
Иногда бывает важно указать, что некоторый объект является экземпляром конкретного класса. Это делается с помощью стереотипа instanceOf (Рисунок 3.6). Далее, обычно конструктор объектов класса определяется в классе. Но иногда конструктор помещают в другой класс, который в таком случае называют фабрикой. На рисунке 3.6 объект (единственный) класса Company является фабрикой объектов классов Department и Person, а объект класса Department является фабрикой объектов класса Position
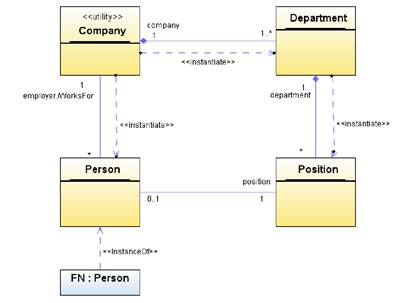
Рисунок 3.6. Инстанциирование и спецификация экземпляра
Отношение ассоциации является, видимо, самым важным на диаграмме классов. В общем случае ассоциация, которая обозначается сплошной линией, соединяющей классы, означает, что экземпляры одного класса связаны с экземплярами другого класса. Поскольку экземпляров может быть много, и каждый может быть связан с несколькими, ясно, что ассоциация является дескриптором, который описывает множество связанных объектов. В UML ассоциация является классификатором, экземпляры которого называются связями.
Связь между объектами (экземплярами классов) в программе может быть организована самыми разными способами. Например, в объекте одного класса может хранится указатель на объект другого класса. Другой вариант: объект одного класса является контейнером для объектов другого класса. Связь не обязательно является непосредственно хранимым физическим адресом. Этот адрес может динамически вычисляться во время выполнения программы на основании другой информации. Например, если объекты представлены как записи в таблице базы данных, то связь означает, в записи одного объекта имеется поле, значением которого является первичный ключ записи другого объекта (из другой таблицы). Еще пример: использование какого-либо механизма динамического связывания по имени (уникальному идентификатору) объекта.
При моделировании на UML техника реализации связи между объектами не имеет значения. Ассоциация в UML подразумевает лишь то, что связанные объекты обладают достаточной информацией для организации взаимодействия. Возможность взаимодействия означает, что объект одного класса может послать сообщение объекту другого класса, в частности, вызвать операцию или же прочитать или изменить значение открытого атрибута. Поскольку в объектно-ориентированной программе такого рода действия и составляют суть выполнения программы, моделирование структуры взаимосвязей объектов (т. е. выявление ассоциаций) является одной из ключевых задач при разработке.
Как уже было сказано, базовая нотация ассоциации (сплошная линия) позволяет указать, что объекты ассоциированных классов могут взаимодействовать во время выполнения. Но это только малая часть того, что можно моделировать с помощью отношения ассоциации. Для ассоциации в UML предусмотрено наибольшее количество различных дополнений, которые мы сначала перечислим, а потом рассмотрим по порядку. Дополнения, как обычно, не являются обязательными: их используют при необходимости, в различных ситуациях по разному. Если использовать все дополнения сразу, то диаграмма становится настолько перегруженной, что ее трудно читать.
Итак, для ассоциации определены следующие дополнения:
- имя ассоциации (возможно, вместе с направлением чтения);
- кратность полюса ассоциации;
- вид агрегации полюса ассоциации;
- роль полюса ассоциации;
- направление навигации полюса ассоциации;
- упорядоченность объектов на полюсе ассоциации;
- изменяемость множества объектов на полюсе ассоциации;
- квалификатор полюса ассоциации;
- класс ассоциации;
- видимость полюса ассоциации;
- многополюсные ассоциации.
Начнем по порядку. Имя ассоциации указывается в виде строки текста над (или под, или рядом с) линией ассоциации. Имя не несет дополнительной семантической нагрузки, а просто позволяет различать ассоциации в модели. Обычно имя не указывают, за исключением многополюсных ассоциаций или случая, когда одна и та же группа классов связана несколькими различными ассоциациями. Например, в информационной системе отдела кадров, если сотрудник занимает должность, то соответствующие объектов классов Person и Position должны быть связаны. Дополнительно можно указать направление чтения имени ассоциации. Фрагмент графической модели, приведенный на рисунке 3.7, фактически можно прочитать вслух:

Рисунок 3.7. Имя ассоциации
Кратность полюса ассоциации указывает, сколько объектов данного класса (со стороны данного полюса) участвуют в связи. Кратность может быть задана как конкретное число, и тогда в каждой связи со стороны данного полюса участвуют ровно столько объектов, сколько указано. Более распространен случай, когда кратность указывается как диапазон возможных значений, и тогда число объектов, участвующих в связи должно находится в пределах указанного диапазона. При указании кратности можно использовать символ *, который обозначает неопределенное число. Например, если в информационной системе отдела кадров не предусматривается дробление ставок и совмещение должностей, то (работающему) сотруднику соответствует одна должность, а должности соответствует один сотрудник или ни одного (должность вакантна). На рисунке 3.8 приведен соответствующий фрагмент диаграммы UML.
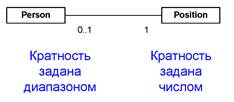
Рисунок 3.8. Кратность полюсов ассоциации
Более сложные случаи также легко моделируются с помощью кратности полюсов. Например, если мы хотим предусмотреть совмещение должностей и хранить информацию даже о неработающих сотрудниках, то диаграмма примет вид, приведенный на рисунке 3.9 (запись * эквивалентна записи 0..*).

Рисунок 3.9. Использование неопределенной кратности
Агрегация и композиция. В UML используются два частных, но очень важных случая отношения ассоциации, которые называются агрегацией и композицией. В обоих случаях речь идет о моделировании отношения типа «часть - целое». Ясно, что отношения такого типа следует отнести к отношениям ассоциации, поскольку части и целое обычно взаимодействуют.
Агрегация от класса A к классу B означает, что объекты (один или несколько) класса A входят в состав объекта класса B.
Это отмечается с помощью специального графического дополнения: на полюсе ассоциации, присоединенному к «целому», т. е., в данном случае, к классу B, изображается ромб. Например, на рисунке 3.10 указано, что подразделение является частью компании.

Рисунок 3.10. Агрегация
При этом никаких дополнительных ограничений не накладывается: объект класса A (часть) может быть связан отношениями агрегации с другими объектами (т. е. участвовать в нескольких агрегациях), создаваться и уничтожаться независимо от объекта класса B (целого).
Композиция накладывает более сильные ограничения: композиционно часть может входить только в одно целое, часть существует только пока существует целое и прекращает свое существование вместе с целым.
Графически отношение композиции отображается закрашенным ромбом. Для примера на рисунке 3.11 приведены два возможных взгляда на отношения между подразделениями и должностями в информационной системе отдела кадров. В первом случае (вверху), мы считаем, что в организации принята жесткая («армейская») структура: каждая должность входит ровно в одно подразделение, в каждом подразделении есть по меньшей мере одна должность (начальник). Во втором случае (внизу) структура организации более аморфна: возможны «висящие в воздухе» должности, бывают «пустые» подразделения и т. д.
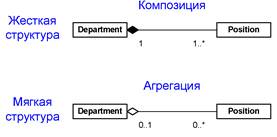
Рисунок 3.11. Сравнение композиции (вверху) и агрегации (внизу)
В комбинации с указанием кратности, отношения ассоциации, агрегации и композиции позволяют лаконично и полно отобразить структуру связей объектов: что из чего состоит и как связано. На рисунке 3.12 приведен пример одного из вариантов такой структуры для информационной системы отдела кадров.
Рисунок 3.12. Структура связей классов информационной системы отдела кадров
Роль полюса ассоциации, называемая также спецификатором интерфейса — это способ указать, как именно участвует классификатор (присоединенный к данному полюсу ассоциации) в ассоциации. В общем случае данное дополнение имеет следующий синтаксис:
видимость ИМЯ: тип
Имя является обязательным, оно называется именем роли и фактически является собственным именем полюса ассоциации, позволяющим различать полюса. Если рассматривается одна ассоциация, соединяющая два различных класса, то в именах ролей нет нужды: полюса ассоциации легко можно различить по именам классов, к которым они присоединены. Однако, если это не так, т. е. если два класса соединены несколькими ассоциациями, или же если ассоциация соединяет класс с самим собой, то указание роли полюса ассоциации является необходимым. Такая ситуация отнюдь не является надуманной, как может показаться.
Вернемся к рисунку 3.12, где мы, забегая вперед, начали разбор примера на эту тему. На этом рисунке изображена ассоциация класса Position с самим собой. Эта ассоциация призвана отразить наличие иерархии подчиненности должностей в организации. Однако из рисунка 3.12 видно только, что объекты класса Person образуют некоторую иерархию (каждый объект связан с некоторым количеством нижележащих в иерархии объектов и не более чем с одним вышележащим объектом), но не более того. Используя спецификацию интерфейсов и, заодно, (опять несколько забегая вперед) отношения реализации и интерфейсы можно описать субординацию в информационной системе отдела кадров достаточно лаконично, но точно.
Например, на рисунке 3.13 указано, что в иерархии субординации каждая должность может играть две роли. С одной стороны, должность может рассматриваться как начальственная (chief), и в этом случае она предоставляет интерфейс IChief имеющий операцию petition (начальнику можно подать служебную записку). С другой стороны, должность может рассматриваться как подчиненная (subordinate), и в этом случае она предоставляет интерфейс ISubordinate, имеющий операцию report (от подчиненного можно потребовать отчет). У начальника может быть произвольное количество подчиненных, в том числе и 0, у подчиненного может быть не более одного начальника.
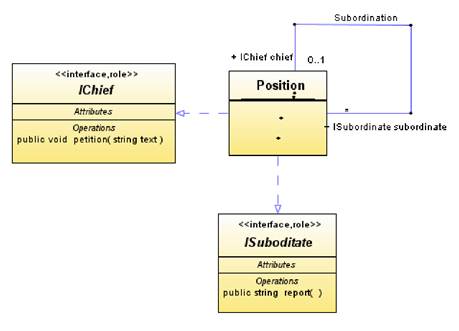
Рисунок 3.13. Роли полюсов ассоциации
Имя в виду ту же самую цель, можно поступить и по-другому: непосредственно включить в описание класса составляющие, ответственные за обеспечение нужной функциональности (Рисунок 3.14). Однако такое решение "не в духе" UML: во-первых, оно слишком привязано к реализации, разработчику не оставлено никакой свободы для творческих поисков эффективного решения; во-вторых оно менее наглядно — неудачный выбор имен атрибутов способен замаскировать семантику отношения для читателя модели, потеряны информативные имена ролей и ассоциации; в- третьих, оно менее надежно — в модели на рисунке 3.13 подчиненный синтаксически не может потребовать отчета от начальника, а в модели на рисунке 3.14 — может, и нужно предусматривать дополнительные средства для обработки этой ошибки.
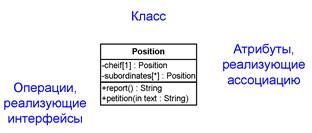
Рисунок 3.14. Атрибуты, обеспечивающие реализацию ролей
Направление навигации полюса ассоциации — это свойство полюса, имеющее значение типа Boolean, и определяющее, можно ли получить с помощью данной ассоциации доступ к объектам класса, присоединенному к данному полюсу ассоциации.
По умолчанию это свойство имеет значение true, т. е. доступ возможен. Если все полюса ассоциации (обычно их два) обеспечивают доступ, то это никак не отражается на диаграмме (потому, что данный случай наиболее распространенный и предполагается по умолчанию). Если же навигация через некоторые полюса возможна, а через другие нет, то те полюса, через которые навигация возможна, отмечаются стрелками на концах линии ассоциации. Таким образом, если никаких стрелок не изображается, то это означает, что подразумеваются стрелки во всех возможных направлениях. Если же некоторые стрелки присутствуют, то это означает, что доступ возможен только в направлениях, указанных стрелками. Отсюда следует, что в UML невозможно изобразить случай, когда навигация вдоль ассоциации невозможна ни в каком направлении — но это и не нужно, т. к. такая ассоциация не имеет смысла.
Рассмотрим следующий пример (который может быть полезен и в информационной системе отдела кадров, если понадобиться расширить ее функциональность защитой данных на уровне пользователя). Допустим, имеются два класса: User (содержит информацию о пользователе) и Password (содержит пароль — информацию, необходимую для аутентификации пользователя). Мы хотим отразить в модели следующую ситуацию: имеется взаимно однозначное соответствие между пользователями и паролями, зная пользователя можно получить доступ к его паролю, но обратное неверно: по имеющемуся паролю нельзя определить, кому он принадлежит. Такая ситуация может быть промоделирована, как показано на рисунке 3.15.

Рисунок 3.15. Направление навигации
Видимость полюса ассоциации — это указание того, является ли классификатор присоединенный к данному полюсу ассоциации, видимым для других классификаторов вдоль данной ассоциации, помимо тех классификаторов, которые присоединены к другим полюсам ассоциации.
Продолжим рассмотрение предыдущего примера. Допустим, у нас есть третий класс — Workgroup — ответственный за хранение информации о группах пользователей. Тогда очевидно, что зная группу, мы должны иметь возможность узнать, какие пользователи входят в группу, и обратно, для каждого пользователя можно определить в какую группу (или в какие группы) он включен. Но не менее очевидно, что доступ к группе не должен позволять узнать пароли пользователей этой группы. Другими словами, мы хотим ограничить доступ к объектам через полюс ассоциации. В UML для этого нужно явно указать имя роли полюса ассоциации, и перед именем роли поставить соответствующий символ (или ключевое слово) видимости (Рисунок 3.16).

Рисунок 3.16. Ограничение видимости полюса ассоциации
Обратите внимание, что, согласно семантическим правилам UML, ограничение видимости полюса pwd распространяется на объекты класса Workgroup, но не на объекты класса User — непосредственно связанные объекты всегда видят друг друга. Объект класса User может использовать интерфейс pwd, предоставляемый классом Password — стрелка навигации разрешает ему это, но объект класса Workgroup не может использовать интерфейс pwd — значение видимости private (знак -) запрещает ему это.
Следующая два дополнения встречаются сравнительно редко, но иногда без них не обойтись. Они не имеют специальной графической нотации, а записываются в виде стандартных ограничений на полюсах ассоциации.
Упорядоченность объектов на полюсе ассоциации. Ели кратность полюса лежит в диапазоне 0-1, то проблемы упорядоченности не возникает — на данном полюсе связи, возможно, имеется один объект, но не более того. При иных кратностях объектов может быть несколько, т. е. полюс связи присоединен к множеству объектов. По умолчанию множество объектов, присоединенных к данному полюсу связи, считается неупорядоченным (как и любое множество, если не оговорено противное). Если необходимо указать, что это множество упорядочено (см. пример ниже и рисунок 3.17), то нужно наложить соответствующее ограничение на полюс ассоциации.
В качестве ограничения используется одно из двух ключевых слов:
- ordered (или sorted) если множество упорядочено;
- unordered, если не упорядочено.
Обычно считается, что множество объектов на полюсе связи может изменяться произвольным образом (в пределах специфицированной кратности). Например, в один момент работы информационной системы отдела кадров в данном подразделении может быть одних 10 должностей, а в другой — 20 других. Совершенно аналогично, значение атрибута обычно может произвольным образом меняться в процессе жизни объекта (в пределах указанного типа атрибута). Однако иногда необходимо определенным образом ограничить изменяемость атрибута. Аналогично иногда нужно ограничить изменяемость состава множества объектов присоединенных к полюсу связи (экземпляру ассоциации). Для этого применяется тот же самый набор стандартных значений.
В информационной системе отдела кадров мы не нашли походящего примера, и для иллюстрации двух последних понятий используем пример из вычислительной геометрии. Допустим, что у нас есть класс Point, экземплярами которого являются точки (на плоскости). Многоугольник (Polygon) можно определить, как упорядоченное множество точек (вершин многоугольника), причем резонно предположить, что состав вершин данного многоугольника, после того, как он определен, не может меняться. Модель данной ситуации приведена на рисунке 3.179.

Рисунок 3.17. Упорядоченность и изменяемость множества объектов на полюсе связи
Рассмотрим ситуацию, когда два класса связаны ассоциацией "один ко многим" (именно этот случай имеет место в данном примере). Такая ассоциация доставляет для каждого экземпляра класса, находящегося на полюсе "один" множество (иногда большое) объектов класса, находящегося на полюсе "много". Например, по экземпляру многоугольника можно получить множество его вершин. Однако часто возникают ситуации, когда нужно получить не все множество ассоциированных объектов, а некоторое небольшое подмножество, чаще всего один конкретный объект. Чтобы выделить из множества один конкретный элемент, нужно располагать информацией, однозначно идентифицирующей этот элемент. Такую информацию принято называть ключом. Например, номер вершины в многоугольнике можно считать ключом и тогда задача ставится так: по многоугольнику и номеру вершины получить вершину.
Всегда можно применить следующее тривиальное решение: хранить ключ в самом объекте в качестве атрибута и, получив множество объектов, перебирать их все последовательно до тех пор, пока не найдется тот, который имеет искомое значение ключа. Такой прием называется линейным поиском. Для многоугольников, у которых не очень много вершин, данный способ может быть вполне приемлемым. Но в других случаях, когда к полюсу "много" присоединено действительно много объектов, линейный поиск слишком неэффективен. Известно множество программных решений, позволяющих эффективно выделить (найти в множестве) объект по ключу: сортированные массивы, таблицы расстановки (хэш-таблицы), деревья сортировки, внешние индексы и др. Эти приемы обобщены в UML понятием квалификатора.
Квалификатор полюса ассоциации — это атрибут (или несколько атрибутов) ассоциации, значение которого (которых) позволяет выделить один (или несколько) объектов класса, присоединенного к данному полюсу ассоциации.
Квалификатор изображается в виде небольшого прямоугольника на полюсе ассоциации, примыкающего к прямоугольнику класса. Внутри этого прямоугольника (или рядом с ним) указывается имена и, возможно, типы атрибутов квалификатора. Описание квалифицирующего атрибута ассоциации имеет такой же синтаксис, что и описание обычного атрибута класса, только оно не может содержать начального значения. Квалификатор может присутствовать только на том полюсе ассоциации, который имеет кратность "много", поэтому, если на полюсе ассоциации с квалификатором задана кратность, то она указывает не допустимую мощность множества объектов, присоединенных к полюсу связи, а допустимую мощность того подмножества, которое определяется при задании значений атрибутов квалификатора.
Например, на рисунке 3.18 приведен фрагмент модели для примера с многоугольниками, в котором использован квалификатор (в данном случае с именем number). Обратите внимание, что на полюсе ассоциации с квалификатором, присоединенном к классу Point, указана кратность 0-1 (а не *, как на Рисунок 3.17). Действительно, само наличие квалификатора указывает на кратность много, а кратность 0-1 указывает сколько вершин с конкретным номером связано с данным многоугольником: 1, если задан допустимый номер вершины, или 0 в противном случае.
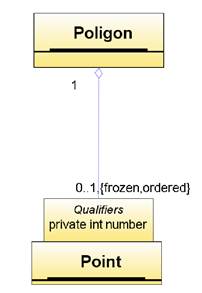
Рисунок 3.18. Квалификатор
Ассоциация имеет экземпляры (связи), стало быть, является классификатором и может обладать соответствующими свойствами и составляющими классификатора. В распространенных случаях, рассмотренных выше, ассоциации не обладали никакими собственными составляющими. Грубо говоря, ассоциация между классами A и B — это просто множество пар (a,b), где а — объект класса A, а b — объект класса B. Подчеркнем еще раз, что это именно множество: двух одинаковых пар (a,b) быть не может. Однако возможны и более сложные ситуации, когда ассоциация имеет собственные атрибуты (и даже операции), значения которых хранятся в экземплярах ассоциации — связях. В таком случае применяется специальный элемент моделирования — класс ассоциации.
Класс ассоциации — это сущность, которая имеет как свойства класса, так и свойства ассоциации.
Класс ассоциации изображается в виде символа класса, присоединенного пунктирной линией к линии ассоциации.
Вернемся к информационной системе отдела кадров и рассмотрим следующий пример. Допустим, что имеет место более сложное отношение между должностями и сотрудниками, нежели те, что приведены на рисунке 3.10 и 3.11. А именно, допускается не только совмещение должностей (один сотрудник может работать на нескольких должностях), но и дробление ставок (одну должность могут занимать несколько сотрудников — полставки, четверть ставки и т. п.). Использую уже разобранную нотацию ассоциации, мы можем констатировать, что между классами Person и Position имеет место ассоциация "многие ко многим". Однако этого недостаточно: необходимо указать, какую долю данной должности занимает данный сотрудник. Эту информацию нельзя отнести ни к должности, ни к сотруднику — это атрибут класса ассоциации между ними (Рисунок 3.19).

Рисунок 3.19. Класс ассоциации
Может показаться, что понятие класса ассоциации в UML является надуманным и излишним. Действительно, можно применить стандартный прием нормализации, который часто используется при проектировании схем баз данных: систематическим образом избавиться от отношений "многие ко многим" путем введения дополнительной сущности и двух отношений "один ко многим". Применительно к данному примеру такой прием дает решение, приведенное на рисунке 3.20.

Рисунок 3.20. Элиминация отношения "многие ко многим” с помощью введения дополнительной сущности
На первый взгляд, модели на рисунке 3.19 и 3.20 выглядят семантически эквивалентными, однако это не так — здесь есть тонкое различие. В случае использования класса ассоциации Job, который по определению является множеством пар должность-сотрудник, не может быть двух одинаковых пар. То есть не может быть так, чтобы Новиков занимал полставки доцента и еще (отдельно) четверть той же ставки. В случае же промежуточного класса Job это, вообще говоря, вполне возможно, что не совсем естественно. Опытные проектировщики баз данных нам могут возразить, что это вполне поправимо: нужно ввести в классах Position и Person атрибуты, которые будут уникальными ключами, идентифицирующими объекты этих классов, а в классе Job ввести пару атрибутов, значениями которых будут ключи классов Position и Person и потребовать, чтобы эта пара атрибутов была уникальным составным ключом класса Job.
Чаще всего используются бинарные ассоциации, отражающие связи между объектами двух классов. В UML определены также многополюсные ассоциации, отражающие связи между большим числом объектов. С формальной точки зрения многополюсные ассоциации излишни, поскольку их можно выразить через комбинацию бинарных ассоциаций введением дополнительных сущностей. Действительно, упорядоченную тройку объектов (a, b, с) — элемент трехполюсной ассоциации — можно представить как упорядоченную пару (a, d), где d — новый объект, представляющий упорядоченную пару (b, с). Однако на практике (в некоторых случаях) многополюсные ассоциации бывают буквально незаменимы. Рассмотрим следующий пример из информационной системы отдела кадров. Допустим, что в организации применяется современная организационная форма управления и помимо иерархии подразделений и должностей существует структура выполняемых проектов, "пронизывающих" организацию.
Один и тот же сотрудник может участвовать во многих проектах, выполняя различные обязанности (т. е. занимая различные должности), в каждом проекте (частично) заняты многие сотрудники и размер оплаты труда зависит от того, сколько конкретно времени проработал данный сотрудник в данной должности в данном проекте. Такую замысловатую (но весьма жизненную!) ситуацию очень легко отобразить, используя многополюсные ассоциации и классы ассоциации (Рисунок 3.21). Чтобы полностью оценить полезность многополюсных ассоциаций и классов ассоциаций, мы советуем читателям проделать весьма поучительное упражнение: попытаться построить модель, семантически эквивалентную модели на рисунке 3.21, но не использующую многополюсных ассоциаций и классов ассоциаций (подсказка: придется ввести дополнительные сущности и отношения).
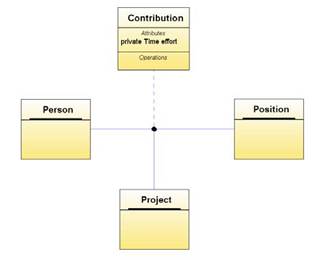
Рисунок 3.21. Многополюсная ассоциация
Обобщим сказанное с помощью диаграммы метамодели ассоциации, представленной на рисунке 3.22.
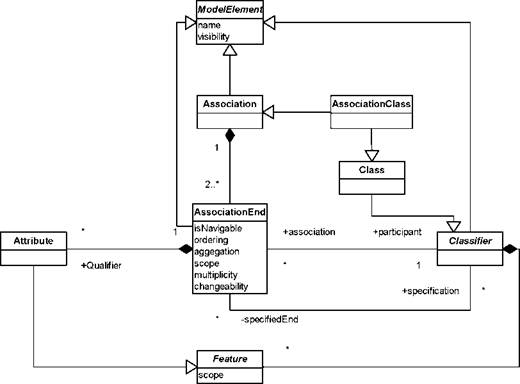 |
Рисунок 3.22. Метамодель ассоциации
В UML имеется несколько частных случаев классификаторов, которые, подобно классам, предназначены для моделирования структуры, но обладают рядом специфических особенностей. Наиболее важными их них являются интерфейсы.
Интерфейс — это именованный набор абстрактных операций.
Другими словами, интерфейс — это абстрактный класс, в котором нет атрибутов и все операции абстрактны. Поскольку интерфейс — это абстрактный класс, он не может иметь непосредственных экземпляров.
Между интерфейсами и другими классификаторами, в частности классами, на диаграмме классов применяются два отношения:
- классификатор (в частности, класс) использует интерфейс — это показывается с помощью зависимости со стереотипом «call»;
- классификатор (в частности, класс) реализует интерфейс — это показывается с помощью отношения реализации.
Никаких ограничений на использование отношения реализации не накладывается: класс может реализовывать много интерфейсов, и наоборот, интерфейс может быть реализован многими классами. Нет ограничений и на использование зависимостей со стереотипом «call» — класс может вызывать любые операции любых видимых интерфейсов. Семантика зависимости со стереотипом «call» очень проста — эта зависимость указывает, что в операциях класса, находящегося на независимом полюсе, вызываются операции класса (в частности, интерфейса) находящегося на зависимом полюсе.
Разобравшись с интерфейсами, их реализацией и использованием, нам представляется уместным еще раз повторить определение понятия роли.
Роль — это интерфейс, который предоставляет классификатор в данной ассоциации.
Продолжая пример информационной системы отдела кадров, начатый на рисунке 3.13, дополним его иллюстрацией использования зависимости со стереотипом «call». Допустим, что класс Department для реализации операций связанных с движением кадров, использует операции класса Position, позволяющие занимать и освобождать должность — другие операции класса Position классу Department не нужны. Для этого, как показано на рисунке 3.23 можно определить соответствующий интерфейс IPosition и связать его отношениями с данными классами.
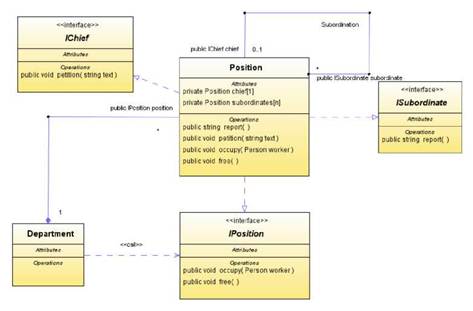
Рисунок 3.23. Отношения реализации и использования интерфейсов
Используя нотацию «чупа-чупс», появившуюся в UML 2.0, эту же модель можно изобразить лаконично, симметрично и просто, как показано на рисунке 3.24.
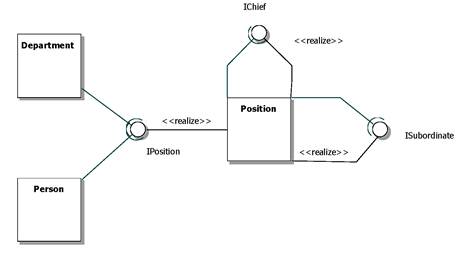
Рисунок 3.24. Использование нотации «чупа-чупс»
UML не является сильно типизированным языком: например, в модели можно указывать типы атрибутов классов и параметров операций, но это не обязательно. Инструмент может проверять соответствие типов, если они указаны, но не обязан этого делать. (Контроль типов — еще один пример точки вариации семантики в языке). Такое решение принято в расчете на то, что UML используется совместно с разными языками программирования, использующими различные концепции типизации и типового контроля, и навязывание одной конкретной модели ограничило бы применение UML.
Здесь уместно дать точные ответы на два важных вопроса.
- Для каких элементов модели можно указать тип?
- Что можно использовать в качестве указания типа?
В UML типизированы могут быть:
- атрибуты классов, в том числе классов ассоциаций;
- параметры операций, в том числе тип возвращаемого значения;
- роли полюсов ассоциаций;
- квалификаторы полюсов ассоциаций;
- параметры шаблонов.
Ответ на второй вопрос — что же можно указать в качестве типа — с одной стороны, очень лаконичен, а, с другой стороны, требует дополнительного обсуждения. Лаконичный ответ звучит так: тип указывается с помощью классификатора. Обсудим это определение. Если типы составляющих одного классификатора указываются с помощью других классификаторов, то возможны два варианта: либо мы имеем замкнутую систему взаимно рекурсивных определений, которые не нуждаются ни в каких внешних сущностях, либо мы имеем некоторый набор заранее определенных классификаторов, которые используются как базовые для определения остальных.
Первый подход (абсолютно все определяется в рамках одной системы) кажется соблазнительным, но, к сожалению, он никуда не ведет. Мы сошлемся на авторитет: в распространенных языках программирования так не делают.
В UML, также как в распространенных языках программирования и других формальных системах, имеется набор базовых классификаторов, с помощью которых определяются типы элементов модели, в частности типы составляющих других классификаторов. Это типы данных.
В модели UML можно использовать три вида типов данных:
- Примитивные типы, которые считаются предопределенными в UML — таковых, как минимум, три: строка, целое число и значение даты/времени. Инструменты вправе расширять этот набор и использовать подходящие названия.
- Типы данных, которые определены в языке программирования, поддерживаемым инструментом. Это могут быть как названия встроенных типов, так и сколь угодно сложные выражения, доставляющие тип, если таковые допускаются языком.
- Типы данных, которые определены в модели. В стандарте UML предусмотрен только один конструктор типов данных: перечислимый тип, который определяется с помощью стереотипа «enumeration».
В частности, тип Boolean определен в UML как перечислимый тип со значениями true и false. Приведем пример: допустим, в нашем приложении нужно использовать не обычную двузначную логику, а трехзначную. Тогда соответствующий можно определить так, как показано на рисунке 3.25.

Рисунок 3.25. Перечислимый тип данных «Трехзначная логика»
Наряду со стандартным стереотипом «enumeration» многие инструменты допускают использование стереотипа «datatype», который означает построение типа данных с помощью не специфицированного конструктора типов.
Возникает вопрос: чем же типы данных отличаются от прочих классификаторов UML?
Тип данных (в UML) — это классификатор, экземпляры которого не обладают индивидуальностью (identity).
Это довольно тонкое понятие, которое мы попробуем объяснить на примере. Рассмотрим какой-нибудь встроенный тип данных в обычном языке программирования, например, тип integer в языке Паскаль. Значения этого типа (экземпляры классификатора) изображаются обычным образом, например, 3. Что будет, если число "три" используется в нескольких местах программы? Отличатся ли чем-нибудь экземпляры изображения 3? Очевидно, нет. Экземпляры типа integer не обладают индивидуальностью, мы вправе считать, что написанные в разных местах изображения числа 3 суть одно и то же число, а компилятор вправе использовать для хранения представления числа "три" одну и ту же ячейку, сколько бы изображений числа 3 ни присутствовало в программе.
Далее, программисту не нужно предусматривать никаких инициализирующих действий, для того, чтобы воспользоваться числом 3 — не нужно определять никаких объектов, не нужно вызывать никаких конструкторов. Можно считать, что все значения типа данных уже определены и всегда существуют, независимо от программы. Более того, с числом "три" ничего не может случиться — чтобы ни происходило в программе, число "три" останется числом "три" и никогда не станет числом " пять".
Сопоставим сказанное с обычным классом, экземпляры которого обладают индивидуальностью. Допустим, в классе Cinteger есть только один атрибут, который хранит целое значение. На первый взгляд, такой класс ничем не отличается от типа данных integer — экземпляры данного класса вполне можно использовать как целые числа. Но это поверхностное впечатление: между типом данных integer и классом Cinteger много существенных отличий.
Во-первых, экземпляры класса Cinteger должны быть явно созданы и инициализированы, прежде чем их можно будет использовать в программе. Во-вторых, экземпляр класса Cinteger, который в данный момент хранит число "три", через некоторое время выполнения программы может хранить число "пять", оставаясь при этом тем же самым экземпляром, поскольку он обладает индивидуальностью. В- третьих, в программе может быть определено несколько экземпляров класса Cinteger, которые хранят одно и то же число "три" и это будут разные объекты (компилятор разместит их в разных областях памяти), поскольку они обладают индивидуальностью.
Отсутствие индивидуальности экземпляров типа данных влечет некоторые общепринятые ограничения на операции типа данных:
- Областью действия операций типа всегда является классификатор, а не экземпляр (в модели они подчеркнуты, Рисунок 3.24).
- Операции типа данных всегда обладают свойством isQuery.
- Операции типов данных считаются не повторно входимыми и обладают свойством sequential.
Еще одной сущностью, специфической для диаграмм классов, являются шаблоны. Шаблон — это класс с параметрами. Параметром может быть любой элемент описания класса — тип составляющей, кратность атрибута и т. д. На диаграмме шаблон изображается с помощью прямоугольника класса, к которому в правом верхнем углу присоединен пунктирный прямоугольник с параметрами шаблона. Описания параметров перечисляются в этом прямоугольнике через запятую. Описание каждого параметра имеет вид:
ИМЯ: тип
Сам по себе шаблон не может непосредственно использоваться в модели. Для того, чтобы на основе шаблона получить конкретный класс, который может использоваться в модели, нужно указать явные значения аргументов. Такое указание называется связыванием.
В UML применяются два способа связывания:
- явное связывание — зависимость со стереотипом «bind», в которой указаны значения аргументов;
- неявное связывание — определение класса, имя которого имеет формат имя_шаблона < аргументы >
Рассмотрим пример (Рисунок 3.26). Здесь определен шаблон Array, имеющий два параметра: n типа Integer и T, тип которого не указан. Этот шаблон применяется для создания массивов определенной длины, содержащих элементы определенного типа. В данном случае с помощью явного связывания определен класс Triangle как массив из трех элементов типа Point. С помощью неявного связывания определен аналогичный по смыслу класс с именем Array<3,Point>.
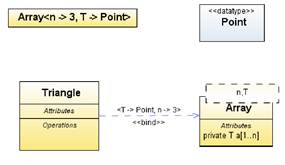
Рисунок 3.26. Связывание шаблона: неявное (вверху), явное (внизу)
Назначение и область применения шаблонов понятны — шаблоны нужны, чтобы определить некоторую общую параметрическую конструкцию класса один раз, и затем использовать ее многократно, подставляя конкретные значения аргументов. Явное связывание более наглядно, неявное связывание менее наглядно, зато записывается короче.
Как видно из предыдущих разделов, диаграммы классов содержат множество деталей. Для практически значимых систем диаграммы классов в конечном итоге получаются довольно сложными. Пытаться прорисовать сложную диаграмму классов сразу "на всю глубину" нерационально — слишком велик риск "утонуть" в деталях. Удачная модель структуры сложной системы создается за несколько (может быть даже за несколько десятков) итераций, в которых моделирование структуры перемежается моделированием поведения.
Удобнее:
- Описывать структуру удобнее параллельно с описанием поведения. Каждая итерация должна быть небольшим уточнением как структуры, так и поведения.
- Не обязательно включать в модель все классы сразу. На первых итерациях достаточно идентифицировать очень небольшую (10%) долю всех классов системы.
- Не обязательно определять все свойства класса сразу. Начните с имени — операции и атрибуты постепенно выявятся в процессе моделирования поведения.
- Не обязательно показывать на диаграмме все свойства класса. В процессе работы диаграмма должна легко охватываться одним взглядом.
- Не обязательно определять все отношения между классами сразу. Пусть класс на диаграмме "висит в воздухе" — ничего с ним не случится.

