 2015-04-01
2015-04-01 1384
1384Моделируя структуру, мы описываем составные части системы и отношения между ними. UML является объектно-ориентированным языком моделирования, поэтому не удивительно, что основным видом составных частей, из которых состоит система, являются объекты. В каждый конкретный момент функционирования системы можно указать конечный набор конкретных объектов и связей между ними, образующих систему. Однако в процессе работы этот набор не остается неизменным: объекты создаются и уничтожаются, связи устанавливаются и теряются. Число возможных вариантов наборов объектов и связей, которые могут иметь место в процессе функционирования системы, если и не бесконечно, то может быть необозримо велико. Представить их все в модели практически невозможно, а главное бессмысленно, поскольку такая модель из-за своего объема будет недоступна для понимания человеком, а значит бесполезна при разработке системы. Каким же образом можно строить компактные (полезные) модели необозримых (потенциально бесконечных) систем?
Метод построения конечных (и небольших) моделей бесконечных (или очень больших) систем давно известен человечеству и пронизывает всё современное знание в разных формах и под разными названиями. Сами правила и способ их задания различны в разных случаях, но принцип один и тот же.
В UML этот принцип формализован в виде понятия дескриптора. Дескриптор имеет две стороны: это само описание множества (intent) и множество значений, описываемых дескриптором (extent). Антонимом для дескриптора является понятие литерала. Литерал описывает сам себя. Например, тип данных integer является дескриптором: он описывает множество целых чисел, потенциально бесконечное (или конечное, но достаточно большое, если речь идет о машинной арифметике). Изображение числа 1 описывает само число "один" и более ничего — это литерал. Почти все элементы моделей UML являются дескрипторами — именно поэтому средствами UML удается создавать представительные модели достаточно сложных систем. Рассмотренные в предыдущей главе варианты использования и действующие лица — дескрипторы, рассматриваемые в этой главе классы, ассоциации, компоненты, узлы — также дескрипторы. Примечание же является литералом — оно описывает само себя.
Рассмотрим более детально, какие именно структуры нужно моделировать и зачем. Выделим следующие структуры:
• структура связей между объектами во время выполнения программы;
• структура хранения данных;
• структура программного кода;
• структура компонентов в приложении;
• структура используемых вычислительных ресурсов;
• структура сложных объектов, состоящих из взаимодействующих частей;
• структура артефактов в проекте.
В этом разделе кратко мы обсудим назначение перечисленных структур и укажем средства UML, предназначенные для их моделирования.
Структура связей между объектами во время выполнения программы. В парадигме объектно-ориентированного программирования процесс выполнения программы состоит в том, что программные объекты взаимодействуют друг с другом, обмениваясь сообщениями. Наиболее распространенным типом сообщения является вызов метода объекта одного класса из метода объекта другого класса. Для того чтобы вызвать метод объекта, нужно иметь доступ к этому объекту. На уровне программной реализации этот доступ может быть обеспечен самыми разнообразными механизмами. Например, в объекте содержащем вызывающий метод может хранится указатель (ссылка) на объект, содержащий вызываемый метод. Еще вариант: ссылка на объект с вызываемым методом может быть передана в качестве аргумента вызывающему методу. Возможно, используется какой-либо системный механизм удаленного вызова процедур, обеспечивающий доступ к объектам (например, такие как CORBA или DCOM) по идентификаторам. Если свойства объектов представлены записями в таблице базы данных, а методы — хранимыми процедурами СУБД (нередкий вариант реализации), то идентификация объектов осуществляется по первичному ключу таблицы. Как бы то ни было, во всех случаях имеет место следующая ситуация: один объект "знает" другие объекты и, значит, может вызвать открытые методы, использовать и изменять значения открытых свойств и т. д. В этом случае, мы говорим что объекты связаны, т. е. между ними есть связь. Для моделирования структуры связей в UML используются отношения ассоциации на диаграмме классов.
Структура хранения данных. Программы обрабатывают данные, которые хранятся в памяти компьютера. В парадигме объектно-ориентированного программирования для хранения данных во время выполнения программы предназначены свойства объектов, которые моделируются в UML атрибутами классов. Однако большая часть приложений для автоматизации делопроизводства устроена так, что определенные данные (не все) должны хранится в памяти компьютера не только во время сеанса работы приложения, но постоянно, т. е. между сеансами. Объекты, которые сохраняют (по меньшей мере) значения своих свойств даже после того, как завершился породивший их процесс, мы будем называть хранимыми. В UML для моделирования данного свойства объектов и их составляющих применяется стандартное именованное значение persistence, которое может быть назначено классификатору, ассоциации или атрибуту и может принимать одно из двух значений:
• persistent — экземпляры классификатора, ассоциации или значения атрибута, соответственно, должны быть хранимыми;
• transient — противоположно предыдущему — сохранять экземпляры не требуется (значение по умолчанию).
В настоящее время самой распространенным способом хранения объектов является использование системы управления базами данных (СУБД). При этом хранимому классу соответствует таблица базы данных, а хранимый объект (точнее говоря, набор значений хранимых атрибутов) представляется записью в таблице. Вопрос структуры хранения данных является первостепенным для приложений баз данных. К счастью, известны надежные методы решения этого вопроса. Эти же методы (с точностью до обозначений) применяются и в UML в форме ассоциаций с указанием кратности полюсов.
Структура программного кода. Не секрет, что программы существенно отличаются по величине. Столь большие количественные различия не могут не проявляться и на качественном уровне. Действительно, для маленьких программ структура кода практически не имеет значения, для больших — наоборот, имеет едва ли не решающее значение. Поскольку UML не является языком программирования, модель не определяет структуру кода непосредственно, однако косвенным образом структура модели существенно влияет на структуру кода. Большинство инструментов поддерживает полуавтоматическую генерацию кода для одного или нескольких объектноориентированных языков программирования. В большинстве случаев классы модели транслируются в классы (или эквивалентные им конструкции) целевого языка. Кроме того, многие инструменты учитывают структуру пакетов в модели и транслируют ее в соответствующие "надклассовые" структуры целевой системы программирования. Таким образом, если задействовано средство автоматической генерации кода, то структура классов и пакетов в модели фактически полностью моделирует структуру кода приложения.
Структура сложных объектов, состоящих из взаимодействующих частей. Для моделирования этой структуры применяется новое средство UML 2 — диаграмма внутренней структуры классификатора. Мы не рассматриваем такие структуры в нашем сквозном примере детально, а потому ограничимся одним примером, приведенным на рисунке 3.1.
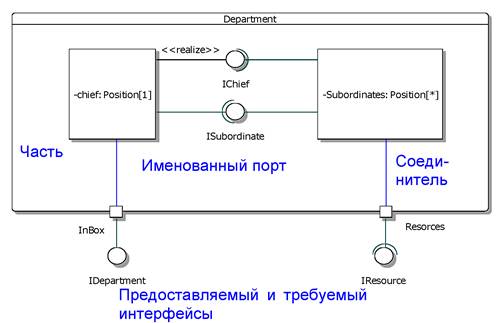
Рисунок 3.1 Диаграмма внутренней структуры классификатора
На диаграмме внутренней структуры классификатора показывается классификатор, внутри которого имеются части. Частей может быть несколько. Каждая часть является экземпляром некоторого друго классификатора. Части могут взаимодействовать друг с другом. Это обозначается с помощью соединителей. Если нужно показать взаимодействие с внешним миром, то на кранице структурированного классификатора изображается именованный порт.
Структура артефактов в проекте. Только самые простые приложения состоят из одного артефакта — исполнимого кода программы. Большинство насчитывает в своем составе десятки, сотни и тысячи различных компонентов: исполнимых двоичных файлов, файлов ресурсов, исходного кода, различных сопровождающих документов, справочных файлов, файлов с данными и т. д. Для большого приложения важно не только иметь точный полный список всех артефактов, но и указать, какие именно компоненты входят в конкретный экземпляр системы. Дело в том, что для больших приложений в проекте сосуществуют разные версии одной и той же компоненты. Это исчерпывающим образом моделируется диаграммами компонентов UML, где предусмотрены стандартные стереотипы для описания компонентов разных типов.
Структура компонентов в приложении. Приложение, состоящее из одной исполнимой компоненты, имеет тривиальную структуру компонентов, моделировать которую нет нужды. Но большинство современных приложений состоят из многих компонентов, даже если и не являются распределенными. Компонентная структура предполагает описание двух аспектов: во-первых, как классы распределены по компонентам, во-вторых, как (через какие интерфейсы) компоненты взаимодействуют друг с другом. Оба эти аспекта моделируются диаграммами компонентов UML.
Структура используемых вычислительных ресурсов. Многокомпонентное приложение, как правило, бывает распределенным, т. е. различные компоненты выполняются на разных компьютерах. Диаграммы размещения и компонентов позволяют включить в модель описание и этой структуры.
Важнейшим типом дескрипторов являются классификаторы. Классификатор — это дескриптор множества однотипных объектов. Из этого определения непосредственно вытекает основное и характеристическое свойство классификатора: классификатор (прямо или косвенно) может иметь экземпляры.
В UML используются следующие классификаторы:
• класс;
• интерфейс;
• тип данных;
• узел;
• компонент;
• действующее лицо;
• вариант использования;
• подсистема.
Все классификаторы имеют некоторые общие свойства, которые мы опишем в этом разделе и будем использовать в дальнейшем.
Во-первых, классификаторы (как и все элементы модели) имеют имена. Имя служит для идентификации элемента модели и потому должно быть уникально в данном пространстве имен. Классификатор может быть абстрактным (т. е. не могущим иметь прямых экземпляров) и в этом случае его имя выделяется курсивом. Классификатор может быть конкретным (может иметь прямые экземпляры) и в этом случае его имя записывается прямым шрифтом. Во-вторых, как уже было сказано, классификатор может иметь экземпляры. Экземпляры бывают прямые и косвенные.
Если некоторый объект непосредственно порожден с помощью конструктора классификатора А, то этот объект называется прямым экземпляром А.
Если классификатор А является обобщением классификатора В или если классификатор В является реализацией классификатора А, то все экземпляры классификатора В являются косвенными экземплярами классификатора А.
Данное свойство является транзитивным: если классификатор В является обобщением классификатора С, то все экземпляры С также являются косвенными экземплярами А. Именно это обстоятельство позволяет рассматривать абстрактные классификаторы. Действительно, абстрактный классификатор — это такой дескриптор множества объектов, в котором нет прямого описания элементов множества, но данный классификатор связан отношением обобщения с другими классификаторами и объединение множеств их экземпляров считается множеством экземпляров данного абстрактного классификатора. Другими словами, множество определяется не прямо, а через совокупность подмножеств. Например, интерфейс, будучи абстрактным классом, не может иметь непосредственных экземпляров, но реализующий его класс может, стало быть, интерфейс является классификатором. В-третьих, классификатор (как и другие элементы модели) имеет видимость.
Видимость определяет, может ли свойство одного классификатора (в том числе имя) использоваться в другом классификаторе.
Другими словами, если в определенном контексте нечто доступно и может быть как-то использовано, то оно является видимым (в этом контексте). Если же оно не видимо, то и не может быть использовано. Видимость является свойством всех элементов модели (хотя не для всех элементов это свойство является существенным). Видимость может иметь одно из трех значений:
• открытый (обозначается знаком + или ключевым словом public);
• защищенный (обозначается знаком # или ключевым словом protected);
• закрытый (обозначается знаком - или ключевым словом private).
Открытый элемент модели является видимым везде, где является видимым содержащий его контейнер. Например, открытый атрибут класса виден везде, где виден сам класс.
Защищенный элемент модели виден в своем контейнере и во всех контейнерах, для которых данный является обобщением. Например, защищенный атрибут класса виден в этом классе и во всех наследующих классах.
Закрытый элемент модели виден только в своем контейнере. Например, закрытый атрибут класса виден только в этом классе.
В-четвертых, все составляющие классификатора имеют область действия.
Область действия определяет, как проявляет себя составляющая классификатора в экземплярах, т. е. имеют экземпляры свои значения составляющей или совместно используют одно значение.
Область действия имеет два возможных значения:
• экземпляр — никак специально не обозначается, поскольку подразумевается по умолчанию;
• классификатор — описание составляющей классификатора подчеркивается.
Если областью действия составляющей является экземпляр, то каждый экземпляр классификатора имеет свое значение составляющей. Например, областью действия атрибута по умолчанию является экземпляр. Это означает, что каждый объект — экземпляр класса — имеет свое собственное значение атрибута, которое может меняться независимо от значений данного атрибута других объектов, экземпляров этого же класса. Если областью действия составляющей является классификатор, то все экземпляры классификатора совместно используют одно значение составляющей. Например, конструктор обычно имеет областью действия классификатор, поскольку является процедурой, общей для всех создаваемых объектов.
В-пятых, классификатор имеет кратность, т. е. ограничение на количество экземпляров. Возможны следующие варианты.
• У классификатора нет экземпляров — такой классификатор называется службой. Все составляющие службы имеют областью действия классификатор. Хранение информации, обрабатываемой службой, обеспечивают объекты использующие службу. Типичный пример — набор процедур общего пользования, скажем, библиотека математических функций. Службы используются в приложениях достаточно часто, поэтому есть даже стандартный стереотип (utility), определяющий класс как службу.
• Классификатор имеет ровно один экземпляр. Такой классификатор называется одиночкой. В сущности, между службой и одиночкой различия незначительны, но иногда одиночку использовать удобнее, например, для хранения глобальных переменных приложения.
• Классификатор имеет фиксированное число экземпляров. Такой вариант не часто, но встречается. Например, порты в концентраторе.
• По умолчанию классификатор имеет произвольное число экземпляров. Поскольку этот вариант встречается чаще всего, он никак специально не указывается.
В-шестых, классификаторы (и только они!) могут участвовать в отношении обобщения обобщение.
Сказанное в этом разделе мы закончим диаграммой классов из метамодели UML, описывающей понятие классификатора (Рисунок 3.2)
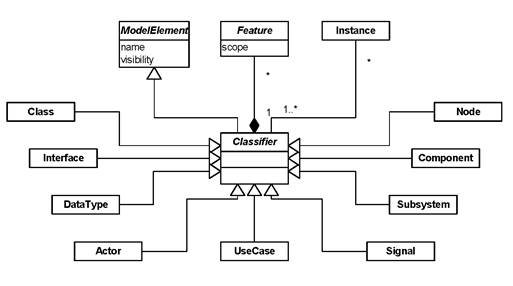
Рисунок 3.2 Метамодель классификатора
Прежде чем переходить к технике описания классов полезно обсудить вопрос, как выделяются классы, подлежащие описанию. По этому вопросу в литературе приводится множество соображений, советов, рекомендаций и даже принципов. Само разнообразие подходов свидетельствует о том, что среди них нет универсального и применимого во всех случаях. Мы выбрали три приема выделения классов, самых простых (можно сказать, даже примитивных), а потому, по нашему мнению, самых действенных и широко применимых:
• словарь предметной области;
• реализация вариантов использования;
• образцы проектирования.
Словарь предметной области - это набор основных понятий (сущностей) данной предметной области
Рассмотрите внимательно текст технического задания (или иного документа, лежащего в основе проекта) и выделите в содержательной части имена существительные — все они являются кандидатами на то, чтобы быть названиями классов (или атрибутов классов) проектируемой системы. Разумеется, после этой простой операции к полученному списку нужно применить фильтр здравого смысла и опыта, отсекая ненужное.
Рассмотрим пример информационной системы отдела кадров. В тексте технического задания первый вводный абзац можно отбросить сразу — это общие слова. Суть заключена в нумерованных пунктах. Но в этом тексте вообще все слова являются существительными (кроме союзов). Выпишем их в том порядке, как они встречаются, но без повторений:
• прием;
• перевод;
• увольнение;
• сотрудник;
• создание;
• ликвидация;
• подразделение;
• вакансия;
• сокращение;
• должность.
Заметим, что некоторые их этих слов по сути являются названиями действий (и по форме являются отглагольными существительными). Фактически, это глаголы, замаскированные особенностями родного языка. Это ясно видно, если переписать текст технического задания в форме простых утверждений.
Отбросим замаскированные глаголы. Таким образом, остается список из четырех слов:
сотрудник,
подразделение;
вакансия;
должность.
При анализе технического задания мы отметили (опираясь на знание предметной области), что вакансия — это должность в особом состоянии. Таким образом, это слово в списке лишнее и у нас остались три кандидата, которые мы оставляем в словаре (и заодно присваиваем им английские идентификаторы).
• Сотрудник (Person);
• Подразделение (Department);
• Должность (Position).
Рассмотрим теперь, как выявляются классы в процессе реализации вариантов использования. Если при реализации вариантов использования применяются диаграммы взаимодействия, то в этом процессе в качестве побочного эффекта выделяются некоторые классы непосредственно, поскольку на диаграммах кооперации и последовательности основными сущностями являются объекты, которые по необходимости нужно отнести к определенным классам. Использование диаграмм деятельности также может подсказать, какие классы нужно определить в системе, особенно если на диаграмме деятельности указывается поток объектов. Однако, если сценарии вариантов использования описываются на псевдокоде, то выделить классы значительно труднее. Фактически, если варианты использования реализуются на псевдокоде или диаграммами деятельности вне связи с объектами, то выявление объектной структуры системы просто откладывается "на потом". Иногда это может быть вполне оправдано — например, архитектор, моделирующий систему, прежде чем начать проектирование основной структуры классов, хочет более глубоко вникнуть в логику бизнес-процессов незнакомой ему предметной области.
Обсудим это на примере информационной системы отдела кадров. Реализация вариантов использования SelfFire и AdmFire не дает практически никакой информации для выделения классов. Появление двух новых существительных ("приказ" и "заявление") наталкивает на мысль, что в системе может появиться класс Document, но сразу ясно, что это класс будет пассивным хранилищем информации, не наделенным собственным поведением и это полезное наблюдение никак не приближает к решению основной задачи: выявить ключевые классы в системе. Реализация варианта использования HirePerson с помощью диаграмм деятельности существенно углубляет наши знания о процессе приема на работу, но никак не приближает нас к структуре классов приложения. Наиболее значительный прогресс в этом направлении дают диаграммы последовательности и взаимодействия для этого же варианта использования. Два класса — Person и Position — те же, что нам подсказал анализ словаря предметной области. Очевидно, что если одни и те же выводы получены разными способами, доверие к ним возрастает. Полезный класс ExceptionHandler, однако, вряд ли мог появиться из словаря: описывая предметную область, люди склонны закрывать глаза на возможные ошибки, исключительные ситуации и прочие неприятности. Особого обсуждения заслуживает появление класса HireForm.
На самом деле этот класс появился в модели как результат применения образца проектирования.
Образец проектирования — это стандартное решение типичной задачи в конкретном контексте.
Синтаксически образец в UML является кооперацией, роли объектов в которой рассматриваются как параметры, а аргументами являются конкретные классы модели. В данном случае применен образец View-Model Separation, который предполагает, что класс, ответственный за интерфейс с пользователем не должен прямо манипулировать данными, а класс, ответственный за хранение и обработку данных, не должен содержать интерфейсных элементов. Таким образом, класс HireForm появился как недостающий аргумент кооперации View-Model Separation.

