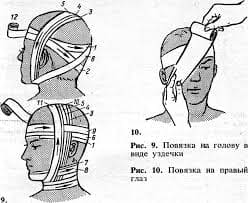
2015-04-01
2015-04-01 781
781Рассмотрим компонент понимания высказывания. Под смыслом высказывания обычно понимается вся та семантико-прагматическая информация, которую пользователь хотел бы передать системе. Внутренне представление смысла должно содержать по крайней мере, следующую информацию: сущности проблемной области, вовлекаемые в зону рассмотрения данным высказыванием; свойства и отношения, приписанные этим сущностям; коммуникативные намерения говорящего, выраженные в данном высказывании. Выявление смысла высказывания в общем случае требует его рассмотрения в контексте всего диалога.
Традиционно задача понимания высказывания подразделяется на два этапа: анализ и интерпретацию.
На этапе анализа выделяются описания сущностей, упомянутых во входном высказывании, выявляются свойства этих сущностей и отношения между ними. Анализаторы, разрабатываемые для ЕЯ-систем, различаются по следующим параметрам:
1.Тип анализируемых предложений. Сюда относятся повествовательные, вопросительные, отрицательные, полные, неполные, простые, сложные, распространенные, нераспространенные и др.
2. Выделяемые описания сущностей. Выделяют:
понятия – конкретные, абстрактные, метапонятия;
отношения – предикаты: вспомогательные, предикаты-состояния, предикаты-действия, функциональные, и др.;
кванторы, модальности;
прессупозиции– семантические, прагматические, экзистенциальные. Отсутствие прессупозиций.
3. Глубина проникновения в смысл (множество ключевых слов, имя события и описания участников события, их роли и характеристики, сценарий с отсылкой к связанным подсценариям, пространственно-временное или причинно-следственное представление ситуации)
4. Используемые для анализа средства (морфологический, синтаксический, прагматический анализ).
В методах анализа обычно выделяют анализ слов, предложений и текстов.
А) Анализ слов сводится к морфологическому анализу и обнаружению и исправлению орфографических ошибок. Цель морфологического анализа состоит в получении основ (словоформ с отсеченным окончанием) со значениями грамматических категорий (например, часть речи, род, число, падеж) для каждой из словоформ высказывания, поступившего на вход ЕЯ-системы. Примеры отечественных ЕЯ –систем с достаточно полной реализацией морфологического анализа: ПОЭТ (Попов Э.В.), ТULIPS (Мальковский М.Г, МГУ), АИСТ (Дракин В.И.) и др.
Методы обнаружения и исправления орфографических ошибок подразделяются на два класса в зависимости от того, используют ли они словари основ или нет. К методам, не использующим словари, относятся частотные и полигамные. Частотные методы основаны на сортировке слов по частоте их встречаемости в текстах. Предполагается, что частота встречаемости слов, содержащих ошибки, низкая. Однако, низкая частота встречаемости и у правильных, но редко встречающихся слов. Это снижает эффективность частотных методов. В полигамных методах для поиска ошибок применяют списки возможных сочетаний букв в словах. Обычно анализируются пары и тройки идущих подряд букв. Полигамными методами целесообразно пользоваться в системах с открытым словарем.
Методы, в которых используются словари, разделяются в зависимости от типа стратегии на абсолютные и относительные. К абсолютным относится “исторический” метод, основанный на словаре встречаемых ранее ошибок. Эффективность этого метода существенно зависит от размера текстов, на основе которых порожден словарь ошибок. Относительный метод состоит в нахождении в словаре слов, наиболее похожих на анализируемое. Обычно искаженное слово подвергается определенной обработке для получения из него правильных слов. Обработка включает действия по пропуску, переноске и вставке букв. При этом для уменьшения списка новых слов применяют частотные и полигамные методы.
Б) Анализ предложений обычно сводится к синтаксическому и семантическому анализу. Наиболее распространенные методы анализа предложений были разработаны еще при создании первых ЕЯ- систем и предназначались для обработки только правильных, т.е. не содержащих отклонений от грамматической нормы предложений. Эти методы аналогичны методам обработки искусственных языков. Однако, с точки зрения требований к современным ЕЯ- системам, важным является вопрос о том, насколько существующие анализаторы могут быть приспособлены к обработке “неграмматичностей”, т.е. характерных для диалогов между людьми высказываний с отклонениями от грамматической нормы. Это: лексические и грамматический ошибки, пропуски, повторы, шумы, и т.д. Различают следующие типы ЕЯ-анализаторов: традиционные, концептуальные, использующие сопоставление по образцу, использующие разнообразные стратегии.
Традиционные анализаторы используют разбор предложений сверху вниз, слева направо, основанный на некоторой фиксированной грамматике. Анализаторы этого типа осуществляют разбор предложения либо в общих грамматических категориях, либо в терминах категорий, имеющих значение в некоторой ограниченной области. Данные анализаторы очень хрупки и терпят неудачу при разборе предложений с малейшими отклонениями от нормы. Один из возможных подходов к преодолению хрупкости традиционных анализаторов состоит в одновременном применении нескольких подграмматик. Каждая из них предназначена для анализа частных конструкций какого-то одного вида. Применение подграмматик осуществляется независимо, поэтому неудача одной грамматики не влияет на возможности других. При данном подходе, предложение в процессе анализа разбивается на несколько независимых фрагментов. В этом случае в задачу анализатора входит построение объединенной интерпретации предложения. Если проблемная область достаточно ограничена, то интерпретация фрагментов всегда уникальна, однако в общем случае эта задача не имеет единственного решения и может стать трудно разрешимой.
Концептуальные анализаторы используют методы разбора, направляемые значениями базовых событий, обнаруженных в анализируемых предложениях. Различают анализаторы основанные на модели концептуальной зависимости (Шенк) и на модели управления (Апресян). Заложенные в них идеи позволяют реализующим их алгоритмам работать в условиях пропусков и повторов слов. Концептуальные анализаторы игнорируют непонятные им слова, а понятные (даже с ошибками) приспосабливают к базовым событиям обрабатываемого предложения.
Анализаторы, использующие сопоставление по образцу. Анализ в данном случае сводится к сопоставлению предложения с некоторым множеством шаблонов, представляющих последовательности из одного или нескольких слов. Шаблоны могут содержать переменные и могут сопоставляться с любой строкой символов. Гибкость анализаторов определяется гибкостью процесса сопоставления. Разнообразие форм сопоставления позволяет анализировать входные предложения, отклоняющиеся от традиционной грамматики, однако глубина проникновения в смысл обычно невелика.
Последние исследования показали, что использование в одном анализаторе нескольких специфических методов позволяет обеспечить гибкость процесса анализа, необходимую для обработки неграмматических конструкций.
В) Анализ текстов. Связность текста (дискурса) достигается как лингвистическими средствами, так и ситуационными средствами – умолчаниями, не имеющими языкового выражения и основанными на общности знаний коммуникантов о цели общения и проблемной области. На этапе анализа связного текста, обычно решается задача выявления связей между предложениями, выражаемых лингвистическими средствами, а на этапе интерпретации – ситуационными.
К основным лингвистическим средствам связи предложений относятся ссылки и эллипсис. При установлении ссылок выделяются две задачи: поиск в предыдущих предложениях (контексте) референта, обозначаемого данной ссылкой и определение соответствия между референтом и ссылкой. Отсутствие критерия для определения количества просматриваемых предыдущих предложений приводит на практике как к увеличению времени поиска, так и к ошибкам в установлении ссылок. Решение второй задачи тривиально в случае тождества референта и ссылки и весьма трудно при их несовпадении. Отсутствие хороших методов решения обеих задач на этапе анализа текста стимулировало попытки их решения на этапе интерпретации.
Задача обработки эллиптических конструкций решается на этапе анализа также в ограниченной постановке. Под эллипсисом понимается сжатая форма высказывания, смысл которой определяется либо предыдущими высказываниями (текстовый эллипсис), либо ситуацией, имеющей место в проблемной области (ситуативный эллипсис). Высказывания, содержащие эллипсис выглядят как неполные (содержащие пропуски слов) предложения. На этапе анализа может быть обработан (т.е. восстановлен) только текстовый эллипсис. Сущность методов восстановления текстового эллипсиса состоит в подстановке фрагментов предыдущих высказываний в текущее высказывание, содержащее эллипсис. Восстановление ситуационного эллипсиса осуществляется на этапе интерпретации.
На этапе интерпретации решаются две основные задачи: буквальная интерпретация высказывания в контексте диалога и интерпретация на цели участников общения. Методов решения этих проблем в общей постановке не существует, однако применительно к простым предметным областям их решение существенно упрощается. К простым относятся задачи информационного обслуживания (погода, товары, литература и т.д.) и задачи резервирования (мест, билетов, товаров). Эти задачи оперируют ограниченным количеством сущностей, которые являются параметрами предлагаемого вида обслуживания.
В общем случае, процесс идентификации сущности может иметь три исхода: однозначный, многозначный и неудовлетворительный. Последние два исхода рассматриваются как неудачи буквальной интерпретации и служат сигналами о необходимости установления подцелей более глубокого уровня, предусматривающих устранение неудачи. При этом в диалоговый компонент кроме сообщения о неудаче и типе неудачи передаются исходные данные, позволяющие сформировать (с помощью компонента генерации высказывания) действие системы по перехвату инициативы и открытия уточняющего поддиалога, преследующего новую подцель.
При решении задач интерпретации важную роль играет имеющееся в системе представление общей точки зрения на то, о чем идет речь в текущий момент. Эту точку зрения часто называют фокусом. Разделяемый участниками фокус позволяет им повысить компактность диалога за счет того, что сущности, находящиеся в фокусе, могут либо вообще не упоминаться в высказываниях (эллипсис), либо упоминаться в виде кратких описаний (ссылок).
Указанные методы базируются на фреймовых представлениях. Методы интерпретации, используемые в более сложных областях (например, понимание связных текстов, описывающих разворачивающиеся во времени события с большим числом участников), находятся в стадии становления и не поддаются обобщенному описанию, т.к. сильно зависят от условий задач и специфики применяемых средств представления знаний.
Вопросы и упражнения
1. По каким параметрам различают анализаторы, разрабатываемые для ЕЯ-систем?
2. Какие методы существуют для анализа слов? предложений? текстов?