2015-04-01
2015-04-01 1509
1509Данный алгоритм выполняется в два этапа.
На первом этапе CHAMELEON использует алгоритм разделения графа для получения набора относительно малых кластеров. На втором этапе, для объединения кластеров, полученных на первом этапе, в настоящие кластеры, используется иерархическая агломеративная кластеризация. Таким образом, алгоритм, фактически, является гибридным, построенным комбинацией графо-ориентированных и классических иерархических методов. Рассмотрим эти этапы подробнее.
На первом этапе, согласно графо-ориентированному подходу, происходит построение графа на матрице сходства объектов по принципу k ближайших соседей. Две вершины такого графа соединяет ребро, если объект, соответствующий любой из этих вершин попадает в число k наиболее близких объектов для объекта, соответствующего другой вершине из данной пары. На Рисунке 6 изображены: объекты в пространстве – слева, граф по принципу 1-го ближайшего соседа – в середине, граф по принципу 3-х ближайших соседей – справа.
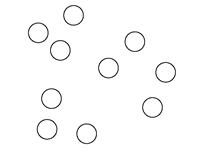
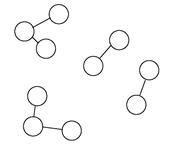
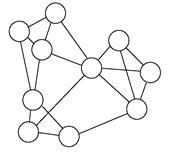
Рисунок 6 – Графы k ближайших соседей
Такое представление имеет целый ряд преимуществ.
Во-первых, можно сразу убрать ребра в графе с достаточно малым весом (значением сходства).
Во-вторых, возможно динамически определить для различных участков графа количество k ближайших соседей для вершин, на основе плотности данных отдельно взятого участка, которую, в свою очередь, можно определить на основе весов ребер.
В-третьих, операции на графах (например, разделение графа), имеющих такое представление, выполняются гораздо быстрее, чем на полных графах.
Обычно, k берется в пределах от 5 до 20 в зависимости от количества анализируемых объектов, и, как свидетельствуют авторы, выбор k почти не оказывает влияния на результаты кластеризации.
Далее, алгоритм разделяет полученный граф на множество сравнительно малых подграфов. Разделение происходит последовательно. На каждом шаге выбирается под-граф, содержащий наибольшее число вершин. Этот граф разделяется на два подграфа, так, что разделитель ребер графа минимален и каждый из получаемых подграфов содержит не менее 25 % вершин исходного графа. Процесс разделения останавливается, когда наибольший под-граф содержит меньше некоторого заданного числа вершин. Обычно величина этого параметра задается равной значению от 1 до 5 % от числа объектов. Полученное множество связных графов считается множеством начальных кластеров, на котором требуется провести последовательное иерархическое объединение.
На втором этапе, алгоритм последовательно объединяет кластеры, используя значение их относительной взаимной связности и относительного взаимного сходства. Только если оба эти значения достаточно высоки у двух кластеров, они объединяются.
Относительная взаимная связность пары кластеров определяется абсолютной взаимной связностью кластеров, нормализованной с учетом внутренней связности (п. 0) каждого кластера (подграфа). Нормализация используется для того, чтобы исключить тенденцию к преимущественному объединению крупных кластеров, у которых, определенно, значение взаимной связности будет больше, вследствие их размера.
Абсолютная взаимная связность между парой кластеров Ci и Сj определяется как сумма весов ребер, соединяющих вершины, принадлежащие Ci с вершинами из Сj. Эти ребра, фактически, входят в разделитель ребер графа, состоящего из кластеров Ci и Сj, и разбивающим его на подграфы Ci и Сj. Обозначается эта величина как 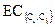 . Внутреннюю связность
. Внутреннюю связность 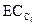 кластера Ci можно вычислить как сумму ребер, входящих в разделитель ребер, разбивающий Ci на два совершенно равных подграфа.
кластера Ci можно вычислить как сумму ребер, входящих в разделитель ребер, разбивающий Ci на два совершенно равных подграфа.
Относительная взаимная связность 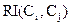 пары кластеров Ci и Сj определяется формулой:
пары кластеров Ci и Сj определяется формулой:
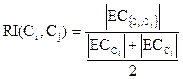 . (45)
. (45)
Учитывая значения относительной взаимной связности, можно добиться получения кластеров разного размера, формы и плотности, то есть общего внутреннего сходства.
Относительное взаимное сходство пары кластеров определяется как абсолютное сходство между этой парой кластеров, нормализованное с учетом их внутреннего сходства.
Абсолютное взаимное сходство между парой кластеров Ci и Сj подсчитывается как среднее сходство между соединенными вершинами, принадлежащими Ci и Сj соответственно. Эти соединения обусловлены предыдущим (на первом этапе) разбиением общего графа, полученного на матрице сходства.
Итак, относительное взаимное сходство 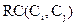 между парой кластеров Ci и Сj равно:
между парой кластеров Ci и Сj равно:
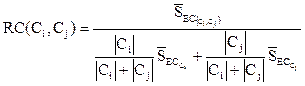 . (46)
. (46)
где 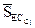 и
и 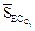 – средние веса ребер (значения сходства), принадлежащих разделителю ребер кластеров Ci и Сj соответственно, и
– средние веса ребер (значения сходства), принадлежащих разделителю ребер кластеров Ci и Сj соответственно, и 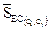 – средний вес ребер, соединяющих вершины Ci с вершинами Сj, причем ребра принадлежат разделителю ребер , определенному ранее. Можно также подсчитать внутреннее сходство как среднее значение весов всех связей в кластере, однако использования разделителя ребер по мнению авторов метода предпочтительнее. Этот факт они связывают с тем, что связи между объектами, помещенными в один кластер на ранних этапах объединения, сильнее, чем на поздних.
– средний вес ребер, соединяющих вершины Ci с вершинами Сj, причем ребра принадлежат разделителю ребер , определенному ранее. Можно также подсчитать внутреннее сходство как среднее значение весов всех связей в кластере, однако использования разделителя ребер по мнению авторов метода предпочтительнее. Этот факт они связывают с тем, что связи между объектами, помещенными в один кластер на ранних этапах объединения, сильнее, чем на поздних.
Далее, алгоритм применяет агломеративную иерархическую кластеризацию с использованием вышеозначенных показателей. Причем существует две стратегии их учета. Первая подразумевает наличие некоторых пороговых значений. TRI и TRC. В соответствии с этой стратегией, алгоритм для каждого кластера Ci проверяет, отвечают ли смежные (наиболее близкие) ему кластеры условиям:
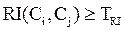 , (47)
, (47)
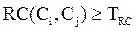 . (48)
. (48)
Если более одного смежного кластера отвечает этим условиям, то алгоритм выбирает для объединения наиболее связный кластер (граф), то есть такой кластер Сj, с которым у кластера Ci получается наибольшая абсолютная взаимная связность. По завершению прохода по всем кластерам, созданные таким образом пары объединяются. Параметры TRI и TRC могут использоваться для изменения характеристик получаемых кластеров.
Таким образом, основное отличие данного подхода от классических агломеративных иерархических методов в том, что, во-первых, на каждом шаге могут быть объединены несколько кластеров, а, во-вторых, на каком-то этапе ни одна пара кластеров не будет удовлетворять вышеуказанным условиям и такое разбиение будет считаться оптимальным, то есть в конце может не получиться один всеохватывающий кластер. Если данное разбиение не удовлетворяет выбранным критериям, то пороговые значения можно уменьшить.
Вторая стратегия заключается в использовании специальной функции, объединяющей понятия относительной взаимной связности и относительного взаимного сходства. На каждом шаге выбираются те кластеры для объединения, которые максимизируют эту функцию:
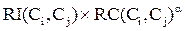 , (49)
, (49)
где a выбирается пользователем. Если a > 1, то алгоритм придает большее значение относительному взаимному сходству, а если a < 1, то большее значение имеет относительная взаимная связность. Разумеется, данный подход позволяет получить полную дендрограмму кластерного анализа.
Общая временная сложность этого алгоритма выражается как 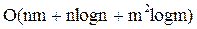 , где n – количество анализируемых документов, m – количество получившихся после первого этапа малых кластеров.
, где n – количество анализируемых документов, m – количество получившихся после первого этапа малых кластеров.