2015-04-08
2015-04-08 2309
2309Выбор в меню команды Analyze (Анализ) Descriptive statistics (Описательная статистика) Frequency... (Частоты...) приводит к раскрытию соответствующего диалогового окна Frequency (см. Рис. 16-17).
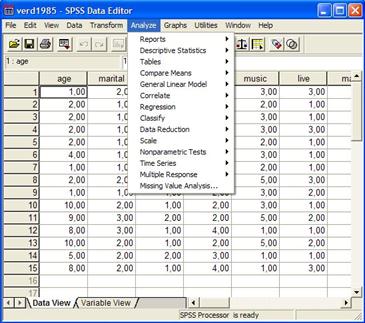
Рис. 16. Меню статистики
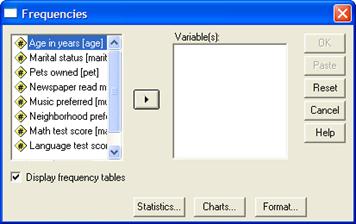
Рис. 17. Диалоговое окно Frequency
Диалоговые окна статистических процедур содержат следующие компоненты:
- список исходных переменных – список всех переменных в файле данных. Перед именем каждой переменной стоит значок; по которому можно определить, является ли эта переменная численной или строковой;
- список выбранных переменных – список, содержащий переменные файла данных, которые были выбраны для анализа. Список выбранных переменных также называют целевым списком или списком тестируемых переменных. Этот список имеет заголовок Variable(s) (Переменная(ые));
- командные кнопки — кнопки, при щелчке на которые выполняются определенные действия: OK, Paste (Вставить), Reset (Сброс или Отклонить), Cancel (Отмена) и Help (Справка), а также кнопки, открывающие вспомогательные диалоговые окна: Statistics... (Статистика), Charts... (Диаграммы или Графики) и Format... (Формат). Кнопки вспомогательных диалоговых окон отличаются троеточием (...) после названия.
Построить частотное распределение для переменной позволяет последовательное выполнение ряда процедур:
- выделение переменной;
- щелчок на кнопке, которая находится рядом со списком выбранных переменных, либо двойной щелчок на необходимой переменной, что повлечет за собой перенос переменной из списка исходных переменных в список выбранных переменных;
- Подтверждение операции щелчком на кнопке ОК. Результаты будут отображены в окне просмотра (Viewer) (см. Рис. 18).
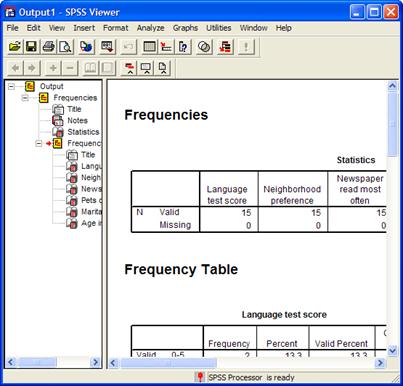
Рис. 18. Окно просмотра
Окно просмотра разделено на две части. В левой отображается структура вывода, а в правой – собственно выводимые данные. В разделе вывода отображаются как таблицы, так и графики. Ширину этих частей окна можно изменять перетаскиванием разделительной границы при помощи мыши. Результаты каждой выполненной статистической процедуры, а также графический вывод, отображаются в окне просмотра в виде блока, причём каждый блок является отдельным объектом. В иерархии каждый блок озаглавливается соответствующим именем процедуры, перед которым устанавливается значок блока. Этому значку предшествует небольшой четырёхугольник, в котором сначала указывается знак минус. Внутри каждого блока сначала идет заголовок и примечания. Далее идёт перечисление элементов блока, которым также предшествуют соответствующие символы. Такая конструкция иерархии объектов позволяет производить поиск необходимых элементов, переставлять их местами, копировать, удалять и т.д.
Поиск в окне просмотра. Увидеть в области вывода необходимый объект или элемент позволяет щелчок на соответствующем символе в иерархии.
Удаление в окне просмотра. Удалить некоторые элементы результатов расчётов позволяет щелчок на соответствующем символе и выбор в меню Edit (Правка) Delete (Удалить) / нажатие на клавиатуре клавиши <Del>.
Скрытый режим. Скрытые части блока становятся невидимыми на экране и при печати. Скрыть части результатов возможно, щёлкнув дважды на соответствующем символе в иерархии или выделив нужный элемент одним щелчком с последующим выбором меню View (Вид) Hide (Скрыть). Вновь сделать элемент видимым позволит повторный двойной щелчок на значке или выделение его одним щелчком с последующим выбором меню View (Вид) Show (Показать). Скрыть целый блок, содержащий весь вывод отдельной процедуры позволяет щелчок на маленьком квадратике слева от значка блока / выделение значка блока и выбор меню View (Вид) Collapse (Свернуть). При этом знак минус в квадратике превратится в знак плюс и данная процедура вместе со всем её содержимым исчезнет. Блок можно сделать видимым при помощи повторного щелчка на квадратике; при этом знак плюс опять будет заменён знаком минус. Можно также щелчком выделить значок блока и выбрать в меню View (Вид) Expand (Развернуть).
Перестановка в окне просмотра. Переместить некоторую часть результатов на другое место возможно, выделив соответствующий значок (если необходимо, то значок блока) и удерживая нажатой левую кнопку мыши, переместить его к тому элементу, после которого необходимо расположить данные результаты или блок. Альтернативная возможность перемещения элементов заключается в выделении значка, соответствующего необходимой части информации с последующим выбором меню Edit (Правка) Cut (Вырезать); выделение значка, позади которого необходимо вставить вырезанный элемент, и выбор в меню Edit (Правка) Paste After (Вставить после).
Копирование в окне просмотра. Скопировать какую-либо часть информации в другое место (при этом сохранив её на прежнем месте) позволяет:
- щелчок на значке, соответствующем нужному элементу или блоку, не отпуская кнопку мыши, нажатие на клавиатуре клавиши <Ctrl> и перетаскивание значка к тому элементу, после которого должен быть вставлен копируемый элемент;
- щелчок на значке копируемого элемента и выбор в меню опции Edit (Правка) Сору (Копировать); щелчок на значке элемента, после которого должен быть вставлен копируемый элемент и выбор в меню Edit (Правка) Paste After (Вставить после).
Изменение размера и типа шрифта иерархического списка. Изменить размер знаков и тип шрифта в иерархическом списке позволяет выбор в меню View (Вид) Outline Size (Размер знаков) и соответственно View (Вид) Outline Font (Шрифт знаков), что предоставляет возможность выбора среди трёх размеров (Small (Мелкий), Medium (Средний), Large (Крупный)) и большого количества шрифтов.
Вернуться в редактор данных позволяет выбор в меню команды Window (Окно) 1 название файла.sav — SPSS Data Editor или щелчок на панели инструментов на символе редактора данных  .
.
Для построения частотного распределения всех переменных, содержащихся в файле данных, необходимо:
- щелкнуть на имени первой переменной, задержав нажатой левую кнопку мыши, перетащить мышь до выделения всех переменных / щелкнуть на первой переменной, нажав клавишу <Shift> – на последней переменной (метод «Shift-клик»);
- перенести переменные в список выбранных переменных, щелкнув на кнопке с треугольником.
Чтобы выделить несколько переменных, которые находятся в разных местах списка, следует щелкнуть на первой переменной, при нажатой клавише <Ctrl> – на следующей и т.д. (метод «Ctrl-клик»).
Результаты появятся в окне просмотра результатов. Перед самой частотной таблицей выводится небольшая таблица с обзором допустимых и отсутствующих значений.

Каково Ваше отношение к политической оппозиции в современной России?
| Frequency (частота) | Percent (проценты) | Valid Percent (допустимые проценты) | Cumulative Percent (накопленные проценты) | ||
| Valid | положительное | 261 | 74,6 | 74,6 | 74,6 |
| нейтральное | 85 | 24,3 | 24,3 | 98,9 | |
| отрицательное | 4 | 1,1 | 1,1 | 100,0 | |
| Total | 350 | 100,0 | 100,0 |
Каждая строка частотной таблицы описывает одно возможное значение.
Строка с пометкой «нет данных» представляет наблюдения, в которых не было дано никакого ответа.
Первый столбец содержит метки отдельных значений.
Во втором столбце под заголовком «Частота» приведена частота каждого из вариантов ответа на вопрос.
В третьем столбце показана процентная частота каждого ответа. Процентная частота соответствует отношению каждого из вариантов ответа к общему количеству опрашиваемых, включая утерянные значения.
В четвертом столбце дано допустимое процентное значение. При определении этого значения утерянные данные исключаются.
Последний столбец содержит накопленные процентные значения. Накопленные проценты — это сумма процентных частот допустимых ответов. В последней строке содержится сумма всех столбцов (Всего).
Форматы частотных таблиц
Щелчок на кнопке Format... позволяет открыть диалоговое окно Frequencies: Format (Частоты: Формат) (см. Рис. 19).
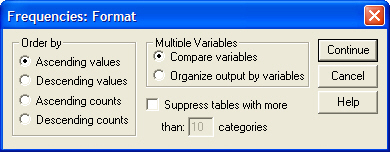
Рис. 19. Диалоговое окно Frequencies: Format
В группе Order by (Сортировать по) можно выбрать порядок, в котором будут отображены значения в частотной таблице. Возможны следующие варианты:
- Ascending values (По возрастанию значений): данные сортируются по возрастанию значений. Это настройка по умолчанию.
- Descending values (По убыванию значений): данные сортируются по убыванию значений.
- Ascending counts (По возрастанию частот): данные сортируются по возрастанию частот.
- Descending counts (По убыванию частот): категории сортируются по убыванию частот.
Кроме того, флажок Suppress tables -with more than... categories (He выводить таблицы с более чем... категориями) позволяет избежать вывода длинных частотных таблиц.
Вспомогательные диалоговые окна
Определить наименьшее, наибольшее и среднее значения переменной возможно следующим образом:
- выбрать в меню команды Analyze (Анализ) Descriptive statistics (Дескриптивные статистики) Frequency... (частота распределения);
- перенести переменную в конечный список переменных;
- открыть диалоговое окно Frequency: Statistics (Частотное распределение: Статистика) (см. Рис. 20), щелкнув на кнопке Statistics...;
- установить флажки Minimum (Наименьшее значение), Maximum (Наибольшее значение) и Average (Среднее значение);
- щелкнуть на кнопке Next (Далее), сохранив тем самым настройки, вернувшись в главное диалоговое окно;
- снять флажок Display frequency tables (Показывать частотные таблицы);
- запустить вычисление, щелкнув на кнопке ОК. Результаты будут показаны в окне просмотра.
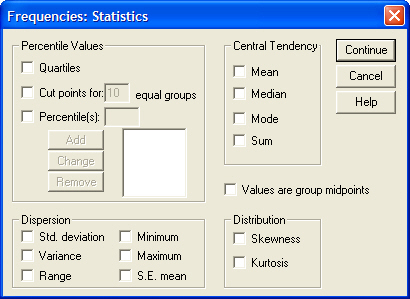
Рис.20. Диалоговое окно Frequency: Statistics
Частотные таблицы для наборов множественных ответов
- Выбрать команды меню Analyze (Анализ) Multiple Response (Множественные ответы) Frequencies... (Частоты), что откроет диалоговое окно Multiple Response Frequencies (Частоты множественных ответов) (см. Рис. 21). В списке Mult Response Sets этого диалога отображаются уже определенные наборы переменных.
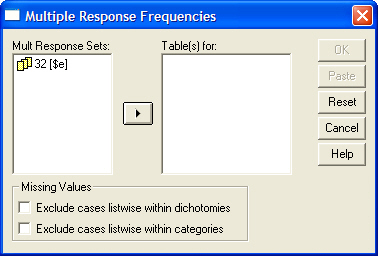
Рис. 21. Диалоговое окно Multiple Response Frequencies
- Перенести набор в список Table(s) for (Таблицы для).
- Щелкнуть на кнопке ОК.
В окне просмотра появятся результаты.
В столбце "Dichotomy label" (Метка дихотомии) приводятся метки переменных, принадлежащих к набору. В таблице отобразится количество пропущенных и допустимых наблюдений. Отсутствующим наблюдением считается, если ни одна из переменных набора не имеет учитываемого значения (в данном примере значения «1»).
Если в диалоговом окне Multiple Response Frequencies установить флажок Exclude cases listwise with dichotomies (Для дихотомических переменных исключать наблюдения по списку), к пропущенным будут причисляться и те наблюдения, в которых хотя бы одна переменная набора имеет отсутствующее значение — в данном примере не закодирована ни единицей, ни нулем. Это вариант представления может быть полезен, если данный ответ в анкете не определен однозначно.
Для наблюдаемых частот выводятся два разных процентных значения. При определении первого из них наблюдаемая частота отнесена к общему числу ответов "да", а при определении второго — к общему числу допустимых наблюдений.