2015-04-20
2015-04-20 1127
1127Мы не собираемся утверждать, что структурное программирование сверху-вниз исчерпывается тем, что было сказано в предыдущем разделе, Оно включает достаточно много других аспектов, один из которых можно выразить лозунгом «Упрощай структуры управления».
Другие аспекты — это требование соответствующей документации, наглядной записи программных операторов с использованием отступов в начале строк, разбиения программы на обозримые части.
Рекомендуется, например, составлять программные модули так, чтобы их распечатка не превышала одной-двух страниц. Страница -это смысловая единица, которую можно представить себе в любой момент как единое целое и которая сводит к минимуму необходимость переворачивать страницы при прослеживании передач управления в программе.
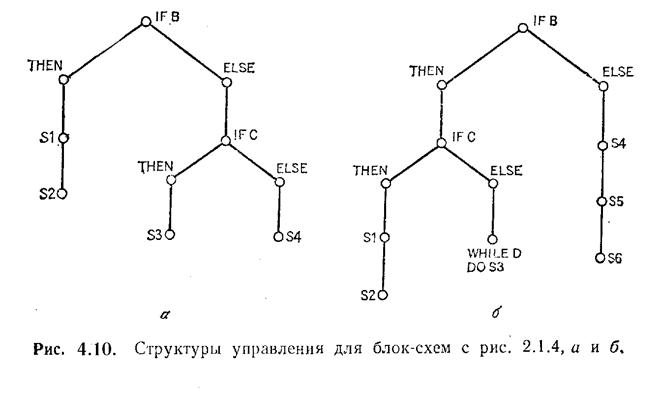
Конечно, для разработки структурированной сверху-вниз программы потребуется затратить больше усилий, чем для получения неструктурированной программы. Впрочем, опыт показывает, что дополнительные затраты с лихвой вознаграждаются. Структурированные программы, как правило, легче читать, и в них легче разбираться, так как их можно читать сверху-вниз, не прыгая по тексту из конца в начало. Главным образом это достигается благодаря тому, что общая структура управления в структурированной программе является деревом, а не сетью со многими циклами. (На рис. 4.10, например, мы приводим деревья, описывающие структуры управления блок-схем с рис. 4.4 а и 4.4 б).
По этой причине такие программы иногда называют программами со структурой дерева.
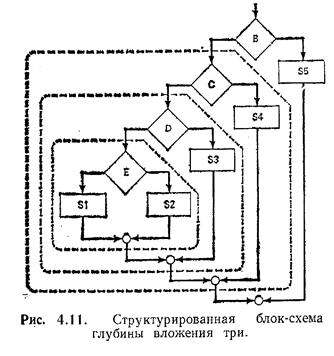
Прежде чем окончить наше обсуждение структурного программирования сверху-вниз, хотелось бы сделать несколько предостережений. Во-первых, этот метод разработки алгоритмов не гарантирует отсутствие ошибок в программе. Опыт показывает, например, что, когда глубина вложения структур управления равна трем или более трех, вероятность совершения ошибки возрастает очень сильно. На рис. 4.11 приведен пример структурированной блок-схемы с глубиной вложения три. Аналогичная ситуация возникает и в случае, когда модули становятся очень длинными.
 |
Второе предостережение связано с термином «программирование без goto», которое иногда используется как характеристика структурного программирования. Чем бы ни было структурное программирование, это не метод программирования, запрещающий использование операторов goto, ни процесс преобразования неструктурированной программы в программу без операторов goto. Помимо того, что само по себе это не приводит к структурированной программе, текст программы становится менее понятным.
4.4.Практические советы при использовании метода структурного программирования
Итак, когда мы рассмотрели такое понятие, как структурное программирование, сформулируем основные практические принципы написания программ этим методом.
В рассмотрении этих принципов мы остановимся на семи, хотя это не означает, что мы не можем добавить к рассмотренным нашим принципам еще дополнительные
1. Никаких трюков и заумного программирования.
Это означает что нельзя использовать сложные методы там, где можно использовать более простые.
2. Как можно меньше переходов.
Необходимо создавать программы, где будет как можно меньше простых переходов, так как лишние переходы только усложняют понимание программы. В тоже время программирование без операторов goto - это еще не структурное программирование. В некоторых случаях их применение считается более целесообразным.
3. Выбор с использованием if -then-else.
Целью здесь является обеспечение простоты выполнения без каких бы то ни было переходов извне внутрь рассмотренной структуры.
4. Простота циклов.
Переходы по программе назад почти всегда можно представить как некоторую форму цикла. И ход выполнения может стать более ясным, если задать цикл в явном виде.
5. Сегментация.
Громоздкие программы состоящие, как правило, из основной невозможно читать. В отсутствие конструкции if-then-else она будет перегружена метками и переходами и структура ее будет не ясна. Если имеется возможность использования if-then-else, то глубина вложенности циклов, скорее всего, станет так велика, что отыскание для каждого if-then соответствующего else будет затруднено.
Чтобы обойти указанные трудности, каждую большую программу можно разбить на множество модулей или процедур (подпрограмм или функций), спроектированных так, что цель для каждой из них определена (логическая часть исходной задачи) и в каждой по возможности используются собственные локальные переменные. Не старайтесь разделить программу на равные куски («куски» в этом случае - самое подходящее слово для того, что Вы получите), а выделяйте логические фрагменты. Некотрые из них окажутся достаточно малыми для того, чтобы их можно было в таком виде и оставить. Другие же, в свою очередь, потребуют разбиения на процедуры следующего уровня и т.д.
В любом случае целью является обеспечение достаточной простоты как каждого модуля самого по себе, так и его связей с другими модулями, чтобы их можно было тестировать независимо. В полной мере добиться этого не просто, но постоянное стремление к цели при определенных обстоятельствах может обеспечить высокое качество конечного продукта.
6. Рекурсия.
Следует, как уже указывалось в предыдущей главе, очень осторожно подходить к определению случаев, когда нужно использовать рекурсию. Все, что можно легко запрограммировать при помощи простого цикла, как правило, так и следует программировать.
7. Содержательные обозначения
Необходимо пояснить переменные и действия ЭВМ комментариями и соответствующими обозначениями.
Целесообразно и переменные обозначать такими буквами, которые несут некоторую информацию.
1.4. Общая организация программы и ее запись
Итак, мы рассмотрели сущность структурного программирования, теперь рассмотрим как лучше записать программу, составленную с помощью структурного программирования. Прежде всего отметим, что для ЭВМ форма записи программы безразлична, поэтому можно применить любую форму записи. Следовательно, можно составить программу так, чтобы она была воспринята человеком с наибольшим пониманием. Или другими словами как записать программу так, чтоб облегчить понимание структуры программ.
Основными разновидностями форм записи являются отступы, и изменения числа строк (т.е. применения метода когда несколько операторов записаны в одной строке, или разных строках). В настоящее время уже сложились определенные правила по которым записываются программы. Эти правила получили название так называемого «малого программистского стандарта». Рассмотрим их.
1. Цикл.
Короткие циклы, которые помещаются в одну строку, лучше так в одной строке и записывать: '-
FOR I.....:.........: NEXT I;
Длинные циклы записываются со смещением тела цикла:
FOR I.....:
Оператор
Оператор
NEXT I
Если у кратных циклов общее начало и/или конец, то их можно записать так:
FOR I.....: FOR J
Оператор
Оператор
NEXT J: NEXT I
Если цикл организован операторами, моделирующими условие «пока», или с помощью операторов IF, то целесообразно его также записывать со смещением вправо тела цикла, аналогично записи оператора FOR
2. Ветвление
Короткие операторы IF записываются в одну строку:
IF... THEN... ELSE...
Более длинные ветвления следует записывать так:
IF... THEN.... _
ELSE....
где подчеркивание знак продолжающейся строки.
Длинные операторы IF записываются в операторной форме:
IF... THEN
Оператор
Оператор
.....
Оператор
ELSE
Оператор
Оператор
.....
Оператор
END IF
3. Обход. Это частный случай ветвления и записывается так же, только без ELSE (или соответствующих ELSE) операторов.
4. Длинные операторы.
Если оператор не помещается в строку, то его продолжение следует записывать со смещением, причем не безразлично, в каком месте сделан перенос. Например:
INPUT А (1), N (1), SKIP, F (8,3),F (3), N_
(2,3),FF
читается хуже, чем
INPUT А (1), N (1), SKIP, F (8,3),F (3), _
N(2,3),FF
5. Объединение в строку.
Если язык позволяет размещать несколько операторов в одной строке, то в строку следует группировать логически связанные операторы, выполняющие законченные действия или родственные функционально.
Очевидно, что запись
I=1
X=RO*COS(FI);
Y = RO * SIN (Fl);
читается хуже, чем
I=1
X=RO*COS(FI): Y = RO * SIN (Fl);
так как объединение последних двух операторов в строку подчеркивает их функциональное единство (перевод из полярных координат в обычные) и выделяет первый оператор (установка начального значения какого-то индекса или счетчика). В строку должны быть сгруппированы операторы так, чтобы каждую строку можно было кратко откомментировать.
Например:
DISKR=SQRT(B**2-4*A*C): А2=2*А ‘ВСПОМОГ. ДЕЙСТВИЯ
XI=(-B+DISKR)/A2: X2=(-B-DISKR)/A2 ‘КОРНИ
6. Группировка внутри строки. Увеличив интервалы между некоторыми операторами, можно дополнительно улучшить восприятие программы. Например, если строку начальных значений программы записать
МАХТ=С: MINT=D: IMAXT=0: IMINT=0
или
МАХТ=С: IМАХТ=0: MINT=D: IMINT=0
сгруппировав отдельно сведения о максимуме и сведения о минимуме или же разделив значения и индексы, то это читается легче, чем сплошной текст:
МАХТ=С: IMAXT=0: MINT=D: IMINT=0
По тому же принципу следует группировать операторы и на схемах: в один линейный блок объединяются функционально родственные вычисления, тогда при программировании переход к новому блоку схемы сопровождается переходом к новой строке программы.
Некоторые авторы (например, [14]) рекомендуют записывать в каждой строке только один оператор. Эта рекомендация безусловно неправильна: историческое развитие языков щло от Фортрана, где допускается только один оператор в строке, к Алголу-60, ПЛ/1 и т.д., где допускается несколько операторов в строке, — непонятно, почему этой возможностью не следует пользоваться.
Смещение на каждом шаге лесенки не должно быть большим, обычно оно на уровне следующего лексического слова: четырех — шести позиций вполне достаточно. Такая лесенка хорошо смотрится и на листинге, и на экране дисплея.
Желательно писать программы без меток, но если они встречаются в программе, то должны быть вынесены в начало строки и должны выступать из общего текста программы влево, чтобы их было легко найти. К началу строк выносятся заголовки блоков, начала крупных циклов и крупных составных операторов. Операторы NEXT, END должны размещаться либо в той же строке, что и соответствующий им оператор, например FOR, IF или BEGIN, либо под парным ему FOR, IF или BEGIN.
Для удобства чтения программа должна быть хорошо откомментирована. Можно предложить следующие правила комментирования.
1. Каждая программа или подпрограмма должна начинаться с комментария, в котором на русском языке записано, что делает эта программа.
2. Идентификаторы должны быть мнемоничны (хорошая мнемоника очень существенно дополняет комментарии). За заголовком программы или подпрограммы должны быть откомментированы все основные идентификаторы и расшифрована их мнемоника. Например: NSTR — номер обрабатываемой строки.
3. В тексте программы должны размещаться комментарии, представляющие собой краткий заголовок, характеризующий действия, выполняемые до следующего комментария. Комментирование каждого оператора бессмысленно, так как оно может только повторить то, что делает этот оператор и что можно понять, прочтя оператор. Если операторы позволяют понять, как работает программа, то комментарий должен пояснить, что и зачем делают эти операторы. Например, для программы решения системы линейных уравнений методом Гаусса примерно на 60 операторов текста достаточно четырех комментариев: "Цикл по шагам", "Пересчет строки", "Перестановка строк", "Обратный ход: вычисление Х (1)", связывающих фрагменты текста программы с основными этапами алгоритма.
4. Все выдаваемые программой печати должны быть с поясняющими словами: вместе с содержимым переменных должны печататься либо их идентификаторы, либо поясняющий текст на русском языке — такой текст служит хорошим комментарием как к результатам работы программы, так и к тексту операторов вывода.
Для удобства пользования программой следует хорошо продумывать ввод-вывод. Помимо поясняющих слов на выводе следует обеспечить естественность форматов:
матрица должна печататься по строкам в виде матрицы (а не в одну строку),
на одном файле должно помещаться целое число строк многомерного массива (например, матрицу размером 5Х5 не следует вводить по 7 чисел со строки) и т.д.
Программа может быть оформлена как единая головная программа или же из нее могут быть выделены подпрограммы, наконец, вся программа может быть оформлена как процедура. Такое оформление алгоритма или его части в виде процедуры обычно преследует одну из следующих целей:
а) придание алгоритму общности,
б) сокращение общего объема программы за счет возможности одной процедурой обрабатывать различные переменные, массивы и т. д„
в) сокращение времени разработки и отладки программы за счет параллельного программирования и отладки процедур,
г) сокращение времени трансляции: отлаженная процедура записывается в библиотеку или выдается файлом в транслированном виде и более не транслируется.
Для получения достаточно универсальных и удобных в использовании процедур необходимо оформлять их с учетом некоторых правил.
1. Обмен данными с процедурами. Для получения процедурой данных из другой программной единицы и для выдачи в другую программную единицу полученных результатов служат параметры (к которым мы отнесем также глобальные переменные и общие области). Прочие работающие в процедуре идентификаторы никакого отношения к совпадающим по названию идентификаторам других программных единиц не имеют. Параметры - это "окна во внешний мир", через которые процедура получает исходные данные и отдает свои результаты.
Параметры можно разделить на две группы: а) входные, через которые процедура получает исходные данные; б) выходные, через которые она отдает результаты своей работы.
Некоторые параметры могут относиться одновременно к обеим группам. Таким образом, в параметры следует включать только те переменные, через которые идет обмен информацией с другими программными единицами. Все прочие переменные, которые используются в процедуре, в параметры включать не следует, так как использование этих переменных — это внутреннее дело процедуры и больше эти переменные никого не интересуют.
2. Процедуры-функции. Процедуры, которые выдают в качестве результата только одно значение (не массив), оформляются как функции. У функции на один формальный параметр меньше, так как в качестве выходного параметра используется идентификатор функции. Функция удобнее в использовании, так как ее результат можно непосредственно использовать в выражении без предварительного присваивания.
3. Ввод-вывод в процедурах. Процедуры содержат операторы ввода-вывода в редчайших случаях. Исключение составляют только процедуры, специально созданные для ввода-вывода, например, процедура печати графика на принтере своим единственным результатом имеет напечатанный график.
4. Проверка применимости алгоритма. Многие алгоритмы могут не давать результата в ряде случаев (например, система линейных уравнений не всегда имеет решение). Процедуры, реализующие такие алгоритмы, имеют свои особенности программирования. Общий принцип заключается в том, что при любых исходных данных процедура должна доработать до конца и выдать либо результат, либо сообщение о невозможности получить результат. Из этого вытекают два следствия.
Следствие 1. Там, где может случиться аварийная ситуация, должны быть предусмотрены соответствующие проверки и действия по устранению или обходу этой ситуации или же выдаче сообщения. Например, при решении системы линейных уравнений по компактной схеме Гаусса необходимо делить элементы строки на диагональный элемент. Если этот элемент близок к нулю, то возникнет аварийная ситуация (переполнение или деление на нуль), в результате которой программа будет снята с решения. Следовательно, перед делением надо проверить этот элемент на близость нулю и при необходимости выполнить перестановку строк, а если подходящей для перестановки строки нет, то выдать сообщение о неразрешимости системы.
Следствие 2. Процедура, реализующая алгоритм, который может не дать результата, должна иметь дополнительный (сигнальный) параметр, по которому определяют успешность работы процедуры. Этот выходной параметр обычно бывает целой или логической переменной или меткой. Целесообразно параметр объявлять логической переменной, если ошибка зависит от одного фактора. Если причин неразрешимости несколько и существенно то, по какой из них невозможно получить результат, то параметр лучше сделать целой переменной, принимающей значения: 0 — если решение получено, 1 — если система несовместна, 2 — если решений бесконечно много и т.п. (иногда можно помимо выдачи признака аварийной ситуации через параметр выполнить печать причины в самой процедуре, но возврат в обратившуюся программу и сигнальный параметр остаются обязательными). Наконец, параметр может быть меткой, по которой происходит выход при неразрешимости системы. Однако следует помнить, что вариант с меткой нарушает структурность обращающейся к процедуре программы.
Чтобы лучше понять, к чему приводит нарушение описанного принципа, представьте, что Вы попросили товарища узнать время отправления самолета, рейс оказался отложенным на неопределенное время и товарищ уехал домой, не сообщив Вам ничего: Вы же просили узнать время, а ему не удалось.
1.4. "Малый программистский стандарт"
Даже элементарную задачу по программированию можно решить настолько различными способами, что с первого взгляда трудно понять, что обе программы делают одно и то же. Рассмотрим еще один пример: из массива надо выбрать положительные числа и упаковать их в один массив, прижав их к началу массива, а отрицательные — во второй (нулевых нет). Решение может выглядеть так:
IP=1; IO=0
FOR I=1 TO N
IF A(l) > 0 THEN POL(IP) =A(I): IP=IP+1
ELSE IO = IO+1: OTR(IO) = A (I)
NEXT I
Хотя формально это решение правильно и ЭВМ сделает то, что надо, но недостатком является то, что сходная обработка массивов POL и OTR выполнена по-разному: IP указывает первый свободный элемент и изменяется после переписи, а IO указывает последний занятый элемент и изменяется до переписи элемента. Такой разнобой в реализации сходных конструкций в более сложных случаях может повлечь ошибки: где-нибудь программист забудет и сначала изменит индекс, а затем выполнит обработку элемента, в то время как нужно было сделать наоборот.
Каждый программист обычно имеет свои любимые приемы, и когда он им изменяет, то часто именно в этом месте делает ошибку. Поэтому каждому программисту можно порекомендовать выработать для себя некий "малый программистский стандарт" и не отклоняться от него без весьма веских оснований. Выдерживание стандарта в пределах одной программы обязательно, а при переходе от программы к программе — крайне желательно. Доведенное до автоматизма выполнение стандартных приемов убережет от ошибок и позволит сосредоточиться на нестандартной части работы, т. е. там, где действительно нужно творчество.
Желательно, чтобы все программисты, работающие над одной программой (над разными ее частями или модулями), пользовались одним и тем же стандартом. Еще лучше, если этот стандарт обязателен к применению в данной организации: это облегчает взаимопонимание программистов. Стандарт должен отражать следующие моменты.
1. Общая структура программы. Если в языке можно по-разному записать одну и ту же программу, то стандарт может требовать определенной формы записи. Например, даже если в каком-нибудь языке разрешается беспорядочно размещать описания среди прочих операторов (скажем ПЛ/1), стандарт может требовать:
а) все описания переменных собираются в начало и группируются по назначению: входные, выходные, рабочие;
б) далее идут описания внутренних процедур;
в) затем располагается тело программы.
Аналогично, во многих автокодах описание констант можно размещать как в начале, так и в конце модуля. Стандарт должен требовать какого-то определенного расположения описаний констант, хотя оба варианта равноправны.
2. Система идентификации. Мнемоника идентификаторов выбирается по некоторым правилам. Например, индексы, связанные с каким-то массивом, образуются из буквы "I" и нескольких букв идентификатора массива; все признаки, принимающие значение "истина—ложь", имеют идентификаторы, начинающиеся с буквы "P" (Признак), а все номера чего-либо — идентификаторы, начинающиеся буквой "N".
Если язык не допускает русских букв в идентификаторах, то надо также оговорить язык идентификаторов, например: все идентификаторы представляют собой транслитерацию (запись латинскими буквами) русских слов, возможно, сокращенных, т.е. для обозначения длины берется идентификатор DLINA или DL, а не LENGTH (англ.) или LONGUEUR (франц.).
3. Система значений. Если одна проверка устанавливает значение некоего признака "истина" при отсутствии ошибки, то другая проверка не должна устанавливать значение "истина" при наличии ошибки. Если под интервалом I по оси х понимается интервал(Xi, Xi+1), то под интервалом J по оси у должен пониматься интервал (Yj, Yj+1), а не (Xj, Xj-1).
4. Порядок работы. Сходная обработка должна выполняться одинаковым способом. Например, все указатели установлены на последний обработанный элемент и сдвигаются перед обработкой очередного элемента; все проверяющие нечто процедуры сами печатают обнаруженные ошибки, а в устанавливаемом признаке ошибки не указывают тип ошибки.
"Малый стандарт" очень помогает, когда надо вспомнить свою старую программу или разобраться в чужой программе, так как он очень быстро воспринимается читающим и помогает следить за мыслью автора.
5. Методы разработки алгоритма
Для разработки какой-либо программы прежде всего необходимо определить каким методом будет решаться поставленная задача. Для ответа на этот вопрос целесообразно — просмотреть свой запас общих алгоритмических методов для того, чтобы проверить, нельзя ли с помощью одного из них сформулировать решение новой задачи. Таких методов решения задач существует множество. В этой главе мы остановимся на основных из них:
- частных целей, подъема и отрабатывания назад - три самые общие метода решения задач;
- метод отхода и метод ветвей и границ - методы решения больших комбинаторных задач;
- рекурсия и итерация - инструменты, которые может в значительной степени упрощают логическую структуру многих алгоритмов;
- эвристика и имитация - два широко используемых «житейских» метода.
Эти методы необязательно действуют обособленно, как правило решение задачи основывается на нескольких методах, один из которых доминирует. Кроме того возникает ситуация когда один метод основывается на другом. Например, метод эвристики очень часто использует алгоритм решения задачи с помощью метода частных целей.
Цель этой главы — построить и пояснить вышеназванные фундаментальные методы разработки алгоритмов и решения задач. Для студентов изучающих данный курс необходимо прежде всего овладеть этими основными методами и понятиями.
5.1. Методы частных целей, подъема и отрабатывания назад
Как разработать хороший алгоритм? С чего начать? У всех нас есть печальный опыт, когда смотришь на задачу и не знаешь, что делать. Прежде чем самому предлагать свой алгоритм, необходимо подумать какой метод, из уже разработанных, подходит для решения поставленной задачи. В этом разделе кратко описаны три общих метода решения задач, полезных для разработки алгоритмов.
Для начала дадим определения каждому методу, а потом их поясним
Метод частных целей - когда решение первоначальной задачи разбивается из решения более простых задач.
Метод подъема - метод постепенного приближения к цели от начального предположения к такому, при котором дальнейшее приближение не возможно.
Метод отрабатывания назад - метод, использующий путь решения от результата к начальным условиям.
Теперь поясним эти методы более подробно.
Первый метод связан со сведением трудной задачи к последовательности более простых задач. Конечно, мы надеемся на то, что более простые задачи легче поддаются обработке, чем первоначальная задача, а также на то, что решение первоначальной задачи может быть получено из решений этих более простых задач. Такая процедура называется методом частных целей.
Этот метод выглядит очень разумно. Но, как и большинство общих методов решения задач или разработки алгоритмов, его не всегда легко перенести на конкретную задачу. Осмысленный выбор более простых задач — скорее дело искусства или интуиции, чем науки. Более того, не существует общего набора правил для определения класса задач, которые можно решить с помощью такого подхода. Размышление над любой конкретной задачей начинается с постановки вопросов. Частные цели могут быть установлены, когда мы получим ответы на следующие вопросы:
1. Можем ли мы разбить данную задачу на отдельные подзадачи?
2. Можем ли мы решить часть из этих подзадач?
Можно ли, игнорируя некоторые условия, решить оставшуюся часть задачи?
3. Можем ли мы решить задачу для частных случаев?
Можно ли разработать алгоритм, который дает решение, удовлетворяющее всем условиям задачи, но входные данные которого ограничены некоторым подмножеством всех входных данных?
4. Есть ли что-то, относящееся к задаче, что мы не достаточно хорошо поняли? Если попытаться глубже вникнуть в некоторые особенности задачи, сможем ли мы что-то узнать, что поможет нам подойти к решению?
5. Встречались ли мы с похожей задачей, решение которой известно. Можно ли видоизменить ее решение для решения нашей задачи? Возможно ли, что эта задача эквивалентна известной нерешенной задаче?
Второй метод разработки алгоритмов известен как метод подъема. Алгоритм подъема начинается с принятия начального предположения или вычисления начального решения задачи. Затем начинается насколько возможно быстрое движение «вверх» от начального решения по направлению к лучшим решениям. Когда алгоритм достигает такую точку, из которой больше невозможно двигаться наверх, алгоритм останавливается. К сожалению, мы не можем всегда гарантировать, что окончательное решение, полученное с помощью алгоритма подъема, будет оптимальным. Этот «дефект» часто ограничивает применение метода подъема.
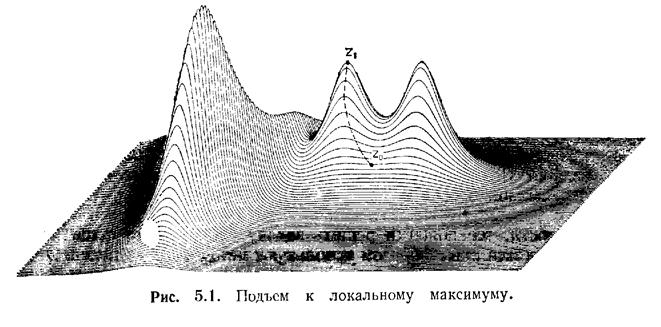
Название «подъем» отчасти происходит от алгоритмов нахождения максимумов функций нескольких переменных. Предположим, что f(x, у) — функция переменных х и у и задача состоит в нахождении максимального значения этой функции. Проиллюстрируем данную задачу рисунком 5.1. Функция не нем представлена поверхностью (имеющей холмы и впадины) над плоскостью х у. Алгоритм подъема может начать работу в любой точке Zî этой поверхности и проделать путь вверх к вершине в точке Z1. Это значение является «локальным» максимумом в отличие от «глобального» максимума, и метод подъема, как мы видим, не дает оптимальною решения. Т.е. мы нашли, максимальное значение функции - что требовалось в задаче, но это «локальный» максимум, а не «глобальный», т.е. не самое максимальное значение. Вообще методы подъема являются «грубыми». Они запоминают некоторую цель и стараются сделать все, что могут и где могут, чтобы подойти ближе к цели. Это делает их несколько недальновидными. Как показывает наш пример, алгоритмы подъема могут быть полезны, если нужно быстро получить приближенное решение.
Третий метод, рассматриваемый в этом разделе, известен как отрабатывания назад, т. е. начинаем с цели или решения и движемся обратно по направлению к начальной постановке задачи. Затем, если эти действия обратимы, движемся обратно от постановки задачи к решению. Многие из нас делали это, решая головоломки в развлекательных разделах воскресных газет.
Давайте постараемся применить все три метода этого раздела в довольно трудном примере.