 2015-04-20
2015-04-20 1451
14511. Рассчитываются ранги (порядковые номера)
значений фактора пропорциональности zi = xik.
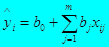 2. Рассчитывается уравнение
2. Рассчитывается уравнение
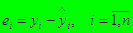 |
и вычисляются остатки.
3. Рассчитываются ранги остатков ei.
4. Рассчитывается коэффициент ранговой корреляции Спирмена
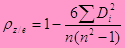 |
, Di – разность рангов z и e.
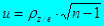 |
5. Рассчитывают статистику,
распределенную нормально N (0,1) при отсутствии
гетероскедастичности.
17. Выполнение предпосылки МНК о гомоскедостичности остатков. Тест Уайта.
Идея теста Уайта заключается в оценке функции (1) с помощью соответствующего уравнения регрессии для квадратов остатков:
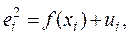
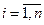 , где ui – случайный член. (2)
, где ui – случайный член. (2)
Гипотеза H0 об отсутствии гетероскедастичности (условие f = const) принимается в случае не значимости регрессии (2) в целом.
a) Итак, сначала к исходной модели применяется обычный МНК;
b) Находятся остатки ei, 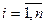 регрессии;
регрессии;
c) Осуществляется регрессия квадратов этих остатков ei на все регрессоры x вида (2);
d) Осуществляется регрессия квадратов этих остатков ei на квадраты регрессоров x 2;
e) Осуществляется регрессия квадратов этих остатков ei на попарные произведения регрессоров;
Для пунктов c) – e) считается F – статистика, если 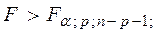 где p – количество регрессоров, то гипотеза H0 об отсутствии гетероскедастичности отклоняется.
где p – количество регрессоров, то гипотеза H0 об отсутствии гетероскедастичности отклоняется.
Заметим, что на практике применение теста Уайта с включением и не включением попарных произведений дают, как правило, один и тот же результат.
Привлекательной чертой теста является его универсальность. Однако, если гипотеза H0 об отсутствии гетероскедастичности отклоняется, этот тест не дает указания на функциональную форму гетероскедастичности.
18. Выполнение предпосылки МНК об отсутствии автокорреляции в остатках. Тест Дарбина-Уотсона.
Для проверки на автокорреляцию используется ряд критериев, из которых наиболее широкое применение получил критерий Дарбина-Уотсона:
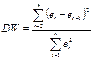
Критерий DW связан с выборочным коэффициентом корреляции между еt и еt-1, соотношением: DW≈2(1-r),
Если автокорреляция отсутствует, то DW ≈ 2, при наличии положительной автокорреляции DW<2, если автокорреляция отрицательна, DW>2. И поскольку коэффициент корреляции принимает значения -1 ≤ r ≤ 1, то 0≤ DW ≤ 4. Полученное для данной регрессии значение статистики сравнивается с верхней и нижней границами ее критического значения dL ≤ dкрит ≤dU. Границы dU и dL выбираются из таблиц по числу наблюдений n, числу регрессоров k и уровню значимости α. При этом возможны следующие случаи:
1. Наличие положительной автокорреляции: DW<dL.
2. Наличие отрицательной автокорреляции: DW >4-dL.
3. Автокорреляция отсутствует: dU ≤ DW≤ 4-dU.
4. Зоны неопределенности: dL<DW< dU или 4- dU <DW<4-dL.
Этот тест подробно исследован и реализован во всех статистических пакетах, STATGRAPHICS, STATISTICA и других.
| Значение статистики DW | Вывод |
| 4 – dl < DW < 4 | Гипотеза о независимости остатков отвергается, есть отрицательная корреляция |
| 4 – du < DW < 4 – dl | Неопределенность |
| 2 < DW < 4 – du | Принимается гипотеза о независимости остатков |
| du < DW < 2 | Принимается гипотеза о независимости остатков |
| dl < DW <du | Неопределенность |
| 0 < DW <dl | Гипотеза о независимости остатков отвергается, есть положительная корреляция |
19. Выполнение предпосылки МНК об отсутствии автокорреляции в остатках. Тест Броша-Годфри.
Тест основан на следующей идее: если имеется корреляция между соседними наблюдениями, то естественно ожидать, что в уравнении
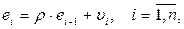 (*)
(*)
где ei – остатки регрессии, получаемые обычным МНК, коэффициент r окажется значимо отличающимся от нуля.
Практическое применение теста заключается в оценивании МНК регрессии (*), где временной ряд ei -1 представляет ряд ei со сдвигом по времени на единицу.
Преимущество теста Б-Г по сравнению с тестом Д-У заключается в том, что он проверяет с помощью статистического критерия, между тем как тест Д-У содержит зону неопределенности для значений d – статистики. Другим преимуществом теста является возможность обобщения: в число регрессоров могут быть включены не только остатки с лагом 1, но и с лагом 2, 3 и так далее, что позволяет выявить корреляцию не только между соседними, но и между более отдаленными наблюдениями.
20. Выполнение предпосылки МНК о нормальности остатков (любой критерий).
Обнаружение ге-тероскед-сти. Тест Голдфельда Квандта. Появление проблем гетеро-скед-сти можно предвидеть основываясь на знаниях характера данных. В этих случаях можно предпринимать действия на этапе спецификации модели регрессии. Это позволит уменьшить или устранить необходимость формальной проверки. В настоящее время используются следующие виды тестов гетероскед-сти, в которых делается предположение о наличие зависимости между дисперсией случайного члена и величиной объясняющей переменной:
1)Тест Голдфельда Квандта.
При проведении проверки по этому критерию предполагается, что дисперсия случайного члена пропорциональна значению X в этом наблюдении. Предполагается, что случай-ный член распределен нор-мально и не подвержен авто-корреляции. Все наблюдения в выборке упорядочиваются по величине X, после чего оцениваются отдельные регрессии для первых n со штрихом наблюдений и для последних n со штрихом наблюдений. Если предположение о наличие гетероскед-сти верна, то дисперсия в последних n наблюдениях будет больше, чем в первых n со штрихом наблюдениях. Суммы квадра-тов остатков обозначают для первых n со штрихом наблюдений обозначают RSS1, для последних n со штрихом наблюдений RSS2, затем определяют их отношения. Это отношение имеет F-распределения при заданных (n со штрихом-k-1)/(n со штрихом-k-1) степе-нях свободы. Если n=30, то n со штрихом= min11.
21. Устранение нарушений предпосылок МНК (наличие гетероскедостичности остатков).
С этой целью строиться график зависимости остатков ei от
теоретических значений результативного признака:
Если на графике получена горизонтальная полоса, то остатки ei
представляют собой случайные величины и МНК оправдан, теоретические значения
ух хорошо аппроксимируют фактические значения у.
Возможны следующие случаи: если ei зависит от у
x, то: 1.остатки ei не случайны.2. остатки e
i, не имеют постоянной дисперсии. 3. Остатки ei
носят систематический характер в данном случае отрицательные значения e
i, соответствуют низким значениям ух, а
положительные — высоким значениям. В этих случаях необходимо либо применять
другую функцию, либо вводить дополнительную информацию.
Как можно проверить наличие гомо- или гетероскедастичноси остатков?
Гомоскедастичность остатков означает, что дисперсия остатков ei
одинакова для каждого значения х.Если это условие применения МНК не
соблюдается, то имеет место гетероскедастичность. Наличие гетероскедастичности
можно наглядно видеть из поля корреляции. а — дисперсия остатков растет
по мере увеличения х; б — дисперсия остатков достигает максимальной
величины при средних значениях переменной х и уменьшается при
минимальных и максимальных значениях х; в — максимальная дисперсия
остатков при
малых значениях х и дисперсия остатков однородна по мере увеличения
значений х. Графики гомо- и гетеро-ти.
Оценка отсутствия автокорреляции остатков(т.е. значения остатков e
i распределены независимо друг от друга). Автокорреляция остатков
означает наличие корреляции между остатками текущих и предыдущих (последующих)
наблюдений. Коэффициент корреляции между ei и ej
, где ei — остатки текущих наблюдений, ej
— остатки предыдущих наблюдений, может быть определен по обычной формуле
линейного коэффициента корреляции
. Если этот коэффициент окажется существенно отличным от нуля, то остатки
автокоррелированы и функция плотности вероятности F(e) зависит j-й
точки наблюдения и от распределения значений остатков в других точках
наблюдения. Для регрессионных моделей по статической информации автокорреляция
остатков может быть подсчитана, если наблюдения упорядочены по фактору х
. Отсутствие автокорреляции остаточных величин обеспечивает состоятельность и
эффективность оценок коэффициентов регрессии. Особенно актуально соблюдение
данной предпосылки МНК при построении регрессионных моделей по рядам динамики,
где ввиду наличия тенденции последующие уровни динамического ряда, как
правило, зависят от своих предыдущих уровней.
22. Обобщенный метод наименьших квадратов.
Обобщённый метод наименьших квадратов (ОМНК, GLS — англ. Generalized Least Squares) — метод оценки параметров регрессионных моделей, являющийся обобщением классического метода наименьших квадратов. Обобщённый метод наименьших квадратов сводится к минимизации «обобщённой суммы квадратов» остатков регрессии — 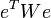 , где
, где  — вектор остатков,
— вектор остатков, 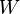 — симметрическая положительно определенная весовая матрица. Обычный МНК является частным случаем обобщённого, когда весовая матрица пропорциональна единичной.
— симметрическая положительно определенная весовая матрица. Обычный МНК является частным случаем обобщённого, когда весовая матрица пропорциональна единичной.
Необходимо отметить, что обычно обобщённым методом наименьших квадратов называют частный случай, когда в качестве весовой матрицы используется матрица, обратная ковариационной матрице случайных ошибок модели.
Известно, что симметрическую положительно определенную матрицу можно разложить как 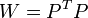 , где P- некоторая невырожденная квадратная матрица. Тогда обобщённая сумма квадратов может быть представлена как сумма квадратов преобразованных (с помощью P) остатков
, где P- некоторая невырожденная квадратная матрица. Тогда обобщённая сумма квадратов может быть представлена как сумма квадратов преобразованных (с помощью P) остатков 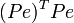 . Для линейной регрессии
. Для линейной регрессии 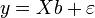 это означает, что минимизируется величина:
это означает, что минимизируется величина:
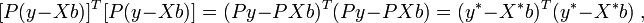
где 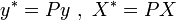 , то есть фактически суть обобщённого МНК сводится к линейному преобразованию данных и применению к этим данным обычного МНК. Если в качестве весовой матрицы используется обратная ковариационная матрица
, то есть фактически суть обобщённого МНК сводится к линейному преобразованию данных и применению к этим данным обычного МНК. Если в качестве весовой матрицы используется обратная ковариационная матрица 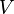 случайных ошибок
случайных ошибок  (то есть
(то есть 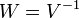 ), преобразование P приводит к тому, что преобразованная модель удовлетворяет классическим предположениям (Гаусса-Маркова), следовательно оценки параметров с помощью обычного МНК будут наиболее эффективными в классе линейных несмещенных оценок. А поскольку параметры исходной и преобразованной модели одинаковы, то отсюда следует утверждение — оценки ОМНК являются наиболее эффективными в классе линейных несмещенных оценок (теорема Айткена). Формула обобщённого МНК имеет вид:
), преобразование P приводит к тому, что преобразованная модель удовлетворяет классическим предположениям (Гаусса-Маркова), следовательно оценки параметров с помощью обычного МНК будут наиболее эффективными в классе линейных несмещенных оценок. А поскольку параметры исходной и преобразованной модели одинаковы, то отсюда следует утверждение — оценки ОМНК являются наиболее эффективными в классе линейных несмещенных оценок (теорема Айткена). Формула обобщённого МНК имеет вид:
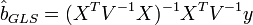
Ковариационная матрица этих оценок равна:
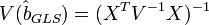
23. Взвешенный метод наименьших квадратов.
Если случайные ошибки модели регрессии подвержены гетероскедастичности (но являются неавтокоррелированными), то для оценивания неизвестных коэффициентов модели регрессии применяется взвешенный метод наименьших квадратов.
Суть взвешенного метода наименьших квадратов состоит в том, что остаткам обобщённой модели регрессии придаются определённые веса, которые равны обратным величинам соответствующих дисперсий G2(εi). Однако на практике значения дисперсий являются величинами неизвестными, поэтому для вычисления наиболее подходящих весов используется предположение о том, что они пропорциональны значениям факторных переменных xt.
Таким образом, матрица ковариаций случайных ошибок модели регрессии определяется исходя из предположения о пропорциональности величины G2(εi) значениям факторной переменнойxt:
xt=γ G(εi),
где γ – ошибка высказанного предположения или некоторая поправка. В этом случае матрица ковариаций случайных ошибок модели регрессии может быть представлена в виде:
От точности оценки матрицы ковариаций Ω случайных ошибок модели регрессии зависит удовлетворение оценок неизвестных коэффициентов, полученных доступным обобщённым или взвешенным методом наименьших квадратов, основным статистическим свойствам – несмещённости, состоятельности и эффективности.
24. Устранение нарушений предпосылок МНК (наличие автокорреляции в остатках).
25. Процедура Оркутта-Кокроуна.
26. Понятие линейной многофакторной регрессии.
Пусть требуется оценить прогнозное значение признака-результата для заданного значения признака-фактора 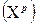 .
.
Прогнозируемое значение признака-результата с доверительной вероятностью равной (1-a) принадлежит интервалу прогноза:
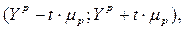
где 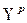 - точечный прогноз;
- точечный прогноз;
t - коэффициент доверия, определяемый по таблицам распределения Стьюдента в зависимости от уровня значимости a и числа степеней свободы (n-2);
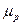 - средняя ошибка прогноза.
- средняя ошибка прогноза.
Точечный прогноз рассчитывается по линейному уравнению регрессии:
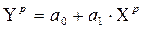 .
.
Средняя ошибка прогноза в свою очередь:
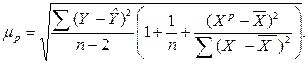
27. Показатели качества подгонки для многофакторной линейной регрессии. Частные коэффициенты эластичности.
Среди нелинейных функций, которые могут быть приведены к линейному виду, в эконометрических исследованиях очень широко используется степенная функция:
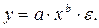
Связано это с тем, что параметр bв ней имеет четкое экономическое истолкование, т. е. он является коэффициентом эластичности. Это значит, что величина коэффициента bпоказывает, на сколько процентов изменится в среднем результат, если фактор изменится на 1 %.
Например, если зависимость спроса от цен характеризуется уравнением вида 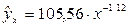 , то с увеличением цен на 1 % спрос снижается в среднем на 1,12 %.
, то с увеличением цен на 1 % спрос снижается в среднем на 1,12 %.
В силу того, что коэффициент эластичности для нелинейной функции не является величиной постоянной, а зависит от соответствующего значения х, то обычно рассчитывается средний показатель эластичности по формуле:
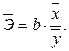
Поскольку коэффициенты эластичности представляют экономический интерес, а виды моделей не ограничиваются только степенной функцией, приведем формулы расчета коэффициентов эластичности для наиболее распространенных типов уравнений регрессии.

