 2015-04-20
2015-04-20 15719
15719Данный класс нелинейных моделей подразделяется на два типа: нелинейные модели внутренне линейные и нелинейные модели внутренне нелинейные.
Если нелинейная модель внутренне линейна, то она с помощью соответствующих преобразований может быть приведена к линейному виду.
Если нелинейная модель внутренне нелинейна, то она не может быть сведена к линейной функции.
Например, в эконометрических исследованиях при изучении эластичности спроса от цен широко используется степенная функция:
y = axb ε
где у – спрашиваемое количество;
х – цена;
ε – случайная ошибка.
Данная модель нелинейна относительно оцениваемых пaраметров, ибо включает параметры а и b неаддитивно. Однако ее можно считать внутренне линейной, ибо логарифмирование данного уравнения по основанию е приводит его к линейному виду:
lп у = lп а + b ln x + ln ε.
Соответственно оценки параметров а и b могут быть найдены МНК.
Если же модель представить в виде y = axb ε, то она становится внутренне нелинейной, ибо ее невозможно превратить в линейный вид. Внутренне нелинейной будет и модель вида — у = а + bхc + ε, ибо это уравнение не может быть преобразовано в уравнение, линейное по коэффициентам.
В специальных исследованиях по регрессионному анализу часто к нелинейным относят модели, только внутренне нелинейные по оцениваемым параметрам, а все другие модели, которые внешне нелинейны, но путем преобразований параметров могут быть приведены к линейному виду, относятся к классу линейных моделей.
В этом плане к линейным относят, например, экспоненциальную модель y = еa+bх ε, ибо логарифмируя ее по натуральному основанию, получим линейную форму модели
ln у = а + b х +lnε.
Среди нелинейных функций, которые могут быть приведены к линейному виду, в эконометрических исследованиях очень широко используется степенная функция y = axb ε.
Связано это с тем, что параметр b в ней имеет четкое экономическое истолкование, т. е. он является коэффициентом эластичности. Это значит, что величина коэффициента b показывает, на сколько процентов изменится в среднем результат, если фактор изменится на 1%.
В моделях, нелинейных по оцениваемым параметрам, но приводимых к линейному виду, МНК применяется к преобразованным уравнениям.
Если в линейной модели и моделях, нелинейных по переменным, при оценке параметров исходят из критерия
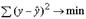 ,
,
то в моделях, нелинейных по оцениваемым параметрам, требование МНК применяется не к исходным данным результативного признака, а к их преобразованным величинам, т. е. lп у, 1 /у.
Так, в степенной функции y = axb ε МНК применяется к преобразованному уравнению lп у = lnа + x ln b.
Это значит, что оценка параметров основывается на минимизации суммы квадратов отклонений в логарифмах:
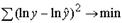
Вследствие этого оценки параметров для линеаризуемых функций МНК оказываются несколько смещенными. При исследовании взаимосвязей среди функций, использующих ln у, в эконометрике преобладают степенные зависимости – это и кривые спроса и предложения, и кривые Энгеля, и производственные функции, и кривые освоения для характеристики связи между трудоемкостью продукции и масштабами производства в период освоения выпуска нового вида изделий, и зависимость валового национального дохода от уровня занятости.
36. Нелинейные методы оценивания регрессии.Итерационные процедуры: Квази-Ньютоновский, симплексный и Розенброка методы.
Функцией потерь или ошибок называется функционал вида
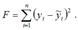
Также в качестве функции потерь может быть использована сумма модулей отклонений наблюдаемых значений результативного признака у от теоретических значений?:
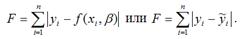
Функция потерь характеризует потери в точности аппроксимации исходных данных построенной моделью регрессии.
В интересах исследователя минимизировать функцию ошибок. Для этого используются различные методы, однако, их общий недостаток заключается в наличии локальных минимумов. Например, если оценка неизвестного параметра модели регрессии будет немного изменена, то значение функция потерь практически не изменится, но существует вероятность того, что ошибочное значение оцениваемого параметра модели регрессии даст в результате ощутимое уменьшение функции ошибок. Такое явление называется локальным минимумом.
Следствием локальных минимумов являются неоправданно завышенные или заниженные оценки неизвестных параметров модели регрессии.
Избежать попадания в локальный минимум можно путём повторения процедуры оценивания неизвестных параметров модели регрессии с изменёнными начальными условиями (шагом, ограничением оцениваемых параметров и т. д.).
При достижении функцией ошибок глобального минимума, оценки неизвестных коэффициентов модели регрессии считаются оптимальными.
К основным методам минимизации функции ошибок относятся:
Квази-ньютоновский метод. Как вы, наверное, помните, угловой коэффициент - тангенс угла наклона графика функции в конкретной точке равен производной этой функции (в этой точке), а скорость его изменения в выбранной точке равна второй производной функции в этой точке. Квази-ньютоновский метод вычисляет значения функции в различных точках для оценивания первой и второй производной, используя эти данные для определения направления изменения параметров и минимизации функции потерь. Симплекс-метод. Этот алгоритм не использует производные функции потерь. Вместо этого, при каждой итерации функция оценивается в m+1 точках m -мерного пространства. Например, на плоскости (т.е., при оценивании двух параметров) программа будет вычислять значение функции потерь в трех точках в окрестности текущего минимума. Эти три точки определяют треугольник; в многомерном пространстве. Получаемая фигура называется симплекс. Интуитивно понятно, что в двумерном пространстве три точки позволяют выбрать “в каком направлении двигаться”, т.е., в каком направлении на плоскости менять параметры для минимизации функции. Похожие принципы применимы в многомерном параметрическом пространстве; т.е., симплекс будет постепенно “смещаться вниз по склону”, в сторону минимизации функции потерь; если же текущий шаг окажется слишком большим для определения точного направления спуска, (т.е., симплекс слишком большой), процедура произведет уменьшение симплекса и продолжит вычисления. Дополнительное преимущество симплекс-метода в том, что при нахождении минимума симплекс снова увеличивается для проверки: не является ли этот минимум локальным. Таким образом, симплекс движется по поверхности по направлению к минимуму функции подобно простому, одноклеточному, организму, уменьшаясь и увеличиваясь при обнаружении локальных минимумов и “гребней”. Метод Розенброка. Даже если все остальные методы не сработали, метод Розенброка часто приводит к правильному результату. Этот метод вращает пространство параметров, располагая одну ось вдоль “гребня” поверхности (этот метод также называется метод вращения координат), при этом все другие остаются ортогональными выбранной оси. Если поверхность графика функции потерь имеет одну вершину и различимые “гребни” в направлении минимума функции потерь, этот метод приводит к очень точным значениям параметров, минимизирующим функцию потерь. Однако следует отметить, что этот поисковый алгоритм остановится преждевременно, если на область значений параметров наложены несколько ограничений (отражающихся в штрафном значении; см. выше), которые пересекаются, приводя к обрыванию “гребня”.
37. Показатели качества подгонки для нелинейной регрессии.
Индексом корреляции для нелинейных форм связи называется коэффициент корреляции, который вычисляется для оценки качества построенной нелинейной модели регрессии.
Индекс корреляции для нелинейных форм вычисляется с помощью теоремы о разложении дисперсий по формуле:
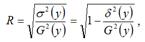 где G2(y) – это общая дисперсия зависимой переменной;
где G2(y) – это общая дисперсия зависимой переменной;
– это объяснённая с помощью построенной модели регрессии дисперсия переменной у, которая рассчитывается по формуле: 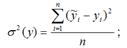
– необъяснённая или остаточная дисперсия переменной у, которая рассчитывается по формуле:
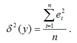
Также индекс корреляции для нелинейных форм можно рассчитать с помощью теоремы о разложении сумм квадратов по формуле:
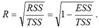
где RSS (Regression Sum Square) – сумма квадратов объяснённой регрессии:
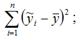
ESS (Error Sum Square) – сумма квадратов остатков модели множественной регрессии с n независимыми переменными:
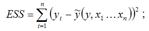
TSS (TotalSumSquare) – общая сумма квадратов модели множественной регрессии с n независимыми переменными:
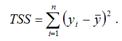
Индекс корреляции для нелинейных форм связи изменяется в пределах от нуля до единицы. С его помощью нельзя охарактеризовать направление связи между результативной и факторными переменными. Чем ближе значение индекса корреляции для нелинейных форм связи к единице, тем сильнее взаимосвязь между результативной и независимыми переменными, и наоборот, чем ближе значение индекса корреляции для нелинейных форм связи к нулю, тем слабее взаимосвязь между результативной и независимыми переменными.
Индексом детерминации называется квадрат индекса корреляции для нелинейных форм связи.
Расчёт индекса детерминации с помощью теоремы о разложении дисперсий:
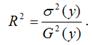
Расчёт индекса детерминации с помощью теоремы о разложении сумм квадратов:
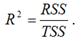
Индекс детерминации характеризует, на сколько процентов построенная модель регрессии объясняет вариацию значений результативной переменной относительно своего среднего уровня, т. е. показывает долю общей дисперсии результативной переменной, объяснённой вариацией факторных переменных, включённых в модель регрессии.
Коэффициент множественной детерминации также называется количественной характеристикой объяснённой построенной моделью регрессии дисперсии результативной переменной. Чем больше значение коэффициента множественной детерминации, тем лучше построенная модель регрессии характеризует взаимосвязь между переменными.
38. Метод Заренбеки выбора вида нелинейной регрессионной зависимости
39. Метод Бокса-Кокса вида нелинейной регрессионной зависимости
Если в начале эконометрического моделирования перед исследователем стоит выбор между моделью регрессии, внутренне нелинейной и линейной моделью регрессии (или сводящейся к линейному виду), то предпочтение отдаётся линейным формам моделей.
Однако многие модели регрессии различной функциональной формы нельзя сравнивать с помощью стандартных критериев (например, сравнение по множественному коэффициенту детерминации, или суммам квадратов отклонений), которые позволили бы подобрать наиболее подходящую модель регрессии.
Например, если перед исследователем стоит вопрос о выборе линейной или логарифмической моделями регрессии, то использовать при этом критерий суммы квадратов отклонений нельзя, потому что общая сумма квадратов отклонений для логарифмической модели намного меньше, чем для линейной модели регрессии. Это вызвано тем, что значение логарифма результативной переменной logy намного меньше, чем соответствующее значение у, поэтому сравнение сумм квадратов отклонений моделей даёт неадекватные результаты.
Если сравнивать данные модели по критерию коэффициента множественной детерминации, то мы вновь получим неадекватные результаты. Коэффициент множественной детерминации для линейной модели регрессии характеризует объяснённую регрессией долю дисперсии результативной переменной у. Индекс детерминации для логарифмической модели регрессии характеризует объяснённую регрессией долю дисперсии переменной logy. Если значения данных критериев примерно равны, то сделать выбор между моделями регрессии с их помощью также не представляется возможным.
Одним из методов проверки предположения о возможной линейной зависимости между исследуемыми переменными является метод проверки гипотезы о линейной зависимости между переменными с помощью коэффициента детерминации r2 и индекса детерминации R2.
Другим методом выбора функциональной зависимости между переменными является тест Бокса-Кокса.
Предположим, что перед исследователем стоит задача выбора между линейной и логарифмической моделями регрессии. Рассмотрим применение теста Бокса-Кокса на данном примере.
Тест Бокса-Кокса основывается на утверждении о том, что (у-1) и logy являются частными случаями функции вида
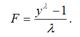
В том случае, если параметр λ равен единице, то данная функция принимает вид F=y-1.
В том случае, если параметр λ стремиться к нулю, то данная функция принимает вид F=logy.
Для того чтобы определить оптимальное значение параметра λ, необходимо провести несколько серий экспериментов с множеством значений данного параметра. С помощью такого перебора можно рассчитать такое значение параметра λ, которое даст минимальную величину критерия суммы квадратов отклонений. Подобный метод вычисления оптимального значения параметра называется поиском на решётке или на сетке значений.
П. Зарембеки разработал один из вариантов теста Бокса-Кокса специально для случая выбора между линейной и логарифмической моделями регрессии.
Суть данного теста заключается в том, что к результативной переменной у применяется процедура масштабирования. Подобное преобразование в дальнейшем позволит сравнивать величины сумм квадратов отклонений линейной и логарифмический моделей регрессий.
Тест Зарембеки реализуется в несколько шагов:
1) рассчитывается среднее геометрическое значений результативной переменной у по формуле:
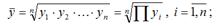
2) все результативные переменные у масштабируются по формуле:
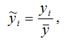
где ỹ i – масштабированное значение результативной переменной у для i -го наблюдения;
3) оценивается линейная модель регрессии с использованием масштабированных значений ỹ i результативной переменной вместо у, и логарифмическая модель регрессии с использованием ỹ i вместо logy. Все факторные переменные и коэффициенты регрессии остаются при этом неизменными. После такого масштабирования результативных переменных значения сумм квадратов отклонений для данных моделей регрессии можно сравнивать между собой. Поэтому выбирается та модель регрессии, для которой данный критерий окажется наименьшим.
40. Проверка основных гипотез для нелинейной регрессии.
На нелинейные модели регрессии, которые являются внутренне линейными, т. е. сводимыми к линейному виду, распространяются все методы проверки гипотез, используемые для классических линейных моделей регрессии.
Таким образом, если внутренне линейную модель регрессии можно свести к линейной модели парной регрессии, то на эту модель будут распространяться все методы проверки гипотез, используемые для парной линейной зависимости.
Проверка гипотезы о значимости линейной модели множественной регрессии состоит в проверке гипотезы значимости индекса детерминации R2.
Рассмотрим процесс проверки гипотезы о значимости индекса детерминации.
Основная гипотеза состоит в предположении о незначимости индекса детерминации, т. е.
Н0:R2=0.
Обратная или конкурирующая гипотеза состоит в предположении о значимости индекса детерминации, т. е.
Н1:R2 ≠ 0.
Данные гипотезы проверяются с помощью F-критерия Фишера-Снедекора.
Наблюдаемое значение F-критерия (вычисленное на основе выборочных данных) сравнивают со значением F-критерия, которое определяется по таблице распределения Фишера-Снедекора, и называется критическим.
При проверке значимости индекса детерминации критическое значение F-критерия определяется как Fкрит(a;k1;k2), где а – уровень значимости, k1=l-1 и k2=n-l – число степеней свободы, n – объём выборочной совокупности, l – число оцениваемых по выборке параметров.
При проверке основной гипотезы вида Н0:R2=0 наблюдаемое значение F-критерия Фишера-Снедекора рассчитывается по формуле:
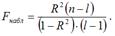
При проверке основной гипотезы возможны следующие ситуации.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) больше критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл›Fкрит, то с вероятностью а основная гипотеза о незначимости индекса детерминации отвергается, и он признаётся значимым. Следовательно, полученная модель регрессии также признаётся значимой.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) меньше или равно критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл=Fкрит, то основная гипотеза о незначимости индекса детерминации принимается, и он признаётся незначимым. Полученная модель регрессии является незначимой и нуждается в дальнейшей доработке.
Если в начале эконометрического моделирования перед исследователем стоит выбор между моделью регрессии, внутренне нелинейной и линейной моделью регрессии (или сводящейся к линейному виду), то предпочтение отдаётся линейным формам моделей.
Проверка предположения о возможной линейной зависимости между исследуемыми переменными осуществляется с помощью коэффициента детерминации r2 и индекса детерминации R2.
Выдвигается основная гипотеза Н0 о наличии линейной зависимости между переменными. Альтернативной является гипотеза Н1 о нелинейной зависимости между переменными.
Данные гипотезы проверяются с помощью t-критерия Стьюдента.
Наблюдаемое значение t-критерия (вычисленное на основе выборочных данных) сравнивают с критическим значением t-критерия, которое определяется по таблице распределения Стьюдента.
При проверке гипотезы о линейной зависимости между переменными критическое значение t-критерия определяется как tкрит(а;n-l-1), где а – уровень значимости, n – объём выборочной совокупности, l – число оцениваемых по выборке параметров, (n-l-1) – число степеней свободы, которое определяется по таблице распределений t-критерия Стьюдента.
При проверке основной гипотезы Н0 наблюдаемое значение t-критерия Стьюдента рассчитывается по формуле:
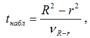
где V R-r – величина ошибки разности (R2-r2), которая определяется по формуле:
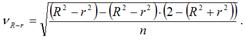
При проверке основной гипотезы возможны следующие ситуации.
Если наблюдаемое значение t-критерия (вычисленное по выборочным данным) больше критического значения t-критерия (определённого по таблице распределения Стьюдента), т. е. tнабл›tкрит, то с вероятностью а основная гипотеза о линейной зависимости между переменными отвергается. В этом случае построение нелинейной модели регрессии считается целесообразным.
Если наблюдаемое значение t-критерия (вычисленное по выборочным данным) меньше или равно критического значения t-критерия (определённого по таблице распределения Стьюдента), т. е. tнабл ≤ tкрит, то основная гипотеза о линейной зависимости между переменными принимается. Следовательно, взаимосвязь между данными переменными можно аппроксимировать простой линейной формой зависимости.
41. Понятие и назначение производственных функций.
Производственная функция – это зависимость между набором факторов производства и максимально возможным объемом продукта, производимым с помощью данного набора факторов.
Производственная функция всегда конкретна, т.е. предназначается для данной технологии. Новая технология – новая производительная функция.
С помощью производственной функции определяется минимальное количество затрат, необходимых для производства данного объема продукта.
Производственные функции, независимо от того, какой вид производства ими выражается, обладают следующими общими свойствами:
1) Увеличение объема производства за счет роста затрат только по одному ресурсу имеет предел (нельзя нанимать много рабочих в одно помещение – не у всех будут места).
2) Факторы производства могут быть взаимодополняемы (рабочие и инструменты) и взаимозаменяемы (автоматизация производства).
В наиболее общем виде производственная функция выглядит следующим образом: 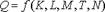 где Q- объем выпуска;
где Q- объем выпуска;
K- капитал (оборудование);
М- сырье, материалы;
Т – технология;
N – предпринимательские способности.
42. Производственная функция Кобба-Дугласа как пример нелинейной регрессии.
Первый успешный опыт построения производственной функции, как уравнения регрессии на базе статистических данных, был получен американскими учеными - математиком Д. Коббом и экономистом П. Дугласом в 1928 году. Предложенная ими функция изначально имела вид:
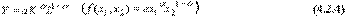
где Y - объем выпуска, K - величина производственных фондов (капитал), L - затраты труда, 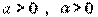 - числовые параметры (масштабное число и показатель эластичности). Благодаря своей простоте и рациональности, эта функция широко применяется до сих пор и получила дальнейшие обобщения в различных направлениях. Функцию Кобба-Дугласа иногда мы будем записывать в виде
- числовые параметры (масштабное число и показатель эластичности). Благодаря своей простоте и рациональности, эта функция широко применяется до сих пор и получила дальнейшие обобщения в различных направлениях. Функцию Кобба-Дугласа иногда мы будем записывать в виде
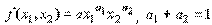
Легко проверить, что 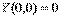 и
и
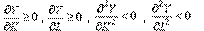
Кроме того, функция (4.2.4) линейно-однородна:
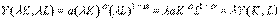 .
.
Таким образом, функция Кобба-Дугласа (4.2.4) обладает всеми вышеуказанными свойствами.
Для многофакторного производства функция Кобба-Дугласа имеет вид:
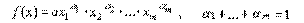
Для учета технического прогресса в функцию Кобба-Дугласа вводят специальный множитель (технического прогресса) 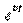 , где t - параметр времени,
, где t - параметр времени, 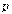 - постоянное число, характеризующее темп развития. В результате функция принимает "динамический" вид:
- постоянное число, характеризующее темп развития. В результате функция принимает "динамический" вид:
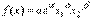
где не обязательно 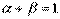 . Как будет показано в следующем параграфе, показатели степени в функции (4.2.4) имеют смысл эластичности выпуска по капиталу и труду.
. Как будет показано в следующем параграфе, показатели степени в функции (4.2.4) имеют смысл эластичности выпуска по капиталу и труду.
43. Коэффициенты эластичности для нелинейной регрессионных моделей.
Коэффициенты эластичности наряду с индексами корреляции и детерминации для нелинейных форм связи применяются для характеристики зависимости между результативной переменной и факторными переменными. С помощью коэффициентов эластичности можно оценить степень зависимости между переменными х и у.
Коэффициент эластичности показывает, на сколько процентов изменится величина результативной переменной у, если величина факторной переменной изменится на 1 %.
В общем случае коэффициент эластичности рассчитывается по формуле:
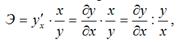
где 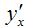 – первая производная результативной переменной у по факторной переменной x.
– первая производная результативной переменной у по факторной переменной x.
Коэффициенты эластичности могут быть рассчитаны как средние и точечные коэффициенты.
Средний коэффициент эластичности характеризует, на сколько процентов изменится результативная переменная у относительно своего среднего уровня 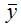 если факторная переменная х изменится на 1 % относительного своего среднего уровня
если факторная переменная х изменится на 1 % относительного своего среднего уровня 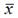
Общая формула для расчёта коэффициента эластичности для среднего значения факторной переменной х:
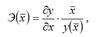 где
где 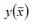 – значение функции у при среднем значении факторной переменной х.
– значение функции у при среднем значении факторной переменной х.
Для каждой из разновидностей нелинейных функций средние коэффициенты эластичности рассчитываются по индивидуальным формулам.
Для линейной функции вида: yi=β0+β1xi, средний коэффициент эластичности определяется по формуле: 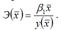
Для полиномиальной функции второго порядка (параболической функции) вида: 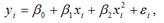 средний коэффициент эластичности определяется по формуле:
средний коэффициент эластичности определяется по формуле: 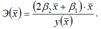
Для показательной функции вида: 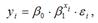 средний коэффициент эластичности определяется по формуле:
средний коэффициент эластичности определяется по формуле: 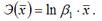
Для степенной функции вида: 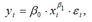 средний коэффициент эластичности определяется по формуле:
средний коэффициент эластичности определяется по формуле: 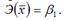 Это единственная нелинейная функция, для которой средний коэффициент эластичности
Это единственная нелинейная функция, для которой средний коэффициент эластичности 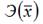 равен коэффициенту регрессии β1.
равен коэффициенту регрессии β1.
Точечные коэффициенты эластичности характеризуются тем, что эластичность функции зависит от заданного значения факторной переменной х1.
Точечный коэффициент эластичности характеризует, на сколько процентов изменится результативная переменная у относительно своего значения в точке х1, если факторная переменная изменится на 1 % относительно заданного уровня х1.
Общая формула для расчёта коэффициента эластичности для заданного значения х1 факторной переменной х: 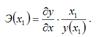
Для каждой из разновидностей нелинейных функций средние коэффициенты эластичности рассчитываются по индивидуальным формулам.
Для линейной функции вида: yi=β0+β1xi, точечный коэффициент эластичности определяется по формуле:
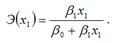 В знаменателе данного показателя стоит значение линейной функции в точке х1.
В знаменателе данного показателя стоит значение линейной функции в точке х1.
Для полиномиальной функции второго порядка (параболической функции) вида:  точечный коэффициент эластичности определяется по формуле:
точечный коэффициент эластичности определяется по формуле: 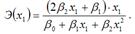 В знаменателе данного показателя стоит значение параболической функции в точке х1.
В знаменателе данного показателя стоит значение параболической функции в точке х1.
Для показательной функции вида: 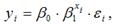 точечный коэффициент эластичности определяется по формуле:
точечный коэффициент эластичности определяется по формуле: 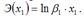
Для степенной функции вида: 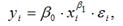 точечный коэффициент эластичности определяется по формуле:
точечный коэффициент эластичности определяется по формуле: 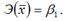
Чаще всего коэффициенты эластичности применяются в анализе производственных функций. Однако их расчёт не всегда имеет смысл, потому что в некоторых случаях интерпретация факторных переменных в процентном отношении невозможна или бессмысленна.
44. Определение регрессионных моделей с дискретной зависимой переменной.
Результативная переменная у в нормальной линейной модели регрессии является непрерывной величиной, способной принимать любые значения из заданного множества. Но помимо нормальных линейных моделей регрессии существуют модели регрессии, в которых переменная у должна принимать определённый узкий круг заранее заданных значений.
Моделью бинарного выбора называется модель регрессии, в которой результативная переменная может принимать только узкий круг заранее заданных значений
В качестве примеров бинарных результативных переменных можно привести:
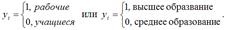
Приведенные в качестве примеров бинарные переменные являются дискретными величинами. Бинарная непрерывная величина задаётся следующим образом: 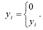
Если стоит задача построения модели регрессии, включающей результативную бинарную переменную, то прогнозные значения yiпрогноз, полученные с помощью данной модели, будут выходить за пределы интервала [ 0;+1 ] и не будут поддаваться интерпретации. В этом случае задача построения модели регрессии формулируется не как предсказание конкретных значений бинарной переменной, а как предсказание непрерывной переменной, значения которой заключаются в интервале [ 0;+1 ].
Решением данной задачи будет являться кривая, удовлетворяющая следующим трём свойствам:
1) 1) F(–∞)=0;
2) F(+∞)=1;
3) F(x1)>F(x2) при условии,что x1> x2.
Данным трём свойствам удовлетворяет функция распределения вероятности.
Модель парной регрессии с результативной бинарной переменной с помощью функции распределения вероятности можно представить в следующем виде: prob (yi =1)= F (β0+β1 xi), где prob(yi=1) – это вероятность того, что результативная переменная yi примет значение, равное единице.
В этом случае прогнозные значения yiпрогноз, полученные с помощью данной модели, будут лежать в пределах интервала [ 0;+1 ].
Модель бинарного выбора может быть представлена с помощью скрытой или латентной переменной следующим образом: 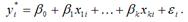
Векторная форма модели бинарного выбора с латентной переменной: 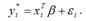
В данном случае результативная бинарная переменная yi принимает значения в зависимости от латентной переменной yi*:
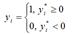
45. Логит, пробит и экстрим модели.
Модель бинарного выбора называется пробит-моделью или пробит-регрессией (probit regression), если она удовлетворяет двум условиям:
1) остатки модели бинарного выбора εi являются случайными нормально распределёнными величинами;
2) функция распределения вероятностей является нормальной вероятностной функцией.
Пробит-регрессия может быть представлена с помощью выражения:
NP(yi)=NP(β 0+ β 1x1i+…+ β kxki),
где NP – это нормальная вероятность (normal probability).
Модель бинарного выбора называется логит-моделью или логит-регрессией (logit regression), если случайные остатки εi подчиняются логистическому закону распределения.
Логит-регрессия может быть представлена с помощью выражения: 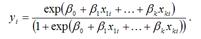
Данная модель логит-регрессии характеризуется тем, что при любых значениях факторных переменных и коэффициентов регрессии, значения результативной переменной yi будут всегда лежать в интервале [0;+1].
Обобщённый вид модели логит-регрессии: 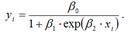
Достоинством данной модели является то, что результативная переменная yi может произвольно меняться внутри заданного числового интервала (не только от нуля до плюс единицы).
Логит-регрессия относится к классу функций, которые можно привести к линейному виду. Это осуществляется с помощью преобразования, носящего название логистического или логит преобразования, которое можно проиллюстрировать на примере преобразования обычной вероятности р: 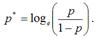
Качество построенной логит-регрессии или пробит-регрессии характеризуется с помощью псевдо коэффициента детерминации, который рассчитывается по формуле: 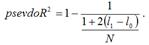
Если значение данного коэффициента близко к единице, то модель регрессии считается адекватной реальным данным.
46. Селекция моделей бинарного выбора с помощью информационных критериев Акайке и Шварца
Основными показателями качества модели авторегрессии и проинтегрированного скользящего среднего являются критерий Акайка и байесовский критерий Шварца. Данные критерии аналогичны критерию максимума скорректированного множественного коэффициента детерминации R2 или минимума дисперсии случайной ошибки модели G2.
Информационный критерий Акайка (Akaike information criterion – AIC) используется для выбора наилучшей модели для временного ряда yt из некоторого множества моделей.
Предположим, что с помощью метода максимального правдоподобия была получена оценка 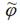 вектора неизвестных параметров модели φ. Обозначим через
вектора неизвестных параметров модели φ. Обозначим через 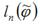 максимальное значение логарифмической функции правдоподобия эконометрической модели.Тогда критерий Акайка можно будет представить в виде:
максимальное значение логарифмической функции правдоподобия эконометрической модели.Тогда критерий Акайка можно будет представить в виде:
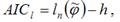 где h – размерность вектора неизвестных параметров модели φ.
где h – размерность вектора неизвестных параметров модели φ.
Для линейной или нелинейной модели регрессии, включающей только одно уравнение, критерий Акайка может быть преобразован к виду: 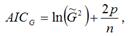 где n – объём выборочной совокупности;
где n – объём выборочной совокупности;
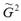 – оценка максимального правдоподобия дисперсии остатков et модели регрессии.
– оценка максимального правдоподобия дисперсии остатков et модели регрессии.
Оба варианта критерия Акайка дают одинаковый результат, но в первом случае выбирается модель с наибольшим значением критерия, а во втором случае – с наименьшим значением критерия.
Байесовский критерий Шварца (Schwarz Bayesian criterion – SBC) также используется для выбора наилучшей модели временного ряда из некоторого множества моделей.
Байесовский критерий Шварца для временных рядов можно представить в виде: 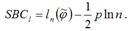
Байесовский критерий Шварца для моделей регрессии можно представить в виде: 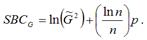
По первому варианту расчёта критерия Байесовского критерий Шварца SBC выбирается та модель, для которой значение SBCt является наибольшим. При втором варианте выбирается та модель, для которой значение SBCG является наименьшим.
При проверке качества моделей результаты критериев Акайка и Шварца могут быть различны.
47. Оценка бинарных моделей методом макимального правдподобия
Метод максимума правдоподобия. Альтернативой использования метода наименьших квадратов (см выше) является поиск максимума функции правдоподобия или ее логарифма. Эквивалентным способом является минимизация логарифма функции правдоподобия со знаком минус. В общем виде, функцию правдоподобия определяется так:
L = F(Y,Модель) =  in= 1 {p [yi, Параметры модели(xi)]}
in= 1 {p [yi, Параметры модели(xi)]}
Теоретически, вы можете вычислить вероятность принятия зависимой переменной определенных значений(обозначенную нами L, от слова Likelihood - правдоподобие), используя соответствующую регрессионную модель. Воспользовавшись тем, что все наблюдения независимы друг от друга,
получим, что наша функция правдоподобия равна геометрической сумме (, для всех i = 1 to n) вероятностей конкретных наблюдений (i), заданных соответствующей значению x моделью и параметрами. (Геометрическая сумма означает, что нужно перемножить вероятности по всем возможным случаям внутри скобок.) Часто эти функции представляют в виде натурального логарифма, в этом случае геометрическая сумма становится обычной арифметической суммой (, для всех i = 1 to n).
При выборе конкретной модели, чем больше правдоподобие модели, тем больше вероятность, что предсказанное значение зависимой переменной окажется в выборке. Поэтому, чем больше правдоподобие, тем лучше модель согласуется с выборочными данными. Реальные вычисления для конкретной модели могут оказаться достаточно громоздкими, поскольку вам необходимо “отслеживать” (вычислять) вероятности появления различных значений зависимой переменной y (выбрав модель и соответствующее значение x). Оказывается, что если все предположения для стандартной множественной регрессии выполнены (они описаны в главе Множественная регрессия руководства пользователя), то стандартный метод наименьших квадратов (см. выше) дает те же оценки, что и метод максимума правдоподобия. Если предположение о постоянстве дисперсии ошибки при всех значения независимой переменной нарушено, то оценки по методу максимума правдоподобия можно получить используя метод взвешенных наименьших квадратов.
48. Показатели качества подгонки для бинарных моделей. Коэффициент Макфаддена.
Статистика отношения правдоподобия
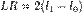 ,
,
где 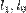 — значения логарифмической функции правдоподобия оцененной модели и ограниченной модели, в которой
— значения логарифмической функции правдоподобия оцененной модели и ограниченной модели, в которой 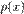 является константой (не зависит от факторов x, исключая константу из множества факторов).
является константой (не зависит от факторов x, исключая константу из множества факторов).
Данная статистика, как и в общем случае использования метода максимального правдоподобия, позволяет тестировать статистическую значимость модели в целом. Если её значение достаточно большое (больше критического значения распределения 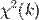 , где
, где 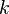 -количество факторов (без константы) модели), то модель можно признать статистически значимой.
-количество факторов (без константы) модели), то модель можно признать статистически значимой.
Также используются аналоги классического коэффициента детерминации, например:
Псевдо-коэффициент детерминации:
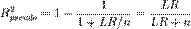
Коэффициент детерминации МакФаддена (индекс отношения правдоподобия):
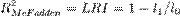
Оба показателя меняются в пределах от 0 до 1.
Информационные критерии: информационный критерий Акаике (AIC), байесовский информационный критерий Шварца (BIC, SC), критерий Хеннана-Куина (HQ).
Важное значение имеет анализ доли правильных прогнозов в зависимости от выбранного порога классификации (с какого уровня вероятности принимается значение 1). Обычно применяется ROC-кривая для оценки качества модели и показатель AUC - площадь под ROC-кривой.
Статистика Хосмера-Лемешоу (H-L, HL, Hosmer-Lemeshow). Для расчета данной статистики выборка разбивается на несколько подвыборок, по каждой из которых определяются — фактическая доля данных со значением зависимой переменной 1, то есть фактически среднее значение зависимой переменной по подвыборке
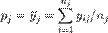
и предсказанная средняя вероятность по подруппе
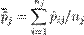 .
.
Тогда значение статистики HL определяется по формуле
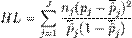
Точное распределение данной статистики неизвестно, однако авторы методом симуляций установили, что оно аппроксимируется распределением 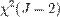 .
.
49. Проверка значимости уравнения бинарной регрессионной модели на основе теста отношения правдоподобия (LR-тест)

