 2015-04-23
2015-04-23 328
328Пусть исследовались возрастные изменения времени реакции у водителей грузовиков и использовался тест определения времени реакции в разных условиях видимости. Были получены результаты:
| Время реакции | 85,6 | 73,3 | 71,0 | 89,1 | 83,1 | 76,9 | 94,5 | 93,6 | 86,9 |
| Возраст | |||||||||
| Уровень видимости |
Необходимо выявить, существует ли взаимосвязь между возрастом, уровнем видимости и временем реакции.
Решение. Для выполнения корреляционного анализа вводим в диапазон А1:I3 исходные данные:
| А | В | С | D | Е | F | G | Н | I | |
| 85,6 | 73,3 | 71,0 | 89,1 | 83,1 | 76,9 | 94,5 | 93,6 | 86,9 | |
Затем в меню Сервис выбираем пункт Анализ данных и далее указываем строку Корреляция. В появившемся диалоговом окне указываем входной диапазон A1:I3 или выделяем указанный диапазон мышью на листе Excel.
Указываем, что данные рассматриваются по строкам. Указываем выходной диапазон. Для этого ставим флажок в левое поле Выходной интервал и в правое поле ввода Выходной интервал вводим А5 (рис.5.2). Нажимаем кнопку ОК.
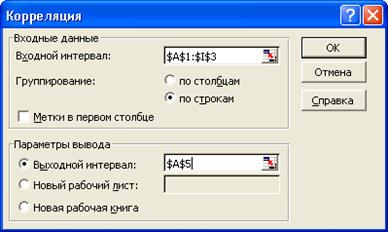
Рис. 5.2
Результаты анализа. В выходном диапазоне получаем корреляционную матрицу:
| Строка 1 | Строка 2 | Строка 3 | ||||||
| Строка 1 | ||||||||
| Строка 2 | 0,768733 | |||||||
| Строка 3 | -0,58348 | |||||||
Интерпретация результатов. Из таблицы видно, что корреляция между временем реакции (1 строка) и возрастом (2 строка) равна примерно 0,77, а между временем реакции (1 строка) и уровнем видимости (3 строка) – 0,59, между уровнем видимости (3 строка) и возрастом (2 строка) r = 0.
Таким образом, в результате анализа выявлены зависимости: сильная степень линейной связи между временем реакции и возрастом (r = 0,77) и средняя обратная линейная связь между временем реакции и уровнем видимости (r = – 0,59).
§ 6. Регрессия Использование Мастера функцийРегрессионный анализ чаще всего используется для предсказывания среднего значения одной случайной величины по отдельному значению другой случайной величины. В Мастере функций имеется такая функция ПРЕДСКАЗ.
Функция ПРЕДСКАЗ вычисляет или предсказывает будущее значение по существующим значениям. Предсказываемое значение – это среднее y-значение, соответствующее заданному x-значению. Известные значения – это x- и y-значения, а новое значение предсказывается с использованием линейной регрессии.
Синтаксис функции (рис. 6.1):
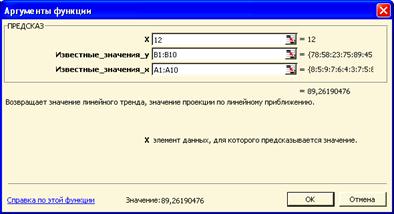
Рис. 6.1
ПРЕДСКАЗ (x; известные_значения_y; известные_значения_x)
х – это точка данных, для которой предсказывается значение.
Известные_значения_y – это зависимый массив или интервал данных.
Известные_значения_x – это независимый массив или интервал данных.








