 2015-05-14
2015-05-14 468
468Задание 1. В таблице П2 Приложения 2 приведены показатели уровня жизни по территориям регионов Республики Беларусь за 200Хг. Провести анализ зависимости среднедневной заработной платы, руб. (Y) от среднедушевого прожиточного минимума в день одного трудоспособного, руб. (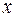 ).
).
Последовательность проведения регрессионного анализа:
1) открыть модуль Multiple regression(Множественная регрессия);
2) создать или открыть файл данных (zarplata.sta);
3)идентифицировать переменные – выбрать список зависимых и независимых переменных;
4) выбрать вид модели;
4) провести оценивание параметров модели;
5) проверить качество полученных оценок параметров;
6) провести анализ адекватности модели.
В пакете STATISTICA откройте модульMultiple regression (Множественная регрессия). В стартовой панели модуля нажмите кнопку OpenData(Открыть данные) и откройте файл данных zarplata.sta, в котором находятся исходные данные, либо выполните команду File/New Data и введите исходные данные для переменных X,Yв столбцы Var1 и Var2.При этом лишние столбцы Var3-Var10 можно удалить командой Variablesà Delete меню Edit, строки – добавить командой Casesà Add меню Edit ( см. рис.11.1).
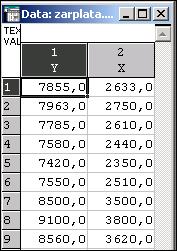
Рис.11.1 – Исходные данные для построения модели
Сделайте активным окно с таблицей данных и в меню Analisis выберите команду ResumeAnalisis. На экране появится окно Multipleregression. Далее с помощью кнопки Variables(Переменные) перейдите в окно Select dependent and independent variable list (Выбрать списки зависимых и независимых переменных) и выберите переменные для анализа. Зависимую переменную Y – среднедневная заработная плата, руб. – внесите в строку Dependentvariablelist(Список зависимых переменных),независимую переменную X – среднедушевой прожиточный минимум в день одного трудоспособного, руб. – внесите в строку Independentvariablelist(Список независимых переменных) инажмите кнопку ОК.Вы вновь окажетесь в стартовой панели модуля (см.рис. 11.2).
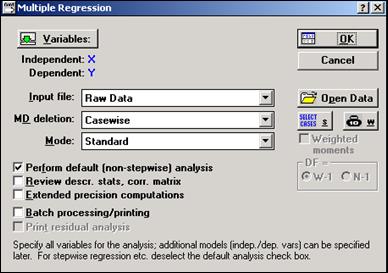
Рис.11.2 – Окно Multiple regression
Переменные для анализа выбраны. Никаких дополнительных установок в стартовой панели в данном случае производить не нужно. Нажмите кнопку ОК. На экране перед вами появится диалоговое окно MultipleRegressionResults (Результаты множественнойрегрессии).
В диалоговом окне MultipleRegressionResults (Результаты множественнойрегрессии) можно просмотреть результаты оценивания, которые представлены в численном и графическом виде(рис. 11.3).
Окно результатов анализа имеет следующую структуру: верх окна — информационный. Он состоит из двух частей: в первой части содержится основная информация о результатах оценивания, во второй высвечиваются значимые регрессионные коэффициенты. Внизу окна Результатымножественнойрегрессии находятся функциональные кнопки, позволяющие всесторонне просмотреть результаты анализа.
Рассмотрим вначале информационную часть окна. В ней содержатся краткие сведения о результатах анализа, а именно:
• Dep. Var. (Имя зависимой переменной) - в данном случае Y;
• No. of Cases (Число наблюдений, по которым построена регрессия) - в примере это число равно 16;
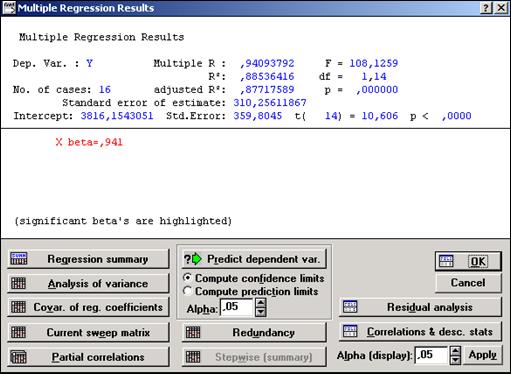
Рис. 11.3 – Окно Результаты множественной регрессии
• Multiple R (Коэффициент множественной корреляции);
• R-square (R2, - к оэффициент детерминации,квадрат коэффициентамножественной корреляции) используется для статистической оценки тесноты связи между результативным и объясняющими показателями. Он выражает долю объясненной изучаемыми факторами дисперсии результативного признака и служит важной характеристикой качества построенной модели. Этот коэффициент может принимать значения от 0 до 1. Несмещенной оценкой R2 служит скорректированный на потерю степеней свободы коэффициент множественной детерминации (Adjusted R2);
•Adjusted R-square (Скорректированный коэффициентдетерминации), определяемый как
Adjusted R-square = 1 - (1- R2, )ּ(n/(n–p)),
где n — число наблюдений в модели, p — число параметров модели (число независимых переменных плюс 1, так как в модель включен свободный член);
• Std. Error of estimate (Стандартная ошибкаоценки) - эта статистика является мерой рассеяния наблюдаемых значений относительно регрессионной прямой;
• Intercept (Оценка свободного члена регрессии) - значение коэффициента В0 в уравнении регрессии;
• Std. Error (Стандартная ошибка оценки свободного члена) - стандартная ошибка коэффициента В 0 в уравнении регрессии;
• t(df) and p-value (Значение t-критерия и уровень р) - t -критерий используется для проверки гипотезы о равенстве 0 свободного члена регрессии;
• F– критерий Фишера, определяющий значимость полученной модели. Оценивает вероятность случайного отклонения от нуля коэффициента детерминации при отсутствии связи между элементами совокупности. Желательно, чтобы полученный минимальный уровень значимости F -критерия (p-level) был меньше 0,05;
• df— число степеней свободы F-критерия;
• р — уровень значимости.
В информационной части посмотрим прежде всего на значения коэффициента детерминации, которые лежат в пределах от 0 до 1. В нашем примере R 2, = 0,885. Это значение показывает, что построенная регрессия объясняет более 88,5% разброса значений переменной Y относительно среднего.
Далее посмотрите на значение F -критерия и уровень значимости р. F -критерий используется для проверки гипотезы о значимости регрессии. В данном случае для проверки гипотезы, утверждающей, что между зависимой переменной Y и независимой переменной Xнет линейной зависимости, т. е. В1 = 0, против альтернативы В1 не равен 0. В данном примере мы имеем большое значение F -критерия — 108,12, а представленный в окне уровень значимости p = 0,00 показывает, что построенная регрессия высоко значима.
Рассмотрим вторую часть информационного окна. В ней представлена информация о значимых и незначимых оценках регрессионных коэффициентов. При этом высвечивается строка x beta = 0,941 и приводится пояснение Significant beta's are highlighted (Значимые beta высвечены). Отметим, что в данном случае beta есть стандартизованный коэффициент В1, т. е. коэффициент при независимой переменной x.
Перейдем в функциональную часть окна результатов.
Прежде всего нажмите кнопку Regression summary (Итоговый результат регрессии). На экране появится Spreadsheet (Электронная таблица вывода), в которой представлены итоговые результаты оценивания регрессионной модели (рис. 11.4).
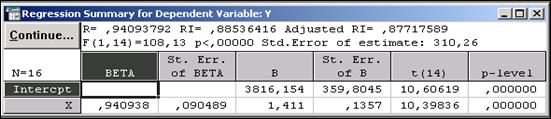
Рис. 11.4 – Итоговая таблица регрессии
В первом столбце таблицы даны значения коэффициентов beta (стандартизованные коэффициентырегрессионного уравнения ), во втором — стандартные ошибки этих коэффициентов, в третьем — точечные оценки параметров модели:
· cвободный член В0= 3816,154;
· коэффициент В1 (при независимой переменной X) = 1,411.
Далее представлены стандартные ошибки для В0, В1, значения статистик t- критерия. По итоговой таблице регрессии можно построить модель, которая имеет вид
Y = 1,411ּX +3816.154.
Оценка адекватности модели - важный элемент анализа. После того как доказана адекватность модели, полученные результаты можно уверенно использовать для дальнейших действий.
Анализ адекватности основывается на анализе остатков. Остатки представляют собой разности между наблюдаемыми значениями и модельными, т.е. значениями, подсчитанными по модели с оцененными параметрами. Графики зависимости регрессионных остатков от экспериментальных значений исходных переменных позволяют проверить предположения об однородности и независимости ошибок, являющихся предпосылками применения метода наименьших квадратов, и локализовать выбросы. Если указанные допущения выполняются, графики будут представлять собой симметричное, случайное и равномерное распределения точек. Графики эмпирической функции распределения остатков на нормальной вероятностной бумаге (Probability plots) и гистограммы позволяют проверить справедливость предположения о нормальном распределении остатков.
Кроме этого, имеется возможность вычислить статистику Дарбина–Уотсона (Darbin-Watson Stat) для проверки наличия автокорреляции в остатках, вывести на экран (Display residuals&pred) и сохранить в файле (Save residuals) информацию о наблюдаемых и подобранных по модели значениях результативного показателя и остатках. Рекомендуется также построить график линейной зависимости предсказанных (подобранных по модели) значений зависимой переменной от наблюдаемых (Predicted & Observed), что позволяет наглядно изобразить результаты регрессионного анализа.
В модуле Множественная регрессия имеется специальное диалоговое окно, в котором проводится всесторонний анализ остатков. Нажав кнопку Residual Analysis(Анализ остатков) в окне Multiple Regression Results,можно перейти в окно анализа остатков Residual Analysis (Анализ остатков) (см. рис. 11.5).
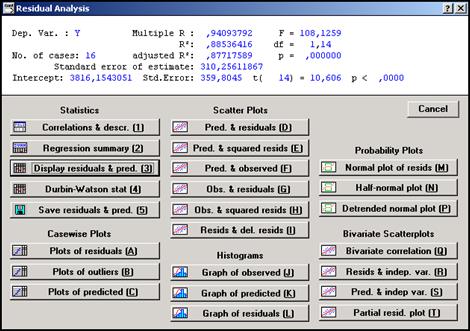
Рис. 11.5 – Окно Residual Analysis
Нажмите в этом окне, например, кнопку Obs&residuals, на экране появится график (рис.11.6), который говорит о достаточной адекватности модели.
Нажав кнопкуPredicted & Observed), можно наглядно изобразить результаты регрессионного анализа: график линейной зависимости предсказанных (подобранных по модели) значений зависимой переменной от наблюдаемых (см. рис. 11.7).
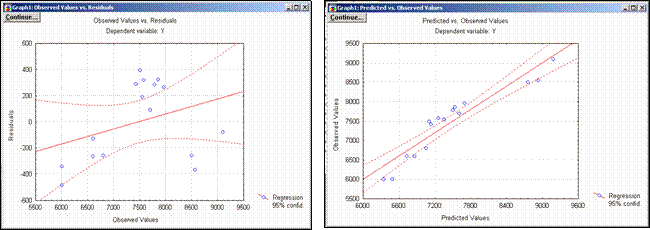
| Рис.11.6 – График наблюдаемых | Рис. 11.7 – График наблюдаемых |
| переменных-остатков | и предсказанных значений |
Для получения описательной статистики в окне MultipleRegressionResultsнужно нажать кнопку Correlations&desc.stats,после чего на экране появится окно ReviewDescriptiveStatistics, из которого следует выбрать необходимые для анализа статистики (см. рис. 11.8).
Рис. 11.8 – Окно Review Descriptive Statistics
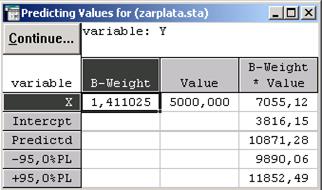
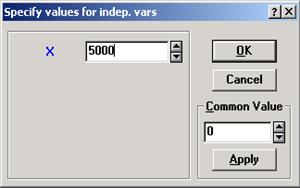
Чтобы получить прогноз значения зависимой переменной Y, в окнеMultipleRegressionResultsследует нажать кнопкуPredictdependentvarи в появившееся на экране окноSpecifyvaluesforindep.varsввести новое значение Х, например 5000 (см. рис. 11.9), и нажать ОК. В результате в окне Predictingvaluesfor(см. рис.11.10)на основании полученного ранее уравнения регрессии
Y = 1,411ּX +3816.154
будет рассчитано прогнозируемое значение Y (в данном случае 10871,28).
 | |||
 | |||
| Рис.11.9 – Окно Specify values | Рис.11.10 – Окно Predicting values for |
| for indep. vars |
Кроме аналитического расчета регрессионной модели,STATISTICAпозволяетпостроить модель графическим способом.
Задание 2. В соответствии с условием задания 1 (см. выше) построить и представить однофакторную линейную и нелинейную регрессионную модель зависимости среднедневной заработной платы, руб. (Y) от среднедушевого прожиточного минимума в день одного трудоспособного, руб. ().
Для расчета модели графическим способом необходимо в стартовой панели программы STATISTICAвыбрать модуль « Основныестатистики » («Basic Statistica»). В меню GraphsàStats2D Graphs выбрать команду Scatterplots(диаграммы рассеяния). На экране появится диалоговое окно для построения 2D диаграмм рассеяния разного вида (линейного, логарифмического, экспоненциального, полиномиального и т.д.), отражающих зависимость переменных X и Y (см. рис.11.11).
Рис.11.11 – Окно 2D Scatterplots.
Если выбрать Линейную (Linear ) зависимость и нажать ОК, на экране появится окно диаграммы рассеяния (рис.11.12) для выбранных переменных, причем в верхней части окна будет представлено уравнение регрессии.
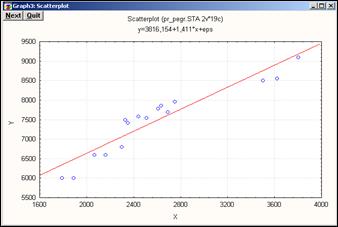
Рис.11.12 – Диаграмма рассеяния. Линейная зависимость
Из окна 2D Scatterplotsщелчком правой клавиши мыши по линии тренда можно легко построить диаграмму рассеяния любого из перечисленных видов, причем в верхней части окна будет выводиться и соответствующее уравнение регрессии (рис. 11.13 и рис.11.14). Если выбрать полиномиальную зависимость, то очевидно, что, чем выше степень 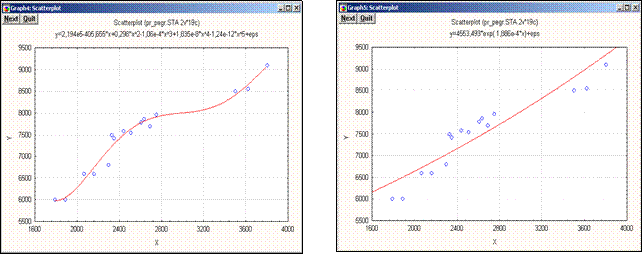 полинома, тем точнее линия тренда «ложится» на данные.
полинома, тем точнее линия тренда «ложится» на данные.
| Рис.11.13– Диаграмма рассеяния. | Рис.11.14– Диаграмма рассеяния. |
| Полиномиальная зависимость | Экспоненциальная зависимость |
Задания для самостоятельной работы 
Задание1. Средствами модуля Multiple Regression установить связь между анализируемыми данными (см. таблицу 11.1), построить и проанализировать экономико-математическую однофакторную регрессионную модель, позволяющую получить прогноз результативного признака на последующие периоды. Вывести всю возможную статистическую информацию. Построить график наблюдаемых и предсказанных значений. Аналитически и графически оценить качество модели.
Таблица 11.1. Показатели деятельности предприятия
| Номер предприятия | Выработка продукции на одного работника тыс. руб. | Новые ОПФ, % | Удельный вес рабочих высокой квалификации % | Коэффициент использования оборудования |
| № | Y | x1 | x2 | x3 |
| 3,9 | 0,76 | |||
| 3,9 | 0,78 | |||
| 3,7 | 0,75 | |||
| 0,78 | ||||
| 3,8 | 0,74 | |||
| 4,8 | 0,81 | |||
| 5,4 | 0,81 | |||
| 4,4 | 0,82 | |||
| 5,3 | 0,82 | |||
| 6,8 | 0,82 | |||
| 0,84 | ||||
| 6,4 | 0,84 | |||
| 6,8 | 0,8 | |||
| 7,2 | 0,8 | |||
| 0,85 | ||||
| 8,2 | 0,85 | |||
| 8,1 | 0,88 | |||
| 8,5 | 0,87 | |||
| 9,6 | 0,89 | |||
| 0,85 |
Варианты заданий
Варианты 1-4: результативный признак – Y, факторный признак – X1.
Варианты 5-7: результативный признак – Y, факторный признак – X2.
Варианты 8-10: результативный признак – Y, факторный признак – X3.








