2015-05-18
2015-05-18 1029
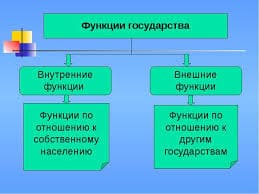
1029Обычно зависимую переменную называют результативным признаком, а независимую переменную — фактором. Очень часто наблюдается случай, когда результативный признак зависит не от одного, а от многих факторов.
Тогда вместо парной линейной регрессии используют множественную линейную регрессию: y = b0 + b1 x1 + b2 x2 +... + bm xm.
Пусть n – число наблюдений, m – число объясняющих переменных.
Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты. Воспользуемся надстройкой Пакет анализа.
Сервис → Анализ данных → Регрессия → ОК. Появляется диалоговое окно, которое нужно заполнить. В графе Входной интервал Y: указывается ссылка на ячейки, содержащие значения результативного признака y. В графе Входной интервал X: указывается ссылка на ячейки, содержащие значения факторов х1,..., xm (m < 16). Если первая из ячеек содержит пояснительный текст, то рядом со словом Метки нужно поставить «галочку».
Уровень надежности (доверительная вероятность) по умолчанию предполагается равным 95%. Если исследователя это значение не устраивает, то рядом со словами Уровень надежности нужно поставить «галочку» и указать требуемое значение. Поставив «галочку» рядом со словом константа-ноль, исследователь получит b0 = 0 по умолчанию.
Если нужны значения остатков ei и их график, то нужно поставить «галочки» рядом со словами Остатки и Трафик остатков. Также указываются параметры вывода (Выходной интервал, Новый рабочий лист, Новая рабочая книга). ОК. Появляется итоговое окно.
Если число в графе Значимость F превышает 1 – Уровень надежности, то принимается гипотеза о равенстве нулю коэффициента детерминации.
Если P-значение превышает 1 – Уровень надежности, то соответствующая переменная статистически незначима и ее можно исключить из модели.
Нижние 95% и Верхние 95% – это нижние и верхние границы 95-процентных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии. Если исследователь согласился с принятым по умолчанию значением доверительной вероятности, то последние два столбца будут дублировать два предыдущих. Если исследователь вводил свое значение доверительной вероятности p, то последние два столбца содержат значения соответственно нижней и верхней границы p -процентных доверительных интервалов.