 2015-05-18
2015-05-18 1383
1383Обобщением парной линейной регрессионной модели является линейная регрессионная модель с m объясняющими переменными (линейная модель множественной регрессии):
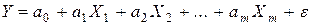 . (3.2)
. (3.2)
Здесь a = (a 0, a 1, …, am) – вектор неизвестных параметров размерности (m + 1).
Величина aj (j = 1, 2, …, m)называется j -м теоретическим коэффициентом регрессии. Он характеризует чувствительность величины Y к изменению Xj. Другими словами, коэффициент регрессии aj отражает влияние на функцию регрессии
y = a 0 + a 1 x 1 + a 2 x 2 + … + amxm (3.3)
объясняющей переменной Xj при условии, что все другие объясняющие переменные модели остаются постоянными: он показывает, на сколько единиц изменяется среднее значение результирующей переменной Y при увеличении объясняющей переменной Xj на одну единицу своего измерения. Величина a 0 – свободный член, определяющий значение функции регрессии (3.3), когда все объясняющие переменные равны нулю (если, конечно, это имеет смысл в рамках модели).
После выбора линейной функции в качестве модели зависимости рассматриваемых переменных необходимо оценить параметры этой модели.
Предположим, что проведено n наблюдений над объясняющими переменными X 1, X 2, …, Xm и зависимой переменной Y. Обозначим i -е значение зависимой переменной yi, а объясняющих переменных – 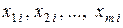 . Тогда для каждого наблюдения будет иметь место зависимость вида
. Тогда для каждого наблюдения будет иметь место зависимость вида
yi = a 0 + a 1 × x 1 i + a 2 × x 2 i + …. + am× xm i + e i, (3.4)
где e i – случайное возмущение i -го наблюдения, i = 1, 2, …, n.
Представим данные наблюдений и соответствующие коэффициенты в матричной форме:
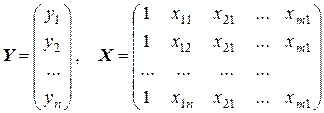 ,
, 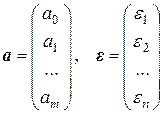 .
.
Здесь Y – n -мерный вектор-столбец значений зависимой переменной Y;
X – матрица размерности n ´ (m + 1), в которой (j + 1)-й столбец (j = 1, 2, …, m) представляет результаты наблюдений независимой переменной Xj (единичный столбец соответствует переменной при свободном члене a 0);
а – вектор-столбец размерности (m + 1) параметров модели;
e – вектор-столбец размерности n случайных возмущений (отклонений).
Тогда в матричной форме модель (3.4) примет вид:
Y = X × a + e. (3.5)
Как и в случае парной регрессии, истинные значения параметров a j (j = 0, 1, 2, …, m) по выборке получить невозможно, их можно только оценить. Поэтому определяются коэффициенты 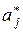 (j = 0, 1, 2, …, m) так называемого выборочного уравнения множественной регрессии:
(j = 0, 1, 2, …, m) так называемого выборочного уравнения множественной регрессии:
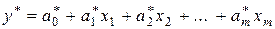 , (3.6)
, (3.6)
где – оценка неизвестного параметра a j (j = 0, 1, 2, …, m).
Самым распространенным методом нахождения оценок параметров множественной линейной регрессии является метод наименьших квадратов (МНК). Напомним, что его суть состоит в минимизации суммы квадратов отклонений ei наблюдаемых значений yi зависимой переменной Y от значений 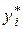 (i = 1, 2, …, n), получаемых по уравнению регрессии (3.6). Эти отклонения рассчитываются, очевидно, по формуле
(i = 1, 2, …, n), получаемых по уравнению регрессии (3.6). Эти отклонения рассчитываются, очевидно, по формуле
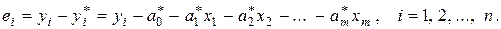 (3.7)
(3.7)
Согласно МНК, для нахождения оценок (j = 0, 1, 2, …, m) минимизируется функция
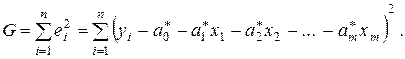
Необходимым условием минимума функции G является равенство нулю всех ее частных производных по (j = 0, 1, 2, …, m). Произведя необходимые вычисления и преобразования, получаем систему нормальных уравнений из
(m + 1) линейных уравнений с (m + 1) неизвестными:
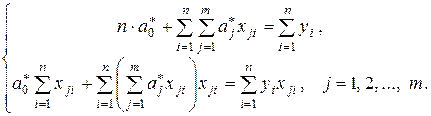 (3.8)
(3.8)
Запишем систему (3.8) в матричной форме:
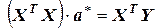 . (3.9)
. (3.9)
Здесь X T – матрица, транспонированная к X;
a * – вектор-столбец размерности (m + 1) оценок (j = 0, 1, 2, …, m)
параметров модели;
Y – вектор-столбец размерности n значений зависимой переменной Y.
Для решения матричного уравнения (3.9) относительно вектора оценок a * необходимо ввести следующую предпосылку 6 0 (см. п. 2.3, тема 2) для множественного регрессионного анализа:
6 0. Векторы-столбцы матрицы X являются линейно независимыми, т.е.
ранг матрицы X равен (m + 1) – числу неизвестных
параметров: rang (X) = m + 1.
Кроме того, предполагается, что число имеющихся наблюдений n больше числа неизвестных параметров, т.е. n > m + 1, ибо в противном случае в принципе невозможно получение сколь-нибудь надежных статистических выводов.
Из предположения 6 0 следует, что ранг симметричной матрицы X T X, который совпадает с рангом матрицы X, равен ее порядку, т.е. rang (X T X) =
m + 1. Из матричной алгебры известно, что в этом случае матрица X T X является невырожденной, т.е. ее определитель не равен нулю. Следовательно, существует матрица (X T X)– 1, обратная к матрице X T X.
Умножая слева уравнение (3.9) на матрицу (X T X)– 1, получаем
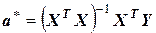 . (3.10)
. (3.10)
Зная вектор а *, выборочное уравнение множественной регрессии можно записать в виде:
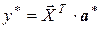 , (3.11)
, (3.11)
где  – вектор-строка значений объясняющих переменных X 1,…, Xm (первая координата, равная единице, соответствует свободному члену).
– вектор-строка значений объясняющих переменных X 1,…, Xm (первая координата, равная единице, соответствует свободному члену).
Пример 3.1. Имеются следующие данные о сменной добыче угля на одного рабочего Y (т), мощности пласта X 1(м) и уровне механизации работ X 2 (%), характеризующие процесс добычи угля в 10 шахтах.
Таблица 3.1
| i | x 1 i | x 2 i | yi | i | x 1 i | x 2 i | yi |
Предполагая, что между переменными Y, X 1 и X 2 существует линейная корреляционная зависимость, найти ее аналитическое выражение (уравнение регрессии Y на X 1 и X 2).
Решение. Обозначим
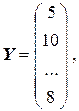
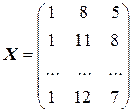
(напомним, что в матрицу X вводится дополнительный столбец чисел, состоящий из единиц). Тогда
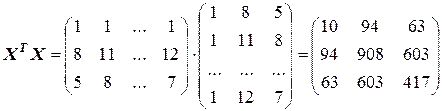
и
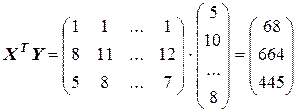 .
.
Матрицу A – 1 = (X T X)– 1 определим по формуле 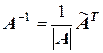 , где
, где 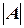 – определитель матрицы
– определитель матрицы 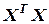 ;
; 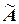 – матрица, присоединенная к матрице .
– матрица, присоединенная к матрице .
Найдем определитель = 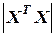 , разложив его по элементам первой строки:
, разложив его по элементам первой строки:
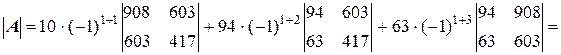
= 10×15027 – 94×1209 + 63×(– 522) = 3 738.
Вычислим алгебраические дополнения 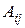 каждого элемента aij матрицы A по формуле:
каждого элемента aij матрицы A по формуле:
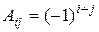 D ij,
D ij,
где D ij – определитель матрицы, полученной из матрицы A вычеркиванием i -й строки и j -го столбца. Например,
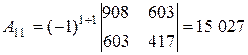 ;
; 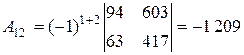 ;
;
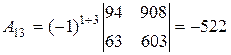 .
.
Составляем присоединенную матрицу
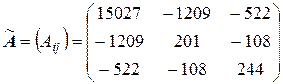
и транспонируем ее:
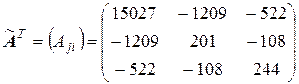 .
.
Отметим, что 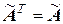 , так как матрица симметричная.
, так как матрица симметричная.
Наконец, получаем
A – 1 = (X T X)– 1 = 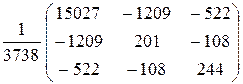 .
.
В соответствии с формулой (3.10), умножая эту матрицу на вектор 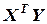 , находим
, находим
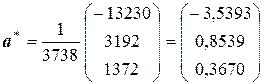 .
.
С учетом (3.6) выборочное уравнение множественной регрессии имеет вид:
y * = – 3,54 + 0,854 x 1 + 0,367 x 2.
Оно показывает, что при увеличении только мощности пласта на 1 м (при неизменном уровне механизации работ) добыча угля на одного рабочего увеличится в среднем на 0,854 т, а при увеличении только уровня механизации работ на 1% (при неизменной мощности пласта) – в среднем на 0,367 т. g

