 2015-05-18
2015-05-18 3028
3028Нелинейные регрессии делятся на два класса: регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, и регрессии, нелинейные по оцениваемым параметрам. Регрессии, нелинейные по объясняющим переменным:
- полиномы разных степеней 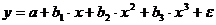
- равносторонняя гипербола 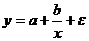 .
.
Регрессии, нелинейные по оцениваемым параметрам:
- степенная 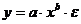
- показательная 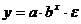
- экспоненциальная 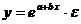
Построение уравнения регрессии сводится к оценке ее параметров. Для оценки параметров регрессий, линейных по параметрам, Используют метод наименьших квадратов (МНК). МНК позволяет получить такие оценки параметров, при которых сумма квадратов отклонений фактических значений результативного признака у от теоретических 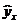 минимальна, т.е.
минимальна, т.е. 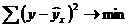 .
.
Для линейных и нелинейных уравнений, приводимых к линейным, решается следующая система относительно a и b:
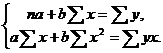
Можно воспользоваться готовыми формулами, которые вытекают из этой системы:
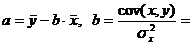
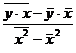
Тесноту связи изучаемых явлений оценивает линейный коэффициент парной корреляции 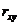 для линейной регрессии
для линейной регрессии 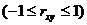 :
:
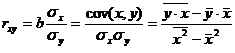
и индекс корреляции 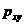 - для нелинейной регрессии
- для нелинейной регрессии 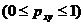 :
:
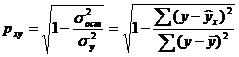
Оценку качества построенной модели даст коэффициент (индекс) детерминации, а также средняя ошибка аппроксимации. Средняя ошибка аппроксимации - среднее отклонение расчетных значений от фактических:
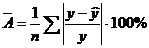 .
.
Допустимый предел значений 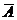 - не более 8-10%.
- не более 8-10%.
Средний коэффициент эластичности 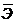 показывает, на сколько процентов в среднем по совокупности изменится результат уот своей средней величины при изменении фактора x на 1% от своего среднего значения:
показывает, на сколько процентов в среднем по совокупности изменится результат уот своей средней величины при изменении фактора x на 1% от своего среднего значения:
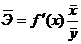 .
.
Задача дисперсионного анализа состоит в анализе дисперсии зависимой переменной:
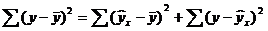 ,
,
где 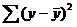 - общая сумма квадратов отклонений;
- общая сумма квадратов отклонений;
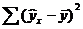 - сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
- сумма квадратов отклонений, обусловленная регрессией («объясненная» или «факторная»);
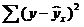 - остаточная сумма квадратов отклонений
- остаточная сумма квадратов отклонений
Долю дисперсии, объясняемую регрессией, в общей дисперсии результативного признака у характеризует коэффициент (индекс) детерминации R2:
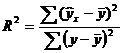
Коэффициент детерминации - квадрат коэффициента или индекса корреляции.
F-тест - оценивание качества уравнения регрессии - состоит в проверке гипотезы Но о статистической незначимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера. Fфакт определяется из соотношения значений факторной и остаточной дисперсий, рассчитанных на одну степень свободы:
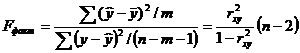 ,
,
где n - число единиц совокупности;
m - число параметров при переменных х.
Fтабл - это максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости a. Уровень значимости a - вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно a принимается равной 0,05 или 0,01.
Если Fтабл< Fфакт, то Но - гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если Fтабл> Fфакт, то гипотеза Но не отклоняется и признается статистическая незначимость, ненадежность уравнения регрессии.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитываются t-критерий Стьюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза Но о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка значимости коэффициентов регрессии и корреляции с помощью t-критерия Стьюдента проводится путем сопоставления их значений с величиной случайной ошибки:
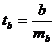 ;
; 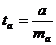 ;
; 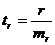 .
.
Случайные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
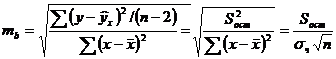
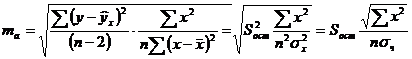

Сравнивая фактическое и критическое (табличное) значения t-статистики - tтабл и tфакт - принимаем или отвергаем гипотезу Но.
Связь между F-критерием Фишера и t-статистикой Стьюдента выражается равенством
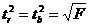
Если tтабл< tфакт то Ho отклоняется, т.е. a, b и не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора х. Если tтабл> tфакт то гипотеза Но не отклоняется и признается случайная природа формирования а, b или .
Для расчета доверительного интервала определяем предельную ошибку D для каждого показателя:
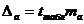 ,
, 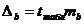 .
.
Формулы для расчета доверительных интервалов имеют следующий вид:
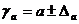 ;
; 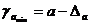 ;
; 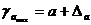
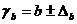 ;
; 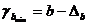 ;
; 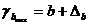
Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается нулевым, так как он не может одновременно принимать и положительное, и отрицательное значения.
Прогнозное значение 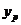 определяется путем подстановки в уравнение регрессии
определяется путем подстановки в уравнение регрессии 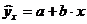 соответствующего (прогнозного) значения
соответствующего (прогнозного) значения 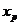 . Вычисляется средняя стандартная ошибка прогноза
. Вычисляется средняя стандартная ошибка прогноза 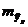 :
:
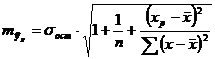 ,
,
где 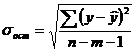
и строится доверительный интервал прогноза:
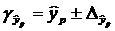 ;
; 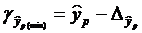 ;
; 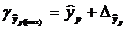 где
где 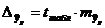 .
.

