2015-05-10
2015-05-10 2252
2252Обобщением линейной и матричной топологий на произвольное число измерений является декартова топология. Для создания коммуникатора с декартовой топологией используется функция MPI_Cart_create. С помощью этой функции можно создавать топологии с произвольным числом измерений, причем по каждому измерению в отдельности можно накладывать периодические граничные условия. Таким образом, для одномерной топологии мы можем получить или линейную структуру, или кольцо - в зависимости от того, какие граничные условия будут наложены. Для двумерной топологии соответственно – либо прямоугольник, либо цилиндр, либо тор. Заметим, что не требуется специальной поддержки гиперкубовой структуры, поскольку она представляет собой n-мерный тор с двумя процессами вдоль каждого координатного направления.
Функция создания коммуникатора с декартовой топологией.
С:
MPI_Cart_create(MPI_Comm comm_old, int ndims, int *dims, int *periods, int reorder, MPI_Comm *comm_cart)
Входные параметры:
| comm_old | - | родительский коммуникатор; |
| ndims | - | число измерений; |
| dims | - | массив размера ndims, в котором задается число процессов вдоль каждого измерения; |
| periods | - | логический массив размера ndims для задания граничных условий (true - периодические, false - непериодические); |
| reorder | - | логическая переменная указывает, производить перенумерацию процессов (true) или нет (false). |
Выходные параметры:
| comm_cart | - | новый коммуникатор. |
Функция является коллективной, т.е. должна запускаться на всех процессах, входящих в группу коммуникатора comm_old. При этом, если какие-то процессы не попадают в новую группу, то для них возвращается результат MPI_COMM_NULL. В случае, когда размеры заказываемой сетки больше имеющегося в группе числа процессов, функция завершается аварийно. Значение параметра reorder=false означает, что идентификаторы всех процессов в новой группе будут такими же, как в старой группе. Если reorder=true, то MPI будет пытаться перенумеровать их с целью оптимизации коммуникаций.
Остальные функции, которые будут рассмотрены в этом разделе, имеют вспомогательный или информационный характер.
Функция определения оптимальной конфигурации сетки.
С:
MPI_Dims_create(int nnodes, int ndims, int *dims)
Входные параметры:
| nnodes | - | общее число узлов в сетке; |
| ndims | - | число измерений; |
| dims | - | массив целого типа размерности ndims, в который помещается рекомендуемое число процессов вдоль каждого измерения |
Выходные параметры:
| dims | - | массив целого типа размерности ndims, в который возвращается число процессов вдоль каждого измерения. |
На входе в процедуру в массив dims должны быть занесены целые неотрицательные числа. Если элементу массива dims[i] присвоено положительное число, то для этой размерности вычисление не производится (число процессов вдоль этого направления считается заданным). Вычисляются только те компоненты dims[i], для которых перед обращением к процедуре были присвоены значения 0. Функция стремится создать максимально равномерное распределение процессов вдоль направлений, выстраивая их по убыванию, т.е. для 12 процессов она построит трехмерную сетку 4 х 3 х 1. Результат работы этой процедуры может использоваться в качестве входного параметра для процедуры MPI_Cart_create.
Функция опроса числа измерений декартовой топологии MPI_Cartdim_get.
С:
MPI_Cartdim_get(MPI_Comm comm, int *ndims)
Входные параметры:
| comm | - | коммуникатор с декартовой топологией. |
Выходные параметры:
| ndim | - | число измерений в декартовой топологии. |
Функция возвращает число измерений в декартовой топологии ndims для коммуникатора comm. Результат может быть использован в качестве параметра для вызова функции MPI_Cart_get, которая служит для получения более детальной информации.
С:
MPI_Cart_get(MPI_Comm comm, int ndims, int *dims, int *periods, int *coords)
Входные параметры:
| comm | - | коммуникатор с декартовой топологией; |
| ndims | - | число измерений. |
Выходные параметры:
| dims | - | массив размера ndims, в котором возвращается число процессов вдоль каждого измерения; |
| periods | - | логический массив размера ndims, в котором возвращаются наложенные граничные условия; (true - периодические, false – непериодические); |
| coords | - | координаты в декартовой сетке вызывающего процесса. |
Две следующие функции устанавливают соответствие между идентификатором процесса и его координатами в декартовой сетке. Под идентификатором процесса понимается его номер в исходной области связи, из которой была создана декартова топология.
Функция получения идентификатора процесса по его координатам MPI_Cart_rank.
С:
MPI_Cart_rank(MPI_Comm comm, int *coords, int *rank)
Входные параметры:
| comm | - | коммуникатор с декартовой топологией; |
| coords | - | координаты в декартовой системе. |
Выходные параметры:
| rank | - | идентификатор процесса. |
Для измерений с периодическими граничными условиями будет выполняться приведение к основной области определения 0 <= coords(i) < dims(i).
Функция определения координат процесса по его идентификатору MPI_Cart_coords.
С:
MPI_Cart_coords(MPI_Comm comm, int rank, int ndims, int *coords)
Входные параметры:
| comm | - | коммуникатор с декартовой топологией; |
| rank | - | идентификатор процесса; |
| ndim | - | число измерений. |
Выходные параметры:
| coords | - | координаты процесса в декартовой топологии. |
Во многих численных алгоритмах используется операция сдвига данных вдоль каких-то направлений декартовой решетки. В MPI существует специальная функция MPI_Cart_shift, реализующая эту операцию. Точнее говоря, сдвиг данных осуществляется с помощью функции MPI_Sendrecv, а функция MPI_Cart_shift вычисляет для каждого процесса параметры для функции MPI_Sendrecv (source и dest).
Функция сдвига данных MPI_Cart_shift.
С:
MPI_Cart_shift(MPI_Comm comm, int direction, int disp, int *rank_source, int *rank_dest)
Входные параметры:
| comm | - | коммуникатор с декартовой топологией; |
| direction | - | номер измерения, вдоль которого выполняется сдвиг; |
| disp | - | величина сдвига (может быть как положительной, так и отрицательной). |
Выходные параметры:
| rank_source | - | номер процесса, от которого должны быть получены данные; |
| rank_dest | - | номер процесса, которому должны быть посланы данные. |
Номер измерения и величина сдвига не обязаны быть одинаковыми для всех процессов. В зависимости от граничных условий сдвиг может быть либо циклический, либо с учетом граничных процессов. В последнем случае для граничных процессов возвращается MPI_PROC_NULL либо для переменной rank_source, либо для rank_dest. Это значение также может быть использовано при обращении к функции MPI_sendrecv.
Другая, часто используемая операция - выделение в декартовой топологии подпространств меньшей размерности и связывание с ними отдельных коммуникаторов.
Функция выделения подпространства в декартовой топологии MPI_Cart_sub.
С:
MPI_Cart_sub(MPI_Comm comm, int *remain_dims, MPI_Comm *newcomm)
Входные параметры:
| comm | - | коммуникатор с декартовой топологией; |
| remain_dims | - | логический массив размера ndims, указывающий, входит ли i-e измерение в новую подрешетку (remain_dims[i] = true). |
Выходные параметры:
| newcomm | - | новый коммуникатор, описывающий подрешетку, содержащую вызывающий процесс. |
Функция является коллективной. Действие функции проиллюстрируем следующим примером. Предположим, что имеется декартова решетка 2 х 3 х 4, тогда обращение к функции MPI_Cart_sub с массивом remain_dims (true, false, true) создаст три коммуникатора с топологией 2 х 4. Каждый из коммуникаторов будет описывать область связи, состоящую из 1/3 процессов, входивших в исходную область связи.
Для определения топологии коммуникатора служит функция MPI_Topo_test.
С:
MPI_Topo_test(MPI_Comm comm, int *status)
Входные параметры:
| comm | - | коммуникатор. |
Выходные параметры:
| status | - | топология коммуникатора. |
Функция MPI_Topo_test возвращает через переменную status топологию коммуникатора comm. Возможные значения:
| MPI_GRAPH | - | топология графа; |
| MPI_CART | - | декартова топология; |
| MPI_UNDEFINED | - | топология не задана. |
-------
Воспользуемся механизмом виртуальных топологий для выполнения следующего задания:
Число процессов К кратно трем: K = 3N, N > 1. В процессах 0, N и 2N дано по N целых чисел. Определить для всех процессов декартову топологию в виде матрицы размера 3 × N, после чего, используя функцию MPI_Cart_sub, расщепить матрицу процессов на три одномерные строки (при этом процессы 0, N и 2N будут главными процессами в полученных строках). Используя одну коллективную операцию пересылки данных, переслать по одному исходному числу из главного процесса каждой строки во все процессы этой же строки и вывести полученное число в каждом процессе (включая процессы 0, N и 2N).
На первом этапе решения задачи необходимо определить требуемую декартову топологию. Для этого надо использовать функцию MPI_Cart_create, которая имеет следующие параметры:
- исходный коммуникатор, для процессов которого определяется декар-това топология (в нашем случае MPI_COMM_WORLD);
- число размерностей создаваемой декартовой решетки (в нашем слу-чае 2);
- целочисленный массив, каждый элемент которого определяет размер по каждому измерению (в нашем случае массив должен состоять из двух элементов со значениями 3 и size / 3);
- целочисленный массив флагов, определяющих периодичность каждого измерения (в нашем случае достаточно использовать массив из двух ну-левых элементов);
- целочисленный флаг, определяющий, можно ли среде MPI автоматиче-ски менять порядок нумерации процессов (в нашем случае необходимо положить этот параметр равным 0);
- результирующий коммуникатор с декартовой топологией (един-ственный выходной параметр).
Периодичность для некоторых измерений декартовой решетки удобно использовать, например, при выполнении циклического переноса данных между процессами, входящими в эти измерения (см. описание функции MPI_Cart_shift); в этом случае соответствующий элемент в массиве флагов надо задать отличным от 0. Автоматическая перенумерация процессов при определении декартовой топологии позволяет учесть физическую конфигурацию компьютерной системы, на которой выполняется параллельная программа, и тем самым повысить эффективность ее выполнения. Однако в учебных программах порядок процессов в созданных декартовых топологиях должен оставаться неизменным, поэтому перенумерацию процессов следует запретить. Приведем фрагмент программы, определяющий декартову топологию и связывающий ее с новым коммуникатором comm:
[C++]:
MPI_Comm comm; int dims[] = {3, size / 3}, periods[] = {0, 0}; MPI_Cart_create(MPI_COMM_WORLD, 2, dims, periods, 0, &comm);
Коммуникатор comm, созданный в результате выполнения функции MPI_Cart_create, будет содержать те же процессы, что и исходный коммуникатор MPI_COMM_WORLD, причем в том же порядке. Однако эти коммуникаторы являются различными. Это проявляется прежде всего в том, что операции пересылки данных, осуществляемые с помощью коммуникаторов MPI_COMM_WORLD и comm, выполняются независимо и не влияют друг на друга (различные коммуникаторы, содержащие один и тот же одинаково упорядоченный набор процессов, называются конгруэнтными; при их сравнении функцией MPI_Comm_compare возвращается результат, равный значению константы MPI_CONGRUENT). Кроме того, с коммуникатором comm дополнительно связана виртуальная топология, а коммуникатор MPI_COMM_WORLD никакой виртуальной топологией не обладает (проверить, связана ли с коммуникатором виртуальная топология определенного типа, можно с помощью функции MPI_Topo_test).
Благодаря наличию декартовой топологии, с каждым процессом коммуникатора comm связывается не только порядковый номер (ранг процесса), но и набор целых чисел, определяющих координаты этого процесса в соответствующей декартовой решетке. Координаты нумеруются от 0. Координаты процесса в декартовой топологии можно определить по его рангу с помощью функции MPI_Cart_coords (заметим, что функция MPI_Cart_rank позволяет решить обратную задачу). Для выполнения нашего задания использовать функцию MPI_Cart_coords не требуется, однако в ряде случаев (в частности, при отладке параллельных программ) она может оказаться полезной. Поэтому приведем пример ее использования, выведя координаты всех процессов, включенных в декартову решетку. Для этого дополним текст программы следующими операторами:
[C++]:
int coords[2]; MPI_Cart_coords(comm, rank, 2, coords); Show(coords[0]); Show(coords[1]);
Вернемся к нашей задаче. Для ее решения необходимо вначале разбить полученную матрицу процессов на отдельные строки, связав с каждой строкой новый коммуникатор. После этого следует выполнить для всех процессов, входящих в одну строку, коллективную операцию MPI_Scatter, рассылающую фрагменты набора данных из одного процесса во все процессы, входящие в коммуникатор. Расщепление декартовой решетки на набор подрешеток меньшей размерности (в частности, разбиение матрицы на набор строк или столбцов) и связывание с каждой полученной подрешеткой нового коммуникатора выполняется с помощью функции MPI_Cart_sub. В качестве ее первого параметра следует указать исходный коммуникатор с декартовой топологией, в качестве второго — массив флагов, определяющий номера тех измерений, которые должны остаться в подрешетках: если соответствующее измерение должно входить в каждую подрешетку, то на его месте в массиве указывается ненулевой флаг, если же по данному измерению выполняется расщепление исходной решетки, то значение связанного с этим измерением флага должно быть нулевым. В результате выполнения функции MPI_Cart_sub создается набор новых коммуникаторов, каждый из которых связывается с одной из полученных подрешеток (все созданные коммуникаторы автоматически снабжаются декартовой топологией). Однако возвращается данной функцией (в качестве третьего, выходного параметра) только один из созданных коммуникаторов — тот, в который входит процесс, вызывавший эту функцию. Заметим, что аналогичным образом ведет себя и функция MPI_Comm_split, рассмотренная в предыдущем пункте. Для разбиения исходной матрицы процессов на набор строк надо в качестве второго параметра функции MPI_Cart_sub указать массив из двух целочис-ленных элементов, первый из которых равен 0, а второй является ненулевым (например, равен 1). В этом случае все элементы матрицы с одинаковым значением первой (удаляемой) координаты будут объединены в новом коммуникаторе (назовем его comm_sub).
Первый процесс каждой строки (тот, который должен по условию задачи переслать свои данные во все остальные процессы этой же строки) будет иметь в полученном коммуникаторе comm_sub ранг, равный 0. Для определения ранга следует воспользоваться функцией MPI_Comm_rank. После этого, если ранг равен 0, надо прочесть исходные данные и переслать по одному элементу данных каждому процессу этого же коммуникатора, используя функцию MPI_Scatter. В конце останется вывести элемент, полученный каждым процессом. Приведем завершающую часть программы:
[C++]
MPI_Comm comm_sub;
int remain_dims[] = {0, 1};
MPI_Cart_sub(comm, remain_dims, &comm_sub);
MPI_Comm_size(comm_sub, &size); MPI_Comm_rank(comm_sub, &rank);
int b, *a = new int[size];
if (rank == 0) for (int i = 0; i < size; ++i)
pt >> a[i];
MPI_Scatter(a, 1, MPI_INT, &b, 1, MPI_INT, 0, comm_sub);
pt << b;
delete[] a;
Приведем полный текст программы:
[C++]:
void Solve() { Task("MPIBegin87");
int flag;
MPI_Initialized(&flag);
if (flag == 0) return;
int rank, size;
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm comm;
int dims[] = {3, size / 3}, periods[] = {0, 0};
MPI_Cart_create(MPI_COMM_WORLD, 2, dims, periods, 0, &comm);
MPI_Comm comm_sub;
int remain_dims[] = {0, 1};
MPI_Cart_sub(comm, remain_dims, &comm_sub);
MPI_Comm_size(comm_sub, &size);
MPI_Comm_rank(comm_sub, &rank);
int b, *a = new int[size];
if (rank == 0) for (int i = 0; i < size; ++i) pt >> a[i];
MPI_Scatter(a, 1, MPI_INT, &b, 1, MPI_INT, 0, comm_sub);
pt << b;
delete[] a;
Теперь рассмотрим другой вид виртуальных топологий — топологию графа.
Следует отметить, что для работы с топологиями графа библиотека MPI предоставляет существенно меньше средств, чем для работы с декартовыми топологиями. Напомним, что для процессов, входящих в декартову топологию, можно определить декартовы координаты по их рангам (и ранги по декартовым координатам); кроме того, предусмотрена возможность выделения подрешеток меньшей размерности (причем каждая подрешетка автоматически связывается с новым коммуникатором). Также имеется специальная функция MPI_Cart_shift, позволяющая определить «соседей» процесса вдоль одной из декартовых координат (использование этой функции упрощает пересылку сообщений вдоль указанной координаты). Что же касается топологии графа, то для нее предусмотрена лишь возможность, аналогичная возможности функции MPI_Cart_Shift, а именно определение количества и рангов всех процессов- соседей (neighbors) некоторого процесса в графе, определяемом данной топологией (соседями считаются процессы, связанные ребрами с данным процессом). Познакомимся с этой возможностью на практике, выполнив следующее задание:
Число процессов K является четным: K = 2N (1 < N < 6); в каждом процессе дано целое число A. Используя функцию MPI_Graph_create, определить для всех процессов топологию графа, в которой все процессы четного ранга (включая главный процесс) связаны в цепочку: 0 — 2 — 4 — 6 — … — (2N − 2), а каждый процесс нечетного ранга R (1, 3, …, 2N − 1) связан с процессом ранга R − 1 (в результате каждый процесс нечетного ранга будет иметь единственного соседа, первый и последний процессы четного ранга будут иметь по два соседа, а остальные — «внутренние» — процессы четного ранга будут иметь по три соседа). Переслать число A из каждого процесса всем процессам-соседям. Для определения количества процессов-соседей и их рангов использовать функции MPI_Graph_neighbors_count и MPI_Graph_neighbors, пересылку выполнять с помощью функции MPI_Sendrecv. Во всех процессах вывести полученные числа в порядке возрастания рангов переславших их процессов.
Для большей наглядности изобразим процессы вместе с их исходными данными в виде графа той структуры, которая описана в формулировке задания (рис. 3).
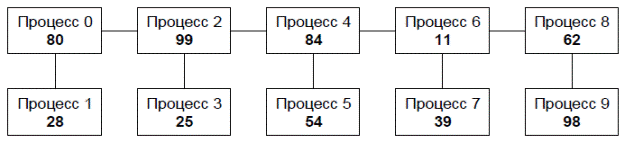
Рис. 3. Топология графа, описанная в задании 17
Поскольку процесс ранга 0 имеет двух соседей (процессы ранга 1 и 2), он должен отправить им число 80 и получить от них числа 28 и 99. Процесс ранга 1 имеет только одного соседа (процесс ранга 0), поэтому он должен отправить ему число 28 и получить от него число 80. Процесс ранга 2, имеющий три соседа, должен отправить им число 99 и получить от них числа 80, 25 и 84, и т. д. Если бы каждый процесс имел информацию о количестве своих соседей, а также об их рангах (в порядке возрастания), то это позволило бы единообразно запрограммировать действия по пересылке данных для любого процесса, независимо от того, сколько соседей он имеет. Требуемая информация о соседях может быть легко получена, если на множестве всех процессов будет определена соответствующая топология графа, а для этого необходимо воспользоваться функцией MPI_Graph_create. Данная функция имеет следующие параметры:
- исходный коммуникатор, для процессов которого определяется топология графа;
- число вершин графа;
- целочисленный массив степеней вершин, i-й элемент которого равен суммарному количеству соседей для первых i вершин графа;
- целочисленный массив ребер, содержащий упорядоченный список ребер для всех вершин (вершины нумеруются от 0);
- целочисленный флаг, определяющий, можно ли среде MPI автоматически менять порядок нумерации процессов;
- результирующий коммуникатор с топологией графа (единственный выходной параметр).
Как и при выполнении предыдущего задания, следует запретить перенумерацию процессов, положив соответствующей флаг равным 0.
Чтобы лучше понять смысл параметров-массивов, задающих характеристики определяемого графа, перечислим их элементы для графа, приведенного на рисунке 3. Первая вершина графа (процесс ранга 0) имеет двух соседей, поэтому первый элемент массива степеней вершин будет равен 2. Вторая вершина графа (процесс ранга 1) имеет одного соседа, поэтому второй элемент массива степеней вершин будет равен 3 (к значению предыдущего элемента прибавляется 1). Третья вершина (процесс ранга 2) имеет трех соседей, поэтому третий элемент массива степеней вершин будет равен 6, и т. д. Получаем следующий набор значений: 2, 3, 6, 7, 10, 11, 14, 15, 17, 18 (предпоследний элемент массива равен 17, так как процесс ранга 8, как и процесс ранга 0, имеет двух соседей). Заметим, что значение последнего элемента массива степеней вершин всегда будет в два раза больше общего количества ребер графа. В массиве ребер необходимо указать ранги всех соседей для каждой вершины (для большей наглядности будем выделять группы соседей каждой вершины дополнительными пробелами, а сверху в скобках указывать ранг вершины, соседи которой перечислены ниже):
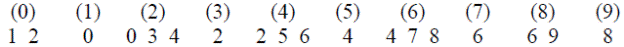
Размер полученного массива ребер равен значению последнего элемента массива степеней вершин. Если число процессов равно size, то массив степеней вершин должен содержать size элементов. Размер массива ребер зависит от структуры графа; в нашем случае размер массива ребер равен 2·(size – 1), где size — число процессов. При заполнении массивов удобно отдельно обработать фрагменты, соответствующие двум первым (ранга 0 и 1) и двум последним (ранга size – 2 и size – 1) вершинам графа, а остальные вершины перебирать в цикле, обрабатывая по две вершины (ранга 2 и 3, 4 и 5, …, size – 4 и size – 3) на каждой итерации. Следуя описанию функции MPI_Graph_create в стандарте MPI [6], будем использовать для массива степеней вершин и массива ребер названия index и edges соответственно. При заполнении этих массивов удобно использовать вспомогательную переменную n, равную половине количества процессов. Приведем фрагмент программы, заполняющей массивы index и edges:
[C++]:
int n = size / 2;
int *index = new int[size], *edges = new int[2 * (size – 1)];
index[0] = 2;
index[1] = 3;
edges[0] = 1;
edges[1] = 2;
edges[2] = 0;
int j = 3;
for (int i = 1; i <= n - 2; ++i) { index[2 * i] = index[2 * i - 1] + 3; edges[j] = 2 * i - 2; edges[j + 1] = 2 * i + 1;
edges[j + 2] = 2 * i + 2;
index[2 * i + 1] = index[2 * i] + 1; edges[j + 3] = 2 * i;
j += 4;
}
index[2 * n - 2] = index[2 * n - 3] + 2;
index[2 * n - 1] = index[2 * n - 2] + 1;
edges[j] = 2 * n - 4;
edges[j + 1] = 2 * n - 1;
edges[j + 2] = 2 * n - 2;
Для проверки правильности данной части алгоритма выведем значения элементов полученных массивов:
[C++]
for (int i = 0; i < size; ++i) Show(index[i]);
ShowLine();
for (int i = 0; i < j + 3; ++i) Show(edges[i]);
Убедившись, что массивы сформированы правильно, создадим топологию графа, вызвав функцию MPI_Graph_create в каждом процессе параллельного приложения:
[C++]
MPI_Comm g_comm;
MPI_Graph_create(MPI_COMM_WORLD, size, index, edges, 0, &g_comm);
Осталось реализовать завершающую часть алгоритма, непосредственно связанную с пересылкой данных. В этой части для текущего процесса (процесса ранга rank) следует определить количество count его соседей и массив neighbors их рангов в текущей топологии графа (используя функции MPI_Graph_neighbors_count и MPI_Graph_neighbors), после чего организовать обмен данными между текущим процессом и каждым из его соседей (согласно формулировке задания для этого надо использовать функцию MPI_Sendrecv, которая обеспечивает как прием сообщения от некоторого процесса, так и отправку ему другого сообщения). Приведем завершающую часть программы:
[C++]
int count;
MPI_Graph_neighbors_count(g_comm, rank, &count);
int *neighbors = new int[count];
MPI_Graph_neighbors(g_comm, rank, count, neighbors);
int a, b;
MPI_Status s;
pt >> a;
for (int i = 0; i < count; ++i)
{
MPI_Sendrecv(&a, 1, MPI_INT, neighbors[i], 0, &b, 1, MPI_INT, neighbors[i], 0, g_comm, &s);
pt << b;
}
delete[] index;
delete[] edges;
delete[] neighbors;
Задание
Разработать параллельную программу на C++, реализующую заданную операцию пересылки в соответствии с заданной в варианте виртуальной топологией процессов. Номер варианта задания соответствует номеру по журналу группы. Если количество процессов в задании не определено, то можно считать, что это количество не превосходит 12. Под главным процессом всюду в формулировках заданий понимается процесс ранга 0 для коммуникатора MPI_COMM_WORLD. Для всех процессов ненулевого ранга в заданиях используется общее наименование подчиненных процессов. Если в задании не указан тип обрабатываемых чисел, то числа считаются вещественными. Если в задании не определяется максимальный размер набора чисел, то его следует считать равным 10.
Варианты заданий
1. В главном процессе дано целое число N (> 1), причем известно, что количество процессов K делится на N. Переслать число N во все процессы, после чего, используя функцию MPI_Cart_create, определить для всех процессов декартову топологию в виде двумерной решетки — матрицы размера N × K / N (порядок нумерации процессов оставить прежним). Используя функцию MPI_Cart_coords, вывести для каждого процесса его координаты в созданной топологии.
2. В главном процессе дано целое число N (> 1), не превосходящее количества процессов K. Переслать число K во все процессы, после чего определить декартову топологию для начальной части процессов в виде двумерной решетки — матрицы размера N × K / N (символ «/» обозначает операцию деления нацело, порядок нумерации процессов следует оставить прежним). Для каждого процесса, включенного в декартову топологию, вывести его координаты в этой топологии.
3. Число процессов К является четным: K = 2 N, N > 1. В процессах 0 и N дано по одному вещественному числу A. Определить для всех процес-сов декартову топологию в виде матрицы размера 2 × N, после чего, ис-пользуя функцию MPI_Cart_sub, расщепить матрицу процессов на две од-номерные строки (при этом процессы 0 и N будут главными процессами в полученных строках). Используя одну коллективную операцию пересылки данных, переслать число A из главного процесса каждой строки во все процессы этой же строки и вывести полученное число в каждом процессе (включая процессы 0 и N).
4. Число процессов К является четным: K = 2N, N > 1. В процессах 0 и 1 дано по одному вещественному числу A. Определить для всех процес-сов декартову топологию в виде матрицы размера N × 2, после чего, ис-пользуя функцию MPI_Cart_sub, расщепить матрицу процессов на два од-номерных столбца (при этом процессы 0 и 1 будут главными процессами в полученных столбцах). Используя одну коллективную операцию пересыл-ки данных, переслать число A из главного процесса каждого столбца во все процессы этого же столбца и вывести полученное число в каждом процессе (включая процессы 0 и 1).
5. Число процессов К кратно трем: K = 3N, N > 1. В процессах 0, N и 2N дано по N целых чисел. Определить для всех процессов декартову то-пологию в виде матрицы размера 3 × N, после чего, используя функцию MPI_Cart_sub, расщепить матрицу процессов на три одномерные строки (при этом процессы 0, N и 2N будут главными процессами в полученных строках). Используя одну коллективную операцию пересылки данных, пе-реслать по одному исходному числу из главного процесса каждой строки во все процессы этой же строки и вывести полученное число в каждом процессе (включая процессы 0, N и 2N).
6. Число процессов К кратно трем: K = 3N, N > 1. В процессах 0, 1 и 2 дано по N целых чисел. Определить для всех процессов декартову то-пологию в виде матрицы размера N × 3, после чего, используя функцию MPI_Cart_sub, расщепить матрицу процессов на три одномерных столбца (при этом процессы 0, 1 и 2 будут главными процессами в полученных столбцах). Используя одну коллективную операцию пересылки данных, переслать по одному исходному числу из главного процесса каждого столбца во все процессы этого же столбца и вывести полученное число в каждом процессе (включая процессы 0, 1 и 2).
7. Количество процессов K равно 8 или 12, в каждом процессе дано целое число. Определить для всех процессов декартову топологию в виде трехмерной решетки размера 2 × 2 × K/4 (порядок нумерации процессов оставить прежним). Интерпретируя эту решетку как две матрицы размера 2 × K/4 (в одну матрицу входят процессы с одинаковой первой координа-той), расщепить каждую матрицу процессов на две одномерные строки. Используя одну коллективную операцию пересылки данных, переслать в главный процесс каждой строки исходные числа из процессов этой же строки и вывести полученные наборы чисел (включая числа, полученные из главных процессов строк).
8. Количество процессов K равно 8 или 12, в каждом процессе дано целое число. Определить для всех процессов декартову топологию в виде трехмерной решетки размера 2 × 2 × K/4 (порядок нумерации процессов оставить прежним). Интерпретируя полученную решетку как K/4 матриц размера 2 × 2 (в одну матрицу входят процессы с одинаковой третьей ко-ординатой), расщепить эту решетку на K/4 указанных матриц. Используя одну коллективную операцию пересылки данных, переслать в главный процесс каждой из полученных матриц исходные числа из процессов этой же матрицы и вывести полученные наборы чисел (включая числа, полу-ченные из главных процессов матриц).
9. Количество процессов K равно 8 или 12, в каждом процессе дано вещественное число. Определить для всех процессов декартову топологию в виде трехмерной решетки размера 2 × 2 × K/4 (порядок нумерации про-цессов оставить прежним). Интерпретируя эту решетку как две матрицы размера 2 × K/4 (в одну матрицу входят процессы с одинаковой первой ко-ординатой), расщепить каждую матрицу процессов на K/4 одномерных столбцов. Используя одну коллективную операцию редукции, для каждого столбца процессов найти произведение исходных чисел и вывести найден-ные произведения в главных процессах каждого столбца.
10. Количество процессов K равно 8 или 12, в каждом процессе дано вещественное число. Определить для всех процессов декартову топологию в виде трехмерной решетки размера 2 × 2 × K/4 (порядок нумерации про-цессов оставить прежним). Интерпретируя полученную решетку как K/4 матриц размера 2 × 2 (в одну матрицу входят процессы с одинаковой третьей координатой), расщепить эту решетку на K/4 указанных матриц. Используя одну коллективную операцию редукции, для каждой из полу-ченных матриц найти сумму исходных чисел и вывести найденные суммы в каждом процессе соответствующей матрицы.
11. В главном процессе даны положительные целые числа M и N, произведение которых не превосходит количества процессов; кроме того, в процессах с рангами от 0 до M·N − 1 даны целые числа X и Y. Переслать числа M и N во все процессы, после чего определить для начальных M·N процессов декартову топологию в виде двумерной решетки размера M × N, являющейся периодической по первому измерению (порядок нуме-рации процессов оставить прежним). В каждом процессе, входящем в соз-данную топологию, вывести ранг процесса с координатами X, Y (с учетом периодичности), используя для этого функцию MPI_Cart_rank. В случае недопустимых координат вывести −1.
12.. В главном процессе даны положительные целые числа M и N, произведение которых не превосходит количества процессов; кроме того, в процессах с рангами от 0 до M·N − 1 даны целые числа X и Y. Переслать числа M и N во все процессы, после чего определить для начальных M·N процессов декартову топологию в виде двумерной решетки размера M × N, являющейся периодической по второму измерению (порядок нуме-рации процессов оставить прежним). В каждом процессе, входящем в соз-данную топологию, вывести ранг процесса с координатами X, Y (с учетом периодичности), используя для этого функцию MPI_Cart_rank. В случае недопустимых координат вывести −1.
13. В каждом подчиненном процессе дано вещественное число. Оп-ределить для всех процессов декартову топологию в виде одномерной ре-шетки и осуществить простой сдвиг исходных данных с шагом −1 (число из каждого подчиненного процесса пересылается в предыдущий процесс). Для определения рангов посылающих и принимающих процессов исполь-зовать функцию MPI_Cart_shift, пересылку выполнять с помощью функций MPI_Send и MPI_Recv. Во всех процессах, получивших данные, вывести эти данные.
14. Число процессов К является четным: K = 2N, N > 1; в каждом процессе дано вещественное число A. Определить для всех процессов де-картову топологию в виде матрицы размера 2 × N (порядок нумерации процессов оставить прежним) и для каждой строки матрицы осуществить циклический сдвиг исходных данных с шагом 1 (число A из каждого про-цесса, кроме последнего в строке, пересылается в следующий процесс этой же строки, а из последнего процесса — в главный процесс этой строки). Для определения рангов посылающих и принимающих процессов исполь-зовать функцию MPI_Cart_shift, пересылку выполнять с помощью функции MPI_Sendrecv. Во всех процессах вывести полученные данные.
15. Количество процессов K равно 8 или 12, в каждом процессе дано вещественное число. Определить для всех процессов декартову топологию в виде трехмерной решетки размера 2 × 2 × K/4 (порядок нумерации про-цессов оставить прежним). Интерпретируя полученную решетку как K/4 матриц размера 2 × 2 (в одну матрицу входят процессы с одинаковой третьей координатой, матрицы упорядочены по возрастанию третьей коор-динаты), осуществить циклический сдвиг исходных данных из процессов каждой матрицы в соответствующие процессы следующей матрицы (из процессов последней матрицы данные перемещаются в первую матрицу). Для определения рангов посылающих и принимающих процессов исполь-зовать функцию MPI_Cart_shift, пересылку выполнять с помощью функции MPI_Sendrecv_replace. Во всех процессах вывести полученные данные.
16. Число процессов K является нечетным: K = 2N + 1 (1 < N < 5); в каждом процессе дано целое число A. Используя функцию MPI_Graph_create, определить для всех процессов топологию графа, в ко-торой главный процесс связан ребрами со всеми процессами нечетного ранга (1, 3, …, 2N − 1), а каждый процесс четного положительного ранга R (2, 4, …, 2N) связан ребром с процессом ранга R − 1 (в результате получается N-лучевая звезда, центром которой является главный процесс, а каж-дый луч состоит из двух подчиненных процессов R и R + 1, причем бли-жайшим к центру является процесс нечетного ранга R). Переслать число A из каждого процесса всем процессам, связанным с ним ребрами (процессам-соседям). Для определения количества процессов-соседей и их рангов использовать функции MPI_Graph_neighbors_count и MPI_Graph_neighbors, пересылку выполнять с помощью функций MPI_Send и MPI_Recv. Во всех процессах вывести полученные числа в порядке возрастания рангов пере-славших их процессов.
17. Число процессов K является четным: K = 2N (1 < N < 6); в каждом процессе дано целое число A. Используя функцию MPI_Graph_create, определить для всех процессов топологию графа, в которой все процессы четного ранга (включая главный процесс) связаны в цепочку: 0 — 2 — 4 — 6 — … — (2N − 2), а каждый процесс нечетного ранга R (1, 3, …, 2N − 1) связан с процессом ранга R − 1 (в результате каждый процесс нечетного ранга будет иметь единственного соседа, первый и последний процессы четного ранга будут иметь по два соседа, а остальные — «внутренние» — процессы четного ранга будут иметь по три соседа). Переслать число A из каждого процесса всем процессам-соседям. Для определения количества процессов-соседей и их рангов использовать функции MPI_Graph_neighbors_count и MPI_Graph_neighbors, пересылку выполнять с помощью функции MPI_Sendrecv. Во всех процессах вывести полученные числа в порядке возрастания рангов переславших их процессов.
18. Количество процессов K равно 3N + 1 (1 < N < 5); в каждом процессе дано целое число A. Используя функцию MPI_Graph_create, определить для всех процессов топологию графа, в которой процессы R, R + 1, R + 2, где R = 1, 4, 7, …, связаны между собой ребрами, и, кроме того, каждый процесс положительного ранга, кратного трем (3, 6, …), связан ребром с главным процессом (в результате получается N-лучевая звезда, центром которой является главный процесс, а каждый луч состоит из трех связанных между собой процессов, причем с центром связан процесс ранга, кратного трем). Переслать число A из каждого процесса всем процессам-соседям. Для определения количества процессов-соседей и их рангов использовать функции MPI_Graph_neighbors_count и MPI_Graph_neighbors, пересылку выполнять с помощью функции MPI_Sendrecv. Во всех процессах вывести полученные числа в порядке возрастания рангов переславших их процессов.
Содержание отчета
Титульный лист
Цель
Задание
Графическое представление исходной и результирующей топологий
Листинг программы
Исходные данные
Контрольный просчет
Скриншоты с результатами и отладочными печатями.
Анализ результатов
Литература
1. М. Э. Абрамян. Практикум по параллельному программированию с использованием технологии MPI. Ростов-на-Дону. 2011
2. Антонов А. С. Параллельное программирование с использованием технологии MPI. — М.: Изд-во МГУ, 2004. — 71 с.
2. Букатов А. А., Дацюк В. Н., Жегуло А. Н. Программирование для мно-гопроцессорных вычислительных систем. — Ростов н/Д: ЦВВР, 2003. — 208 с.
3. Корнеев В. Д. Параллельное программирование в MPI. — Новосибирск: Изд-во ИВМиМГ СО РАН, 2002. — 215 с.
4. Немнюгин С. А., Стесик О. Л. Параллельное программирование для многопроцессорных вычислительных систем. — СПб: БХВ–Петербург, 2002. — 396 с.
5. Шпаковский Г. И., Серикова Н. В. Программирование для многопроцессорных систем в стандарте MPI. — Минск: БГУ, 2002. — 323 с.
6. Message Passing Interface Forum. MPI: A message-passing interface stan-dard. International Journal of Supercomputer Applications, 8 (3/4), 1994. Special issue on MPI.