2015-05-10
2015-05-10 594
594Лабораторная работа №5
Вводные замечания. Результаты, полученные по всем задачам, предлагаемым для решения репрезентативной выборке испытуемых, могут быть включены в психометрический тест лишь после первичной их обработки. Под первичной обработкой в психометрике понимается расчет первичных данных, или "сырых" баллов, определение индексов трудности задач относительно той популяции испытуемых, для которой данный тест предназначен.
После сбора всех протоколов исследования в первую очередь необходимо определить принадлежность решения каждой задачи к одной из четырех возможных категорий:
- правильный ответ (п) - ответ, соответствующий концепту задачи (это относится и к опросникам);
- неправильный ответ (н) - ответ, противоречащий концепту задачи;
- пропущенная из-за невнимательности, субъективной трудности задача (а);
- нерешенная из-за ограничений времени задача (б).
Таким образом, первичный, или "сырой", результат исследования для каждого испытуемого представляет собой п+н+а+б = n, где n - общее количество задач в тесте. Поскольку данное выражение относится ко всем испытуемым репрезентативной выборки (N) и может служить для контроля правильности обработки протоколов, то можно записать
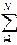 п + н + а + б = N n
п + н + а + б = N n
Наиболее простой способ получения первичного результата Х для отдельного испытуемого состоит в присвоении каждому правильному ответу или ответу, соответствующему концепту вопроса или задачи, одного балла. Тогда первичный результат испытуемого определяется как Х=п. Довольно часто при расчете первичного результата учитывается и количество неправильных ответов, например, когда нас интересует качество работы испытуемых или ошибки представляют диагностическую ценность. Тогда первичный результат вычисляем как Х=п-н. Иногда отдельным ошибочным ответам целесообразно присваивать весовые коэффициенты, например, зависимости от трудности задачи, и тогда первичный результат определяется как Х=п- k н (где k - весовой коэффициент). В качестве коэффициентов чаще применяется дробная часть целого балла, например 2/3, 1/5, 1/3 и т. п. Реже, хотя и это допустимо, используют величины, кратные целому баллу (например 2, 3, 5).
Для контроля и проверки правильности проведения первичной обработки результатов исследования рекомендуется составить сводную таблицу данных. После составления сводной таблицы и подсчета первичных результатов можно приступить к анализу задач теста (или пунктов опросника), который предполагает, в частности, определение статистического показателя для каждой задачи - индекса трудности и коэффициента дискриминативности.
Индекс трудности задачи (Ит), равен проценту правильных ответов на данную задачу (N п), вычисляемому с учетом объема репрезентативной выборки испытуемых (N):
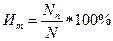 (1)
(1)
Необходимо отметить, что чем меньше значение Ит, тем статистическая трудность задачи выше. Оптимальными для теста являются задачи, индекс трудности которых равен 50%.
Статистическую значимость различий между индексами трудности двух задач быстрее всего можно оценить с помощью критерия χ2 Мак-Немары:
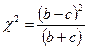 (2)
(2)
где b - количество испытуемых, правильно решивших обе сравниваемые задачи, с - количество испытуемых, правильно решивших только вторую задачу.
Второй статистический показатель - коэффициент дискриминативности, или согласованности, отдельной задачи с тестом - позволяет оценить, насколько точно задача дифференцирует испытуемых по измеряемому признаку. Он равен коэффициенту корреляции между результатом анализируемой задачи (по принципу правильный - неправильный ответ) и средним первичным результатом по всем задачам теста. Следует обратить внимание на то, что обычные меры корреляции, традиционно применяемые в психологии, для расчета коэффициента дискриминативности непригодны. Дело в том, что при его расчете необходимо коррелировать величины, из которых одна имеет дихотомическое распределение, а вторая - непрерывное. Поэтому среди множества известных коэффициентов корреляции наиболее точной мерой оказался коэффициент точечно-бисериальной корреляции (rpb). Наряду с этим коэффициентом, расчет которого вручную является делом трудоемким, для расчета коэффициента дискриминативности можно использовать бисериальный и тетрахорический коэффициенты корреляции.
Цель занятия. Усвоение приемов вычисления индекса трудности.
Оснащение. Микрокалькулятор, таблица с исходными данными, бумага и карандаш для промежуточных вычислений.
Порядок работы. Расчеты выполняются студентами учебной группы самостоятельно, преподаватель консультирует и контролирует правильность выполнения задания.