 2015-05-30
2015-05-30 3487
3487Лекция 4. Моделирование и принятие решений в ГИС.
1. Нечеткие множества
2. Методы оптимизации
Нечеткие множества
Наиболее поразительным свойством человеческого интеллекта является способность принимать правильные решения в обстановке неполной и нечеткой информации. Построение моделей приближенных рассуждений человека и использование их в компьютерных системах представляет сегодня одну из важных задач развития ГИС, особенно по применению их в различных сферах управления.
Значительное продвижение в этом направлении сделано 30 лет тому назад про- ром Калифорнийского университета (Беркли) Лотфи А. Заде. Его работа «Fuzzy Sets», появившаяся в 1965 г. в журнале Information and Control, №8, заложила основы моделирования интеллектуальной деятельности человека и явилась начальным толчком к развитию новой математической теории.
Что же предложил Заде? Во-первых, он расширил классическое канторовское понятиемножества, допустив, что характеристическая функция (функция принадлежности элемента множеству) может принимать любые значения в интервале (0,1)), а не как в классической теории только значения 0 либо 1. Такие множества были названынечеткими(fuzzy).
Им были также определены операции над нечеткими множествами и предложены обобщения известных методов логического вывода.
Рассмотрим некоторые основные положения теории нечетких множеств.
Пусть Е - универсальное множество, х - элемент Е, а К - некоторое свойство. Обычное (четкое) подмножество А универсального множества Е, элементы которого удовлетворяют свойству R, определяется как множество упорядоченных пар 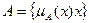 , где
, где 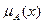 - характеристическая функция, принимающая значение 1, если х удовлетворяет свойству R, и 0 - в противном случае.
- характеристическая функция, принимающая значение 1, если х удовлетворяет свойству R, и 0 - в противном случае.
Нечеткое подмножество отличается от обычного тем, что для элементов х из Е нет однозначного ответа «да - нет» относительно свойства R. В связи с этим нечеткое подмножество А универсального множества Е определяется как множество упорядоченных пар , где - характеристическая функция принадлежности (или просто функция принадлежности), принимающая значения в некотором вполне упорядоченном множестве М (например, М = [0,1]). Функция принадлежности указывает степень (или уровень) принадлежности элемента х подмножеству А. Множество М называют множеством принадлежностей. Если М = {0,1}, то нечеткое подмножество А может рассматриваться как обычное или четкое множество.
Пусть М = [0, 1] и А - нечеткое множество с элементами из универсального множества Е и множеством принадлежностей М.
Величина 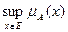 называется высотой нечеткого множества А. Нечеткое множество А нормально, если его высота равна 1, т. е. верхняя граница его функции принадлежности равна 1 ( =1). При < 1 нечеткое множество называется субнормальным.
называется высотой нечеткого множества А. Нечеткое множество А нормально, если его высота равна 1, т. е. верхняя граница его функции принадлежности равна 1 ( =1). При < 1 нечеткое множество называется субнормальным.
Нечеткое множество пусто, если 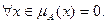 Непустое субнормальное множество можно нормализовать по формуле
Непустое субнормальное множество можно нормализовать по формуле 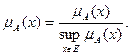
В приведенных выше примерах использованы прямые методы, когда эксперт либо просто задает для каждого 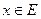 значение , либо определяет функцию совместимости. Как правило, прямые методы задания функции принадлежности используются для измеримых понятий, таких как скорость, время, расстояние, давление, температура и т. д., или когда выделяются полярные значения.
значение , либо определяет функцию совместимости. Как правило, прямые методы задания функции принадлежности используются для измеримых понятий, таких как скорость, время, расстояние, давление, температура и т. д., или когда выделяются полярные значения.
Косвенные методы определения значений функции принадлежности используются в случаях, когда нет элементарных измеримых свойств, через которые определяется интересующее нас нечеткое множество. Как правило, это методы попарных сравнений. Если бы значения функций принадлежности были нам известны, например 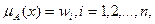 то попарные сравнения можно представить матрицей отношений
то попарные сравнения можно представить матрицей отношений 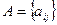 , где
, где 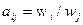 (операция деления).
(операция деления).
На практике эксперт сам формирует матрицу А, при этом предполагается, что диагональные элементы равны 1, а для элементов, симметричных относительно диагонали, 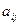 =1/ , т. е. если один элемент оценивается в а раз выше чем другой, то этот последний должен быть в 1/
=1/ , т. е. если один элемент оценивается в а раз выше чем другой, то этот последний должен быть в 1/ 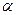 раз сильнее. В общем случае задача сводится к поиску вектора
раз сильнее. В общем случае задача сводится к поиску вектора 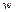 , удовлетворяющего уравнению вида
, удовлетворяющего уравнению вида 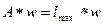 , где
, где 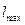 - наибольшее собственное значение матрицы А.
- наибольшее собственное значение матрицы А.
Введение понятия лингвистической переменной, и допущение, что в качестве ее значений (термов) выступают нечеткие множества, фактически позволяет создать аппарат описания процессов интеллектуальной деятельности, включая нечеткость и неопределенность выражений.
Поскольку матрица А положительно-определенная по построению, решение данной задачи существует при принятом значении (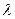 ) и является положительным.
) и является положительным.
Нечеткая переменная характеризуется тройкой < , X, А>, где
- наименование переменной;
X - универсальное множество (область определения а);
А - нечеткое множество на X, описывающее ограничения (т. е, 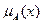 ) на значения нечеткой переменной .
) на значения нечеткой переменной .
Лингвистической переменной называется набор < 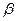 , Т, X, G, М>, где
, Т, X, G, М>, где
- наименование лингвистической переменной;
Т - множество ее значений (терм-множество), представляющих собой наименования нечетких переменных, областью определения каждой из которых является множество X. Множество Т называется базовым терм-множеством лингвистической переменной;
G - синтаксическая процедура, позволяющая оперировать элементами терм- множества Т, в частности генерировать новые термы (значения). Множество Т 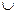 С(Т), где С(Т) - множество сгенерированных термов, называется расширенным терм-множеством лингвистической переменной;
С(Т), где С(Т) - множество сгенерированных термов, называется расширенным терм-множеством лингвистической переменной;
М - семантическая процедура, позволяющая превратить каждое новое значение лингвистической переменной, образуемое процедурой С, в нечеткую переменную, т. е. сформировать соответствующее нечеткое множество.
Введя понятие лингвистической переменной и допуская, что в качестве ее значений (термов) выступают нечеткие множества, фактически позволяет создать аппарат описания процессов интеллектуальной деятельности, включая нечеткость и неопределенность выражений.

